此作业要求参见[https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11207]
作业0
修改create.cpp文件,改成由命令行参数确定生成的数据的数据量。修改readme.md的对应部分。(要求贴出修改之后的代码和read.md。)
修改后代码:
#include <iostream> #include <stdlib.h> #include <time.h> using namespace std; int main(int argc, char* argv[]) { int num = atoi(argv[1]); srand((unsigned)time(NULL)); for (int i = 0; i < num; i++) { cout << rand()<< " "; } cout << endl; return 0; }
readme.md:
| readme.md |
|
项目名称:creat.cpp 运行环境:Visual Studio 2019 使用说明: 1.安装vs; 2.编译create.cpp文件; 3.执行"create 10 > whitelist"命令生成文件whitelist; 4.执行"create 1000 > q"命令生成文件q; 5.编译brute.cpp文件; 6.执行“brute -w q < whitelist > output” |
作业1
对上面两段老杨写的代码任选其一进行profile,观察现象(要求有截图记录)。
选择c#程序代码进行profile,使用vs2019中的性能探查器进行cpu使用率检测,结果如图
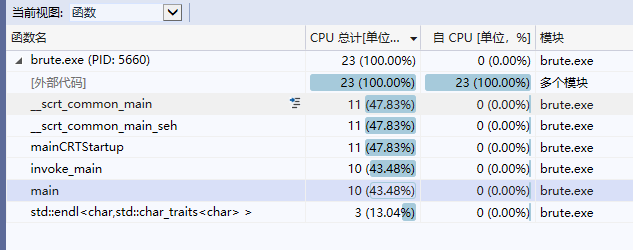

综上:几个占用的差不多,点开红色代码发现是main占用的内存最多。
作业2(10分)
以biggerwhitelist和biggerq作为输入,对作业1中选择的代码再次进行profile,找到代码执行最“慢”的地方,截图为证并文字说明。
生成biggerwhitelist和biggerq文件

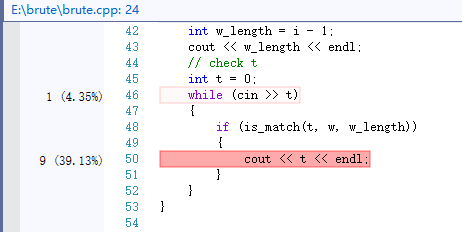
使用新生成的bigger数据进行profile,结果如下

由此可看出is_match占用的内存最多
作业3(10分)
根据作业2找到的最慢的地方,优化作业1中你选择的代码,在保证输出结果正确的前提下,减少老杨程序运行的时间。(优化后的代码需要你提交到git上,作为教师的判断依据。优化后的程序的名字应该是better.cpp或者better.cs。)
修改代码如下:
bool is_match(int t, int w[], int w_length) { int h = 0, r = w_length, m; while (h < r) { m = (h + r) / 2; if (t < w[m]) { r = m - 1; } else if (t > w[m]) { h = m + 1; } else if (t == w[m]) { return false; } } return true; }
将穷举改成二分法,运行时间就会减少
作业4(5分)
对作业3优化后的代码进行profile,结果与作业2的结果做对比。画表格并文字说明。
对主函数main进行对比,可发现效率提高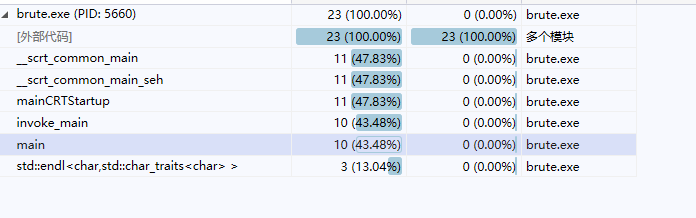

做业5(5分)
你觉得老杨的文档(readme),注释和代码风格又哪些问题,该如何改进?
文档和注释都有些不清晰,不易于理解。在详细一些会更好。
注释不标准,斜杠过多,两条斜杠即可,最好行注释写在代码后面
面试结束了,你和老杨握手,对他说出了面试的结果。你说的内容,不是今天的作业题,也许是若干年以后你想对当年教你的教师说的,也许是你希望未来的面试官对你说的。你想说的是什么呢?
该学习的时候就学习,作业不要拖!
golang中的路由分组
艾森豪威尔矩阵
列文定理
吃狗粮定理
mysql事务 锁
mysql中explain优化分析
mysql hash索引优化
各种浏览器内核介绍
浏览器 兼容性问题总结
- 最新文章
-
[8.2] Robot in a Grid
[8.1] Triple Step
[面试] Design Questions
Print a Binary Tree in Vertical Order
[Leetcode] Bulls and Cows
[Leetcode] Number of Digit Ones
Basic Calculator II
[Leetcode] Contains Duplicate III
spine在unity中实现闪白效果
Unity + Spine 碰撞检测
- 热门文章
-
【转载】删除数据库中同样的两条数据中的一条
Inno Setup 使用笔记
vs2012编译C代码,总是出现error C2143: syntax error : missing ';' before 'type'
【转载】用VS(c#)创建、调试windows service以及部署卸载
【原创】C#文件监视--采用filesystemwatcher 和 system.Timer.Timer
【原创】knockout--添加radio的checked绑定
【转载】+【原创】C#版SQLite的备份和还原
【原创】windows7+vs2012 如何安装windows服务
golang中的context上下文
golang 易犯错误事项