OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。
项目地址:https://github.com/tesseract-ocr
该项目最新版本是3.04,本人试验用的版本是3.02。
1 安装并设置环境
运行tesseract-ocr-setup-3.02.02.exe程序安装tesseract,如图所示,图中的jTessBoxEditor相关内容用于其他测试与本文无关。
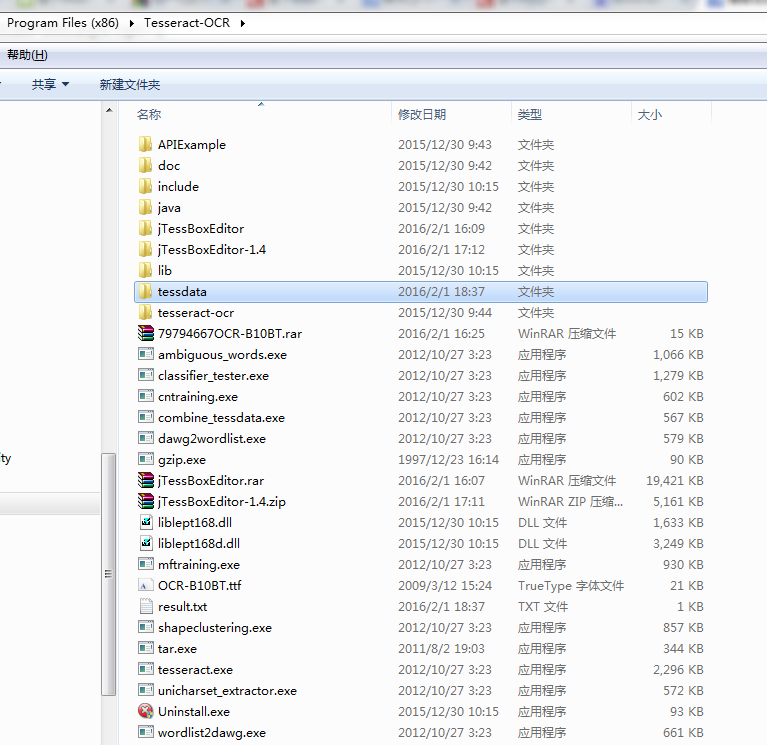
安装完成后为了能在cmd命令行直接使用tesseract.exe,向path环境变量中增加tesseract安装目录,同时添加环境变量TESSDATA_PREFIX,其值是训练数据tessdata所在的目录,例如图中为:F:Program Files (x86)Tesseract-OCR,该目录也可以由参数
--tessdata-dir指明,详细见第2节参数介绍。
2 参数介绍
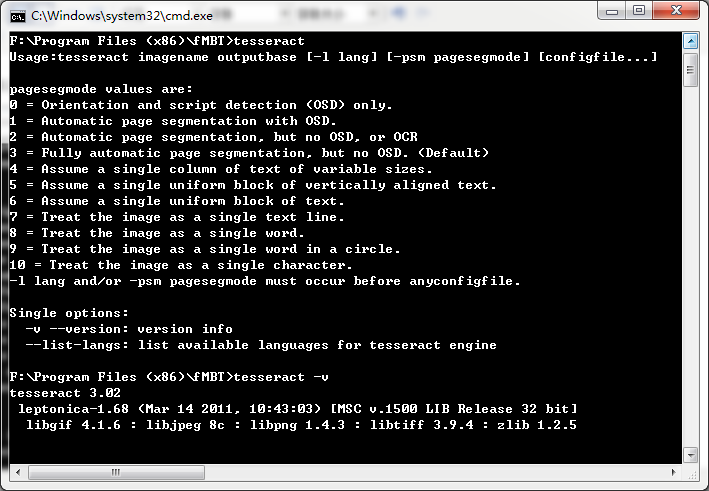
在命令行直接输入tesseract回车后可看到它的帮助信息,如图所示:
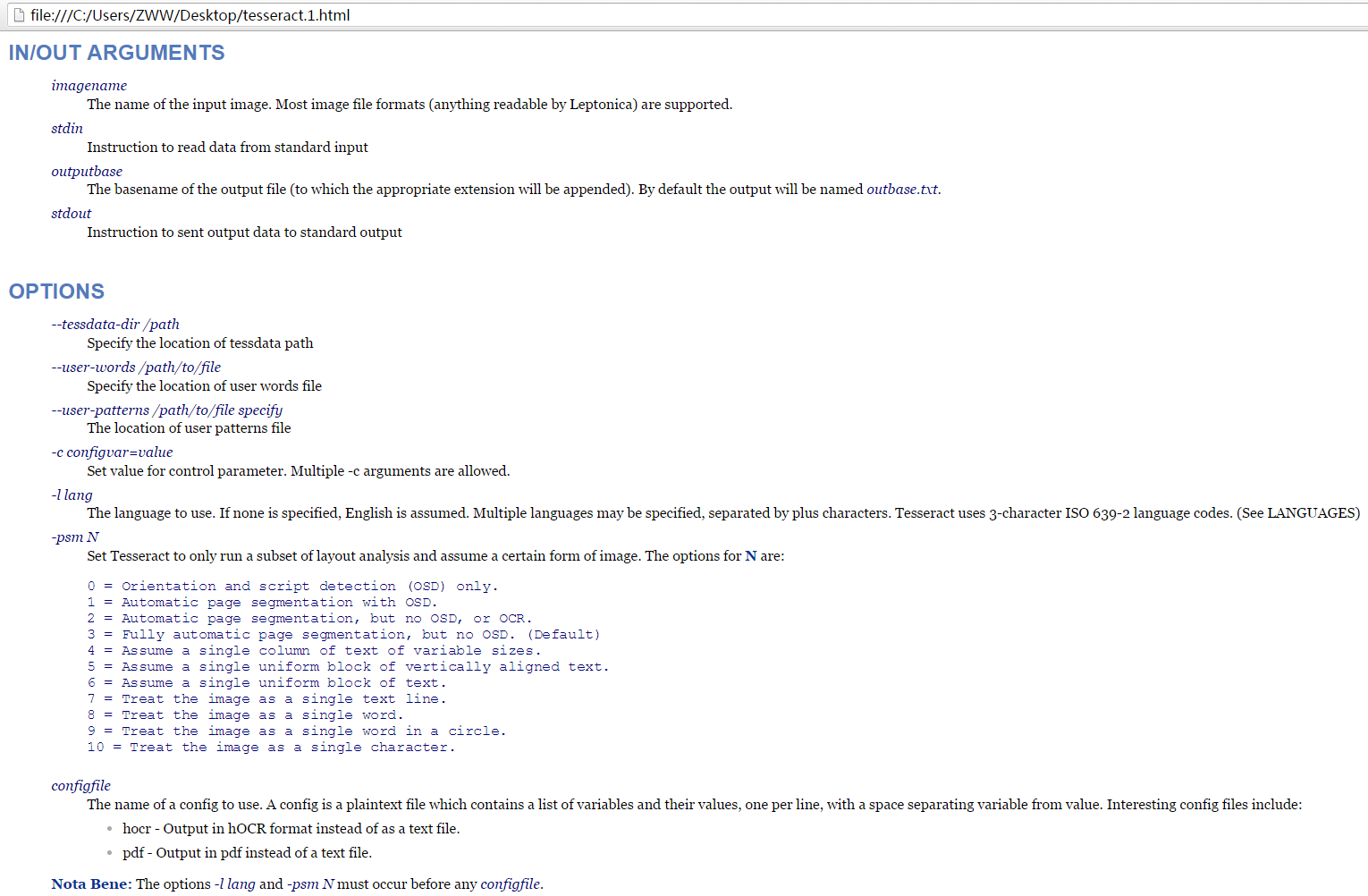
更详细的参数说明请参考:https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.html,部分内容如下图:
一般来说,可以使用如下的格式来使用tesseract:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
3 实例
如要识别如下图片,可以直接使用简单的命令:tesseract test.png result,即可将识别结果输出到result.txt文件中

识别结果如下:
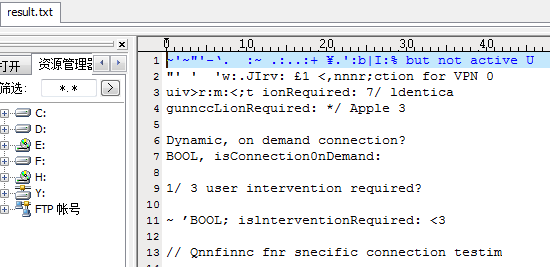
可以看出识别效果不是特别理想,所以识别前可对识别的图像进行预处理,典型处理如:增加对比度、二值化等,如对上一幅图进行预处理后如下图所示:
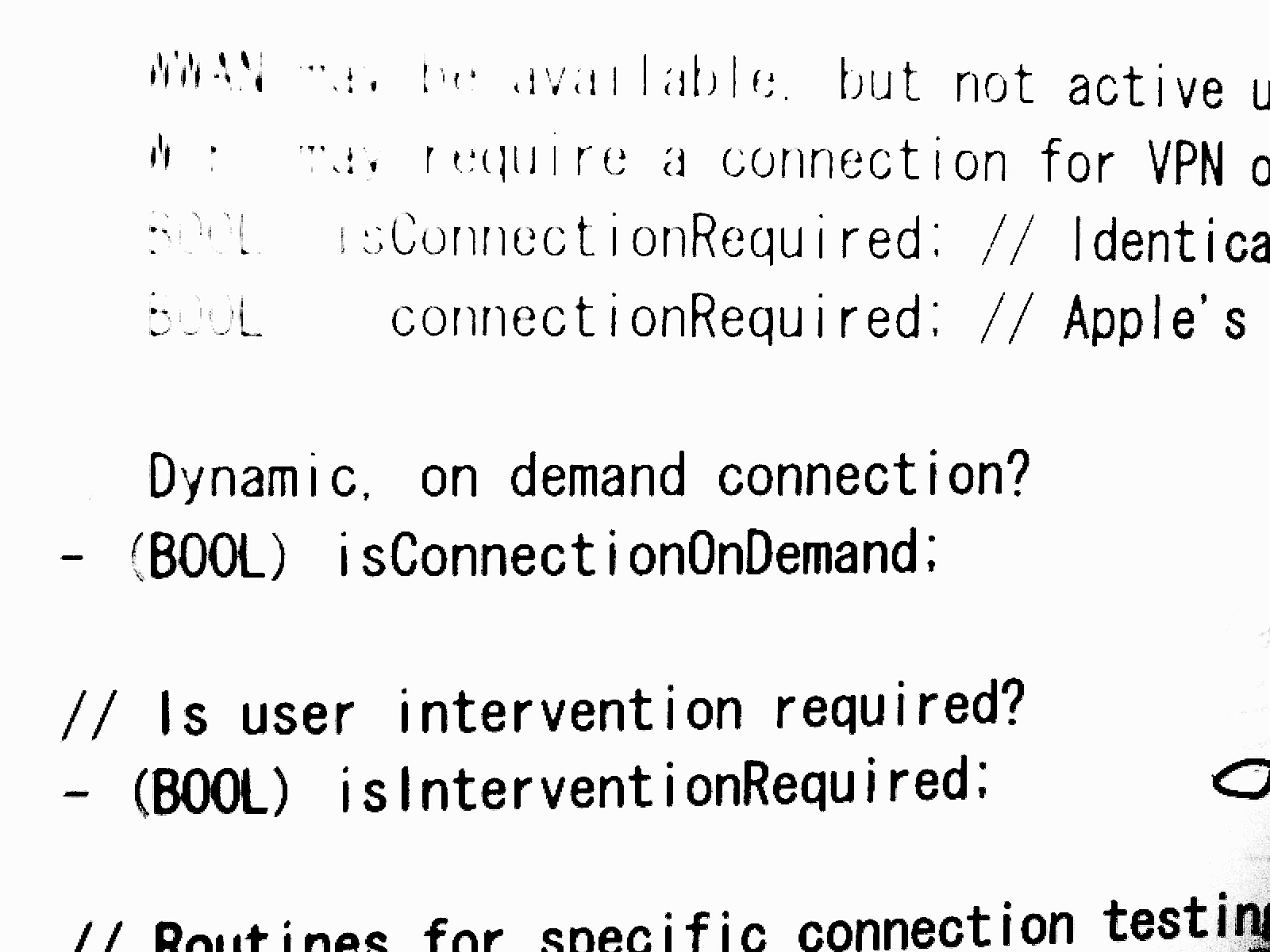
生成识别结果时,可以使用hocr参数来让tesseract生成html格式的结果文件,如:tesseract binary.png result hocr,识别结果如下:

对比可以看出预处理后的识别效果要明显优于之前的识别效果,生成html格式的识别文件还有另外一个好处,即可以获得识别字符在原图片上面的坐标信息,用文本编辑器打开上面的rusult.html文件,内容如图:

从图中红色方框内可以看出识别出的字符串user在原图片中的坐标信息(306,884)左上角,(445,926)右下角。此外之前版本还支持识别信心值,但从3.02版本以后该特性被去掉了,相关内容请参考:http://blog.csdn.net/sosoben/article/details/13768895
4 结语
以上只是简单介绍了tesseract的英文字符识别功能,其实它支持很多语言的识别,另外它还支持样本训练等,更深入的应用请查找其他文献。