写在前面
写过blink sql的同学应该都有体会,明明写的时候就很顺滑,小手一抖,洋洋洒洒三百行代码,一气呵成。结果跑的时候,吞吐量就是上不去。导致数据延迟高,消息严重积压,被业务方疯狂吐槽。这时候,老鸟就会告诉你,同学,该优化优化你的代码了,再丢过来一个链接,然后留下一脸懵逼的你。笔者就是这么过来的,希望本文能帮助到跟我有过同样困惑,现在还一筹莫展的同学。
背景故事
先说一下相关背景吧,笔者作为一个刚入职阿里的小白,还处在水土不服的阶段,就被临危受命,改造数据大屏。为什么说临危受命呢,首先是此时距双十一仅剩一个月,再者,去年的双十一,这个大屏刚过零点就出现问题,数据一动不动,几个小时后开始恢复,但仍然延迟严重。此前,笔者仅有的实时计算开发经验是storm,用的是stream API,对于blink这种sql式的API完全没接触过。接到这个需求的时候,脑子里是懵的,灵魂三问来了,我是谁?我即将经历什么?我会死得有多惨?不是“此时此刻,非我莫属”的价值观唤醒了我,是老大的一句话,在阿里,不是先让老板给你资源,你再证明你自己,而是你先证明你自己,再用结果赢得资源,一席话如醍醐灌顶。然后就开始了一段有趣的故事~
压测血案
要找性能问题出在哪儿,最好的方法就是压测。这里默认大家都对节点反压有一定的了解,不了解的请先移步典型的节点反压案例及解法。
一开始是跟着大部队进行压测的,压测的结果是不通过!!!一起参加压测的有三十多个项目组,就我被点名。双十一演练的初夜,就这样伤心地流走了(╯°□°)╯︵ ┻━┻。西湖的水,全是我的泪啊。不过痛定思痛,我也是通过这次压测终于定位到了瓶颈在哪里。
瓶颈初现
数据倾斜
在做单量统计的时候,很多时候都是按商家维度,行业维度在做aggregate,按商家维度,不可避免会出现热点问题。
hbase写瓶颈
当时我在调大source分片数,并且也无脑调大了各个算子的资源之后,发现输出RPS还是上不去,sink节点也出现了消息积压。当时就判断,hbase有写瓶颈,这个我是无能为力了。后来的事实证明我错了,hbase的确有写瓶颈,但原因是我们写的姿势不对。至于该换什么姿势,请继续看下去。
神挡杀神
先来分析一下我们的数据结构(核心字段)biz_date, order_code, seller_id, seller_layer, order_status, industry_id
我们group by的典型场景有
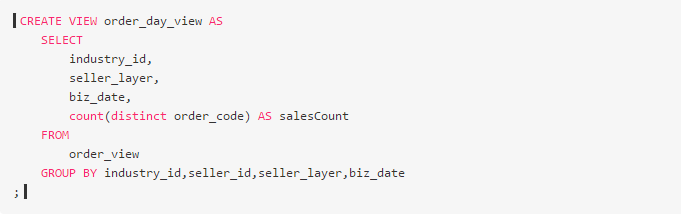
总结下来就是,按卖家维度,行业维度什么的,都非常容易出现数据倾斜。
数据倾斜其实有很多解法,这里我不展开讨论,只讲我们这个案例的解法。
倾斜的原因,无非就是group by的字段出现了热点,大量的消息都集中在了该字段少数几个取值上。通常的解法是,在消息中选择具备唯一性,或者预估会分布比较均匀的字段。如果这个字段是整型的,可以直接取模(模数一般是节点的并发数),如果是字符串,可以先进行哈希计算,再取模,得到一个分片地址(本文取名为bucket_id)。在接下来的所有aggregate算子中,都要把他作为group by的key之一。
在我们这个案例中,我们选择了order_code这个具备唯一性的字段。首先在源头把分片地址算出来,加到消息里面,代码如下:

然后把这个bucket_id层层传递下去,在每一个需要group by的地方都在后面带上bucket_id,例如:

事实上,我一开始想到的是用下面tips里的方法,结果就杵进垃圾堆里了,性能问题是解了,但是计算出来的数据都翻倍了,明显是错的。至于我是怎么发现这个问题,并分析其原因,再换了解法,又是另一段故事了。可以提前预告一下,是踩了blink撤回计算的坑,后面会再出一个专题来讲述这个故事哒~
这里还想再延伸一下,讲讲我的学习方法。如果读者中有跟我一样的小白,可能会奇怪,同样是小白,为何你这么秀,一上来就搞压测,还能准确地分析出性能的瓶颈在哪里。其实有两方面的原因,一方面是我有过storm的开发经验,对实时计算中会遇到的坑还是有一定的认识;另一方面,是我没说出来的多少个日日夜夜苦逼学习充电的故事。我的学习习惯是喜欢追根溯源,就找了很多介绍flink基本概念,发展历史,以及跟流式和批处理计算框架横向对比的各类博客。而且带着kpi去学习和什么包袱都没有去学习,心态和学习效率是不一样的。前者虽然效率更高,但是是以损害身心健康为代价的,因为学习过程中不可避免的会产生急躁情绪,然后就会不可避免的加班,熬夜,咖啡,再然后他们的好朋友,黑眼圈,豆豆,感冒就全来了。后者虽然轻松,但是什么包袱都没有,反而会产生懈怠,没有压力就没有动力,这是人的天性,拗不过的。这就是矛盾的点,所以在阿里,经常提到“既要也要还要”,其实宣扬的是一种学会平衡的价值观。至于怎么平衡,嘻嘻,天知地知我知。对,只能自己去领悟怎么平衡,别人教不会的。
概念有了一定的认知,下面就开始实践了。整个实践的过程,其实就是在不断的试错。我是一开始连反压的概念都不知道的,一直在无脑的调大CU,调大内存,调高并发数,调整每两个节点之间的并发数比例。寄希望于这样能解决问题,结果当然是无论我怎么调,吞吐量都是都风雨不动安如山。现在想想还是太年轻呀,如果这样简单的做法能解决问题,那那个前辈就绝对不会搞砸了,还轮的到我今天来解决。后来也是在无尽的绝望中想通了,不能再这么无脑了,我要找其他法子。想到的就是在代码层面动刀子,当然试错的基本路线没有动摇,前面也提到过,我一开始是想到的“加盐”,也是在试错。
学习方式决定了我做什么事,都不可能一次成功。甚至有很多情况,我明知道这样做是错的,但我就是想弄明白为什么行不通,而故意去踩这个坑。不过也正是因为试了很多错,踩了很多坑,才挖出了更多的有价值的知识点,扩大了知识的边界。
此时无声胜有声,送上几句名言,与诸君共勉
塞翁失马,焉知非福。---淮南子·人间训
一切过往,皆为序章。---阿里巴巴·行癫
学习就像跑步一样,每一步都算数。---百阿·南秋
tips: 如果在消息本身中找不到分布均匀的字段,可以考虑给每一条消息加上一个时间戳,直接使用系统函数获取当前时间,然后再对时间戳进行哈希取模计算,得到分片地址。相当于强行在时间维度上对消息进行打散,这种做法也被形象的称为“加盐”。
佛挡杀佛
上一段看下来,似乎只解决了数据倾斜的问题。之前还提到有一个hbase写瓶颈问题,这个该如何解呢?
还是接着上面的思路继续走下去,当我们把bucket_id一路传递下去,到了sink任务的时候,假设我们要按商家维度来统计单量,但是别忘了,我们统计的结果还按订单号来分片了的,所以为了得到最终的统计值,还需要把所有分片下的值再sum一下才行,这大概也是大多数人能想到的常规做法。而且我们现有的hbase rowKey设计,也是每个维度的统计数据对应一个rowKey的,为了兼容现有的设计,必须在写hbase之前sum一下。
但是笔者当时突发奇想,偏偏要反其道而行之,我就不sum,对于rowKey,我也给它分个片,就是在原来rowKey的基础上,后面再追加一个bucket_id。就相当于原来写到一个rowKey上的数据,现在把他们分散写到64个分片上了。
具体实现代码如下:

这样一来,API也必须改造了,读的时候采用scan模式,把所有分片都读出来,然后求和,相当于把sum的工作转移到API端了。
这样做的好处在于,一方面可以转移一部分计算压力,另一方面,因为rowKey只有一个,而我们写rowKey的任务(即sink节点)并发数可能有多个,Java开发者应该都深有体会,多线程并发对一个变量进行累加的时候,是需要加锁和释放锁的,会有性能损耗,可以猜测,hbase的写瓶颈就在于此。后来的事实也证明,这种做法将输出RPS提升了不止一个两个档次。
赶考当天
人事已尽,接下来就是关二爷的事了( ̄∇ ̄)。双十一零点倒计时结束,大屏数字开始飙升起来,随之一起的,还有我的肾上腺素。再看看数据曲线,延迟正常,流量峰值达日常的10倍。其实结果完全是在预期之内的,因为从最后一次的压测表现来看,100W的输入峰值(日常的333倍),5W的输出峰值(日常的400倍),都能稳稳的扛下来。出于数(懒)据(癌)安(晚)全(期)的角度考虑,很多大屏和数据曲线的截图就不放出来了。
其实现在回过头再看,此时的内心是平静如水的。不是大获全胜后的傲娇,也不是退隐山林的怯懦。只是看待问题的心态变了。没有翻不过的山,没有迈不过的坎。遇事不急躁,走好当下的每一步就好,也不必思考是对是错,因为每一步都算数,最后总能到达终点。
浮生后记
笔者写文章习惯带一些有故事趣味性的章节在里面,因为我觉得纯讲技术,即使是技术人看起来也会相当乏味,再者纯讲技术的前提是作者具备真正透进骨髓去讲述的功底,笔者自认为还相差甚远,只能加点鱼目来混珠了。换个角度来看,纯技术性的文章,观赏性和权威性更强,每一句都是精华,这种咀嚼后的知识虽有营养饱满,但是不是那么容易消化,消化后能吸收多少,还有待确认。所以我力求展示我的咀嚼过程,更多是面向跟我一样的小白用户,如果觉得冗长,请各位读者姥爷见谅~
作者介绍:王科,花名伏难,先后经历国内三大电商平台,苏宁,京东,阿里,电商大战深度参与者。现任职阿里巴巴供应链事业部,从事业务平台化改造、实时计算相关工作。信奉技术自由平等,希望通过简单形象的语言,打破上层建筑构建的知识壁垒,让天下没有难做的技术。
本文作者:王科
本文为阿里云内容,未经允许不得转载。