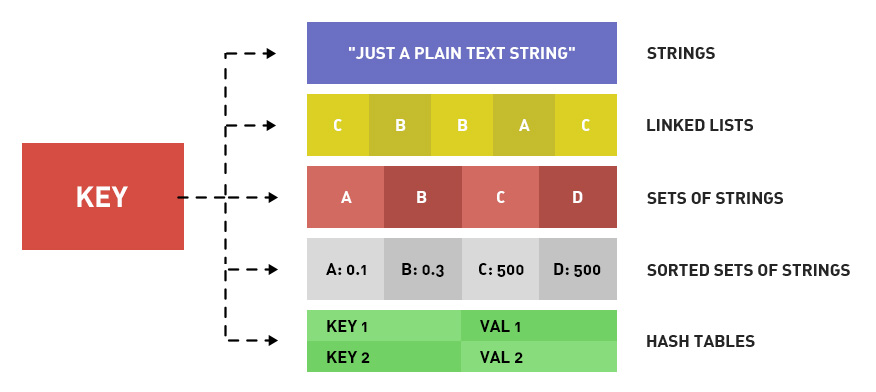
一:基础的数据结构
字符串类型、散列类型、列表类型、集合类型、有序集合类型。
二:删除策略
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
- volatile-lru(least recently used):最近最少使用算法,从设置了过期时间的键中选择空转时间最长的键值对清除掉;
- volatile-lfu(least frequently used):最近最不经常使用算法,从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉;
- volatile-ttl:从设置了过期时间的键中选择过期时间最早的键值对清除;
- volatile-random:从设置了过期时间的键中,随机选择键进行清除;
- allkeys-lru:最近最少使用算法,从所有的键中选择空转时间最长的键值对清除;
- allkeys-lfu:最近最不经常使用算法,从所有的键中选择某段时间之内使用频次最少的键值对清除;
- allkeys-random:所有的键中,随机选择键进行删除;
- noeviction:不做任何的清理工作,在redis的内存超过限制之后,所有的写入操作都会返回错误;但是读操作都能正常的进行;
二:内部模型(reactor)
三:文件事件和时间事件
- 文件事件:Redis服务器通过套接字与客户端进行连接,而文件事件就是服务器对套接字操作的抽象。 普通服务器与客户端的通信,会产生相应的文件事件,服务器需要监听并能够处理这些事件来完成网络通信操作。

- 时间事件:服务器的某些操作需要进行定时操作,而时间事件就是对这类定时操作的抽象。
- 一个时间事件由三部分组成:
(1)id:时间事件的全局唯一的ID(标识号)
(2)when:毫秒级别的UNIX时间戳
(3)timeProc:时间事件处理器
- 一个时间是定时事件还是周期性事件,取决于时间事件处理器的返回值,当返回一个ae.h/AE_NOMORE,该事件为定时事件,若为一个非AE_NOMORE值,则是一个周期性事件,同时通过这个返回 值,对时间事件的when属性进行更新,让该事件在该返回值对应的毫秒数后再继续执行。
- Redis服务器会将所有的时间事件放入一个无序链表中,每当时间时间执行器运行时,会遍历整个链表,找到已经到达时间的事件,并调用相应的事件处理器。
三:集群(Sentinel)
1. 主从切换:
每个 sentinel 节点通过定期监控 master 的健康状况。
sentinel 集群 发现 master 故障后,多个 sentinel 节点对主节点的故障达成一致,在 3 个 sentinel 节点中选择一个作为 leader ,例如,选举出 sentinel-0 节点作为 leader,来负责故障转移。
leader sentinel 把一个 slave 节点提升为 master,并让另一个 slave 从新的 master 复制数据,并告知客户端新的 master 的信息。
故障的旧 master 上线后,leader sentinel 让它从新的 master 复制数据。

2. sentinel 集群的监控功能详解
每隔10秒,每个 sentinel 节点会向主节点和从节点发送 info 命令获取 redis 主从架构的最新情况。例如,发送info replication命令可以得到以下信息:

每隔2秒,每个 sentinel 节点会向 redis 数据节点的__sentinel__:hello这个channel(频道)发送一条消息
<sentinel ip> <sentinel port> <sentinel runId> <Sentinel 配置版本> <master name> <master ip> <master port> <master 配置版本>
runid: 服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
组成:运行id由40位字符组成,是一个随机的十六进制字符,例如:7cfbf53e4901277d7247db9fac7945af44dcc666
作用:运行id被用于在服务器间进行传输,识别身份,如果向两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
实现方式:运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过info Server命令,可以查看节点的runid
每个 sentinel 节点会订阅该 channel,来了解其他sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
发现新的 sentinel节点:通过订阅主节点的__sentinel__:hello了解其他的 sentinel 节点信息,
如果是新加入的 sentinel 节点,将该 sentinel 节点信息保存起来,并与该 sentinel 节点创建连接sentinel
节点之间交换主节点的状态,用于确认 master 下线和故障处理的 leader 选举。
每隔1秒,每个 sentinel 节点会向主节点、从节点、其余 sentinel 节点发送一条ping命令做一次心跳检测,来确认这些节点是否可达。
通过定时发送ping命令,sentinel 节点对主节点、从节点,其余 sentinel 节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点下线判定的重要依据。
3. sdown(主观下线) 和 odown(被动下线)
主观下线: 每个 sentinel 节点每隔1秒对主节
点、从节点、其他 sentinel 节点发送 ping 命令做心跳检测,当这些节点超过
down-after-milliseconds没有进行有效回复,sentinel节点就会认为该节点下线,这个行为叫做主观下线。主观下线是某个 sentinel 节点的判断,并不是 sentinel 集群的判断, 所以存在误判的可能。
客观下线: 当 sentinel 主观下线的节点是主节点时,该 sentinel 节点会通过sentinel ismaster-down-by-addr命令向其他 sentinel 节点询问对主节点的判断,当超过
<quorum>个数(quorum可配置)的 sentinel 节点认为主节点确实有问题,这时该 sentinel 节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分是 sentine l节点都对主节点的下线做了同意的判定,那么这个判定就是客观的
4. 当 sentinel 集群确认 master odown,需要选举出一个 leader 节点来进行故障转移,选举过程如下:
每个在线的 sentinel 节点都有资格成为 leader,当它确认主节点客观下线时候,会向其他 sentinel 节点发送sentinel is-master-down-by-addr命令,要求将自己设置为leader,比如 s entinel-0 节点首先发起请求成为 leader 的请求。
每个 sentinel 节点都只能投出一票,于是当 sentinel-0 节点发起成为 leader 的请求后,会得到 sentinel-1 和 sentinel-2 节点的投票,总共得到 2 票,得到的票数和以下公式计算的 值作比较: 当得到的票数 >= max(quorum, num(sentinels) / 2 + 1) 的值,那么该 sentinel 节点成为 leader,于是,sentinel-0 节点成为 leader。
比如下一个确认 master 客观下线的 sentinel 节点为 sentinel-1,当它发起成为 leader 的请求后,由于 sentinel-2 节点已经给 sentinel-0 节点投过票了,于是它只能得到 sentinel -0节点投的一票,所以它不能成为 leader,而当 sentinel-2 发起请求成为 leader 的请求后,它一票都得不到。于是当已经选举出 leader 后,就不会再继续进行选举流程了,因为是没有意义 的。
如果一次选举没有选举出 leader,那么会进行下一次选举。
总结:正常情况下,哪个 sentinel 节点最先确认 master 客观下线,哪个 sentinel 节点就会成为执行故障转移的 leader。
介绍一下sentinel is-master-down-by-addr命令: "sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid>"
ip、port:询问此 ip:port 的 redis 进程是否下线
current_epoch:当前配置版本
runid:如果为当前 sentinel 节点的 runid,则此命令用于申请自己成为故障处理的 leader,如果是*,则此命令用于向其他 sentinel 节点确认 master 是否下线。
此命令返回结果包括3个信息:
down_state:目标 sentinel 节点对于主节点的下线判断,1是下线,0是在线。
leader_runid:当leader_runid等于*时,代表返回结果是说明主节点是否不可达,当 leader_runid 等于具体的runid,代表目标节点同意该 runid sentinel 节点成为 leader。
leader_epoch:leader 版本。
5. 要执行故障转移,首先要从 slave 中选择一个作为新的 master,选择的准则如下:
不选择不健康的 slave,以下状态的 slave 是不健康的:
主观下线的 slave
大于等于5秒没有回复过 sentinel 节点 ping 响应的 slave
与 master 失联超过down-after-milliseconds * 10秒的 slave
对健康的 slave 进行排序
选择 priority(从节点优先级,可配置,默认100)最低的从节点,如果有优先级相同的节点,进行下一步。注意如果这个值配置为0,则代表禁止该节点成为 master。
选择复制偏移量最大的从节点(复制的最完整),如果有复制偏移量相等的节点,进行下一步。
选择 runid 最小的从节点。
6. 然后就是 leader 进行故障转移的过程了:
leader 对选择出来的要成为 new master 的 slave 执行 slaveof no one 命令让其成为 new master。
leader 会向剩余的 slave 发送命令,让它们成为 new master 的 slave。
leader 会将 old master 更新为 slave点,并保持着对其关注,当其恢复后命令它去复制 new master。
复制规则和parallel-syncs配置有关。该配置指定了在执行故障转移时,最多可以有多少个 slave 同时对 new master 进行同步,这个数字越小,完成故障转移所需的时间就越长。
如果从服务器被设置为允许使用过期数据集(redis.conf 中slave-serve-stale-data配置) ,那么你可能不希望所有 slave 都在同一时间向 new master 发送同步请求,
因为尽管复制过程的绝大部分步骤都不会阻塞slave, 但 slave 在 load new master 发来的 RDB 文件时, 仍然会造成其在一段时间内不能处理请求。如果全部 slave
一起对 new master 进行同步, 那么就可能会造成所有 slave 在短时间内全部不可用的情况出现。你可以通过将这个值设为 1 来保证故障转移后最多只有一个 slave 处于不可用状态。
但这样的话,全部 slave 的数据同步就是串行的,这样就会增加故障转移整个过程的时间。
四:备份
Rdb:
Aof:
彩蛋(特殊命令)
- rename oldkey newkey:对 key 重命名,如果 newkey 存在则覆盖。
- renamenx oldkey newkey:对 key 重命名,如果 newkey 存在则不覆盖。
- randomkey:随即返回一个 key
- move key db-index:将 key 移动到指定的数据库中,如果 key 不存在或者已经在该数据库中,则返回 0。成功则返回 1。
- 根据 key 获取该键所存储的 redis 数据类型:TYPE key
- 自减:DECR key。将指定 key 的值减少 1
- DECRBY key increment 用来给指定 key 的值减 increment
- 增加浮点数:INCRBYFLOAT key increment。
- 向尾部追加:APPEND key value。如set test:key 123、append test:key 456、get test:key 就是 123456
- 获取长度:STRLEN key。
- 同时给多个 key 赋值:MSET title 这是标题 description 这是描述 content 这是内容。
- 同时获取多个 key 的值:MGET title description content
- 位操作之获取:GETBIT key offset。如字符 a 在 redis 中的存储为 01100001(ASCII为98),那么 GETBIT key 2 就是 1,GET key 0 就是 0。
- 位操作之设置:SETBIT key offset value。如字符 a 在 redis 中的存储为 01100001(ASCII为98),那么 SETBIT key 6 0,SETBIT key 5 1 那么 get key 得到的是 b。因为取出的二进制为 01100010。
- 位操作之统计:BITCOUNT key [start] [end]:BITCOUNT key 用来获取 key 的值中二进制是 1 的个数。而 BITCOUNT key start end 则是用来统计key的值中在第 start 和 end 之间的子字符串的二进制是 1 的个数(好绕啊)。
- 位操作之位运算:BITOP operation resultKey key1 key2。operation 是位运算的操作,有 AND,OR,XOR,NOT。resultKey 是把运算结构存储在这个 key 中,key1 和 key2 是参与运算的 key,参与运算的 key 可以指定多个。
- 字段是否存在:HEXISTS key field。存在返回 1,不存在返回 0
- 自增 N:HINCREBY key field increment。同字符串的自增类型,不再阐述。
- 获取字段数量:HLEN key。
- 删除列表中指定值:LREM key count value。删除 key 这个列表中,所有值为 value 的元素,只删除 count。如果有 count+1 个,那么就保留最后一个。count 不存在或者为 0,则删除所有的。如果 count 大于 0,则删除从头到尾的 count 个,如果 count 小于 0,则删除从尾到头的 count 个。
- 保留片段,删除其它:LTRIM key start end。保留 start 到 end 之间的所有元素,含 start 和 end。其他全部删除。
- 向列表插入元素:LINSERT key BEFORE/AFTER value1 value2。从列表头开始遍历,发现值为 value1 时停止,将 value2 插入,根据 BEFORE 或者 AFTER 插入到 value1 的前面还是后面。
- 把一个列表的一个元素转到另一个列表:RPOPLPUSH list1 list2。将列表 list1 的右边元素删除,并把该与元素插入到列表 list2 的左边。原子操作。
- 获取指定集合的所有元素:SMEMBERS key。
- 判断某个元素是否存在:SISMEMBER key value。
- 差集运算:SDIFF key1 key2...。对多个集合进行差集运算。
- 交集运算:SINNER key1 key2...。对多个集合进行交集运算。
- 并集运算:SUNION key1 key2...。对多个集合进行并集运算。
- 获取集合中元素个数:SCARD key。返回集合中元素的总个数。
- 对差集、交集、并集运算的结果存放在一个指定的 key 中:SDIFFSTORE storekey key1 key2。对 key1 和 key2 求差集,结果存放在 key 为 storekey 的集合中。SINNERSTORE 和 SUNIONSTORE 类似。
- 获取集合中的随即元素:SRANDMEMBER key [count]。参数 count 可选,如果 count 不存在,则随即一个。count 大于 0,则是不重复的 count 个元素。count 小于 0,则是一共 |count|个 元素,可以重复。
- 随即弹出一个元素:SPOP key。随即从集合中弹出一个元素并删除,将该元素的值返回。
- 获取集合中元素的数量:ZCARD key。
- 根据排名范围删除元素:ZREMRANGEBYRANK key start end。删除排名在 start 和 end 中的元素。
- 按照分数范围删除元素:ZREMRANGEBYSCORE key min max。
- 获得元素排名(正序):ZRANK key value。获取 value 在该集合中的从小到大的排名。
- 获得元素排名(倒序):ZREVRANK key value。获取 value 在该集合中从大到小的排名。
- 有序集合的交集:ZINTERSTORE storekey key1 key2...[WEIGHTS weight [weight..]] [AGGREGATE SUM|MIN|MAX]。用来计算多个集合的交集,结果存储在 storekey中。返回值是 storekey 的元素个数。AGGREGATE 为 SUM 则 storekey 集合的每个元素的分数是参与计算的集合分数和。MIN 是参与计算的分数最小值。MAX 是参与计算分数最大值。WEIGHTS 设置每个集合的权重,如 WEIGHTS 1 0.1。那么集合A的每个元素分数 * 1,集合B的每个元素分数 * 0.1
- 有序集合的并集:ZUNIONSTORE storekey key1 kye2...[WEIGHTS weight [weight..]] [AGGREGATE SUM|MIN|MAX]
转载至:
https://redis.io/topics/sentinel
https://blog.csdn.net/weixin_44449616/article/details/113277120
https://blog.csdn.net/xiaoxiaole0313/article/details/103813759
https://www.cnblogs.com/mengchunchen/p/10059436.html