urlparse和urlsplit函数:
urlparse:
url='http://www.baidu.com/s?wd=python&username=abc#1' result=parse.urlparse(url) print(result)

输入的结果为解析之后的各部分
输出对应的参数:
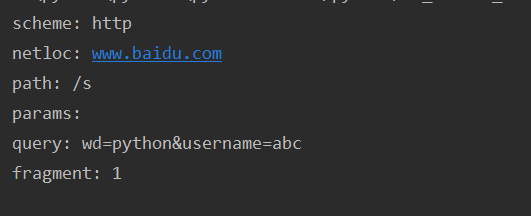
url='http://www.baidu.com/s?wd=python&username=abc#1' result=parse.urlparse(url) # print(result) print('scheme:',result.scheme) print('netloc:',result.netloc) print('path:',result.path) print('params:',result.params) print('query:',result.query) print('fragment:',result.fragment)
结果就是输入的网址各个部分
urlsplit:
url='http://www.baidu.com/s?wd=python&username=abc#1' result=parse.urlsplit(url) print(result)

这个里面没有params这个参数
因为在urlparse中,

在这个网址问好前面加一个分号,分号和问好中间加一个hello

urlparse这个函数的params这个参数就是为了获得分号和问号中间的值
在平时使用中两个函数是一样的。