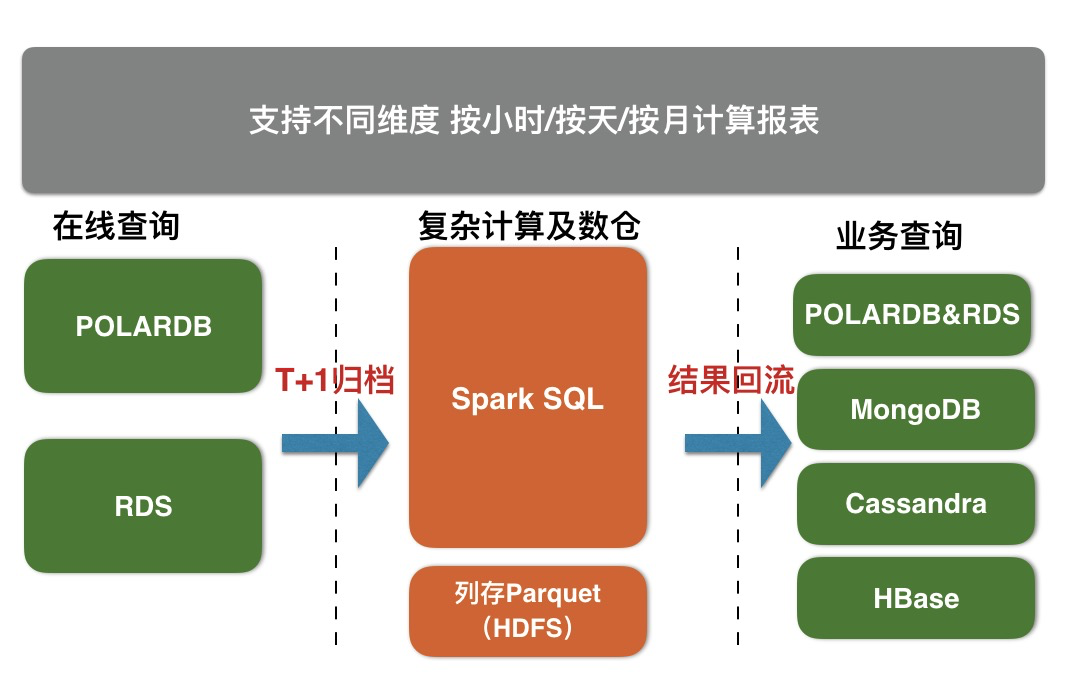
X-Pack Spark服务通过外部计算资源的方式,为Redis、Cassandra、MongoDB、HBase、RDS存储服务提供复杂分析、流式处理及入库、机器学习的能力,从而更好的解决用户数据处理相关场景问题。
RDS & POLARDB分表归档到X-Pack Spark步骤
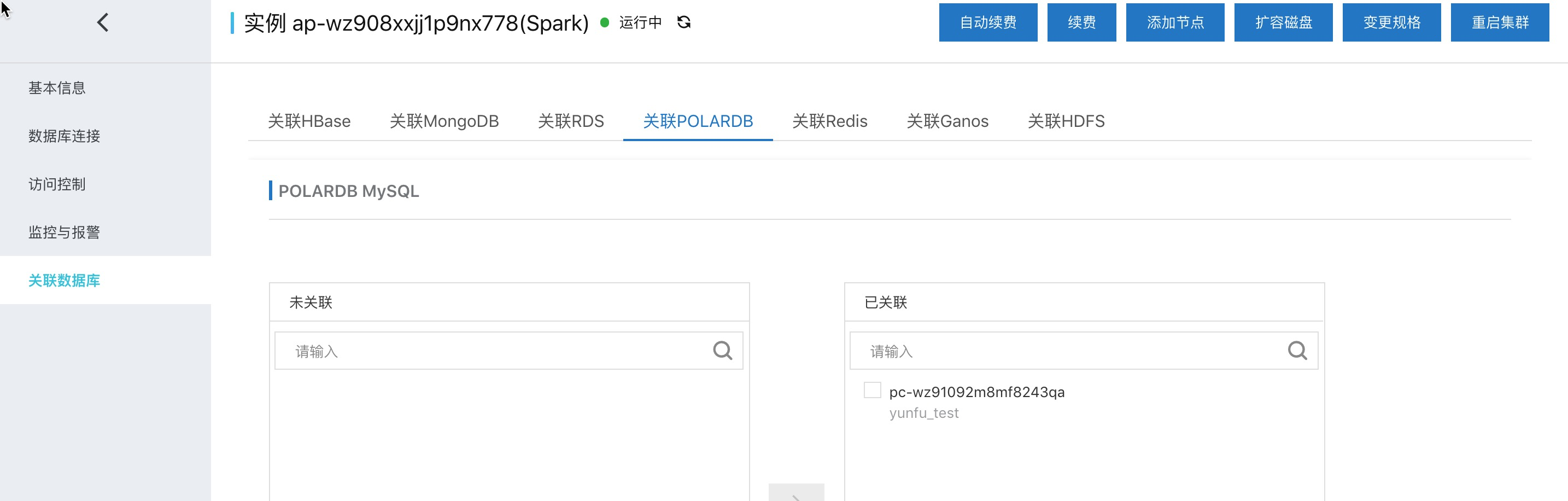
一键关联POLARDB到Spark集群
一键关联主要是做好spark访问RDS & POLARDB的准备工作。
POLARDB表存储
在database ‘test1’中每5分钟生成一张表,这里假设为表 'test1'、'test2'、'test2'、...
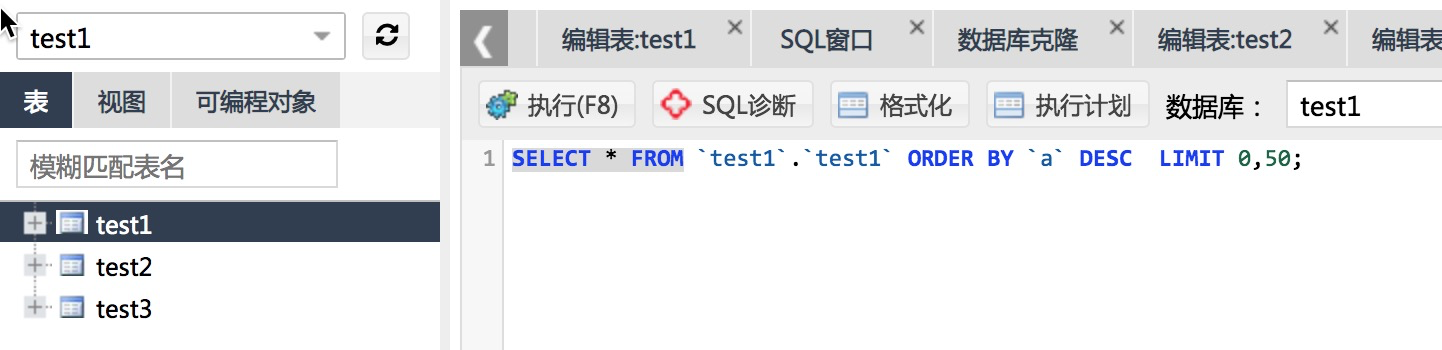
具体的建表语句如下:
CREATE TABLE `test1` ( `a` int(11) NOT NULL,
`b` time DEFAULT NULL,
`c` double DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
归档到Spark的调试
x-pack spark提供交互式查询模式支持直接在控制台提交sql、python脚本、scala code来调试。
1、首先创建一个交互式查询的session,在其中添加mysql-connector的jar包。
wget https://spark-home.oss-cn-shanghai.aliyuncs.com/spark_connectors/mysql-connector-java-5.1.34.jar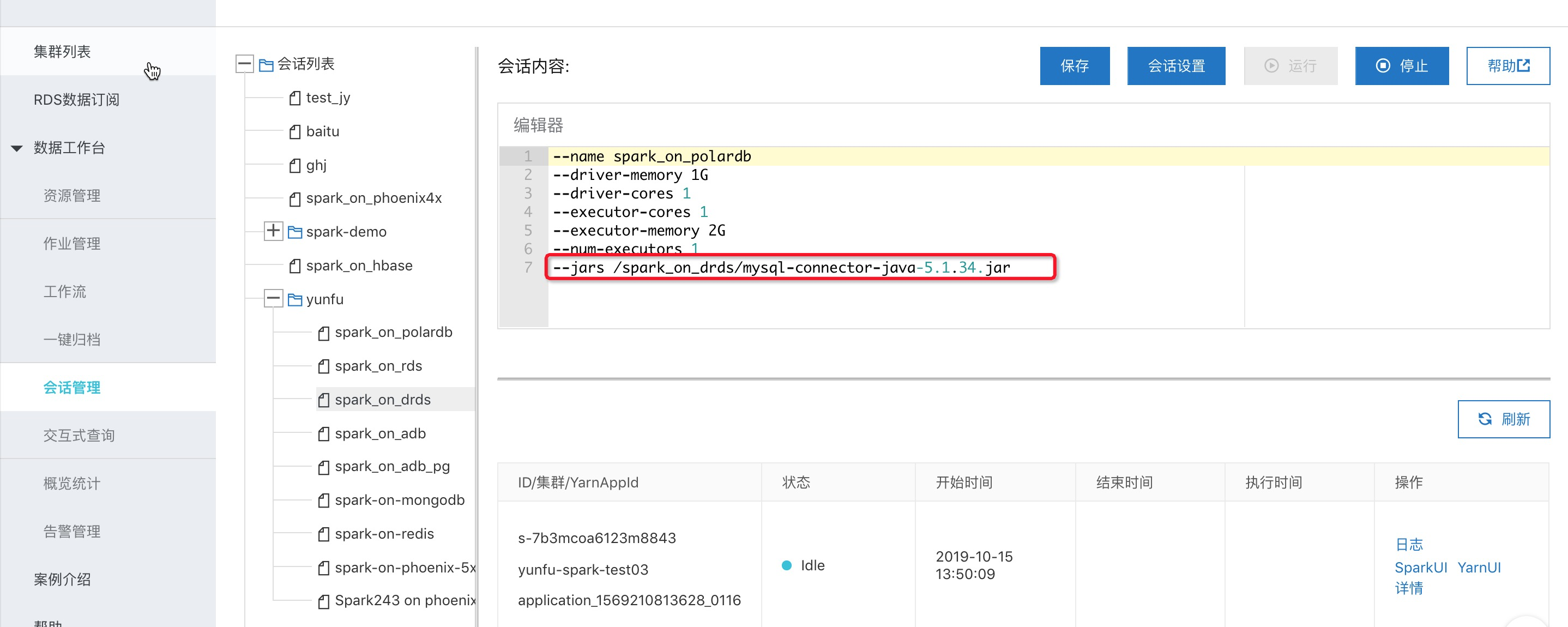
2、创建交互式查询
以pyspark为例,下面是具体归档demo的代码:
spark.sql("drop table sparktest").show()
# 创建一张spark表,三级分区,分别是天、小时、分钟,最后一级分钟用来存储具体的5分钟的一张polardb表达的数据。字段和polardb里面的类型一致
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb里面创建了databse test1,具有三张表test1 ,test2,test3,这里遍历这三张表,每个表存储spark的一个5min的分区
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#构造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表关联polardb对应的表
externalPolarDBTableNow = spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://pc-xxx.mysql.polardb.rds.aliyuncs.com:3306")
.option("dbtable", dbtable)
.option("user", "name")
.option("password", "xxx*")
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表数据要写入的spark表的分区信息
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#执行导数据sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除临时的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#查看下分区以及统计下数据,主要用来做测试验证,实际运行过程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show()归档作业上生产
交互式查询定位为临时查询及调试,生产的作业还是建议使用spark作业的方式运行,使用文档参考。这里以pyspark作业为例:
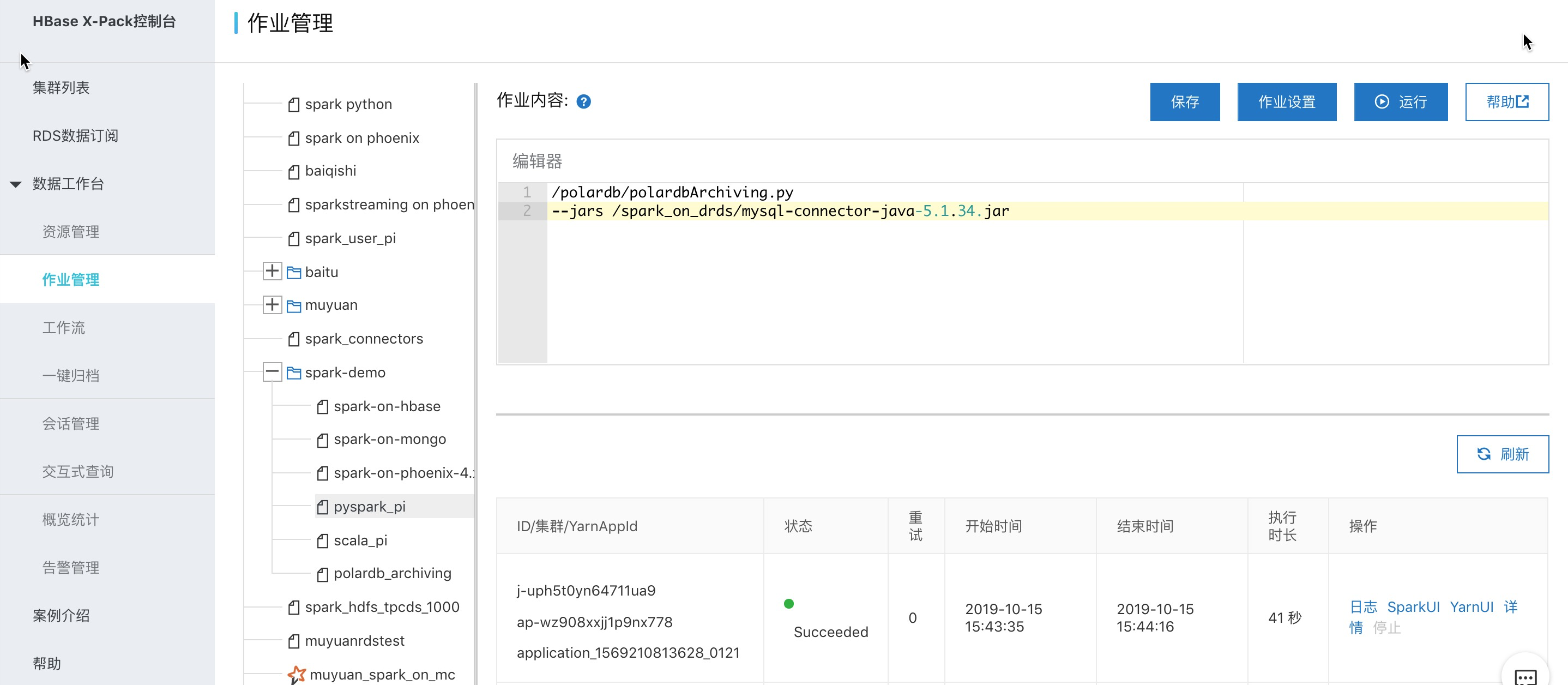
/polardb/polardbArchiving.py 内容如下:
# -*- coding: UTF-8 -*-
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession
.builder
.appName("PolardbArchiving")
.enableHiveSupport()
.getOrCreate()
spark.sql("drop table sparktest").show()
# 创建一张spark表,三级分区,分别是天、小时、分钟,最后一级分钟用来存储具体的5分钟的一张polardb表达的数据。字段和polardb里面的类型一致
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb里面创建了databse test1,具有三张表test1 ,test2,test3,这里遍历这三张表,每个表存储spark的一个5min的分区
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#构造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表关联polardb对应的表
externalPolarDBTableNow = spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://pc-.mysql.polardb.rds.aliyuncs.com:3306")
.option("dbtable", dbtable)
.option("user", "ma,e")
.option("password", "xxx*")
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表数据要写入的spark表的分区信息
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#执行导数据sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除临时的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#查看下分区以及统计下数据,主要用来做测试验证,实际运行过程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show()
spark.stop()本文作者:Roin123
本文为云栖社区原创内容,未经允许不得转载。