关于http的问题
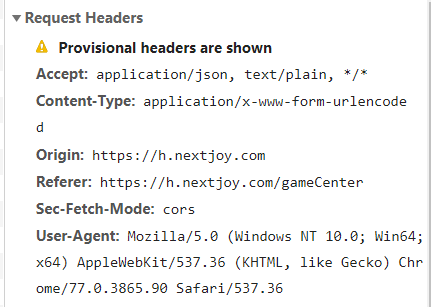
1.常见Http请求头
host (主机和端口号)
Accept (传输文件类型)
Content-Type(表示具体请求中的媒体类型信息)
Origin(表示请求出处,防止CSRF的攻击)
Upgrade-Insecure-Requests (升级为 HTTPS 请求)
User-Agent (浏览器名称)
Referer (页面跳转处)
Accept-Encoding(文件编解码格式)
Cookie (Cookie)
x-requested-with :XMLHttpRequest (是 Ajax 异步请求)
到了http2.0协议是小写字母,这点跟HTTP1不同。
另外部分新增的协议用冒号开头
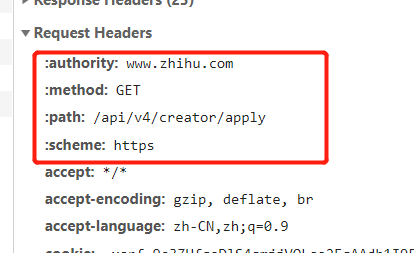
:authority(应该和host一样,显示域名)
:method(请求类型)
:path(请求接口)
:scheme(协议)

2.介绍Http2.0
http协议是互联网上使用最广泛、最通用的通讯协议,也可以说是互联网通讯协议的事实标准,http/2是http规范的一个最新版本
HTTP2的核心是性能优化,主要是延时和带宽两方面。与HTTP1.X相比的优势在于:
低延时。 多路复用(一个域名一个连接)避免了连接频繁创建和慢启动过程;服务端推送(Server Push)实现了资源“预读”,提前将资源推送到客户端。
带宽占用少。 头部压缩技术及二进制协议减少了对带宽的资源占用
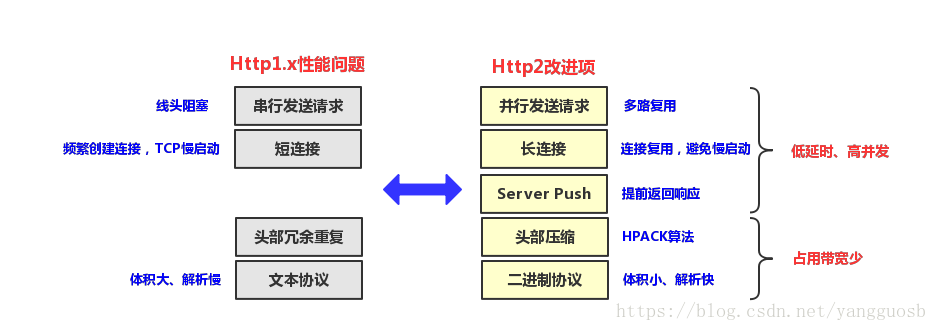
多路复用:多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行
头部压缩:hpack算法对header进行压缩
Server push :服务器传送
3.tcp三次握手,四次挥手
字段 含义
URG 紧急指针是否有效。为1,表示某一位需要被优先处理
ACK 确认号是否有效,一般置为1。
PSH 提示接收端应用程序立即从TCP缓冲区把数据读走。
RST 对方要求重新建立连接,复位。
SYN 请求建立连接,并在其序列号的字段进行序列号的初始值设定。建立连接,设置为1
FIN 希望断开连接。
---------------------
SYN_SENT 客户端状态
SYN_RECV半连接状态
ESTABLISHED表示两台机器正在传输数据
FIN-WAIT-1终止等待状态
FIN-WAIT-2半关闭状态
CLOSE-WAIT(关闭等待)状态
LAST-ACK(最后确认)状态
TIME-WAIT(时间等待)状态
CLOSED没有任何连接状态。
三次握手过程理解
第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手过程理解
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
参考:https://www.cnblogs.com/jessezeng/p/5617105.html
https://blog.csdn.net/qq_38950316/article/details/81087809
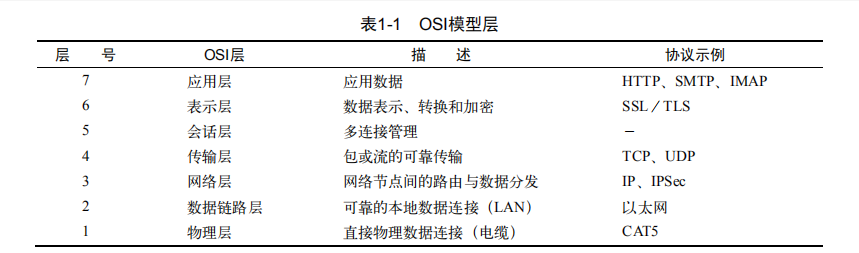
4.网络模型

5.http 缓存机制
浏览器缓存分为强缓存和协商缓存,浏览器加载一个页面的简单流程如下:
- 浏览器先根据这个资源的http头信息来判断是否命中强缓存。如果命中则直接加在缓存中的资源,并不会将请求发送到服务器。
- 如果未命中强缓存,则浏览器会将资源加载请求发送到服务器。服务器来判断浏览器本地缓存是否失效。若可以使用,则服务器并不会返回资源信息,浏览器继续从缓存加载资源。
- 如果未命中协商缓存,则服务器会将完整的资源返回给浏览器,浏览器加载新资源,并更新缓存。

-

参考:https://www.cnblogs.com/ranyonsue/p/8918908.html
6.http状态码
参考http://tools.jb51.net/table/http_status_code
少见问的较多的
203:非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
301:永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302:临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
304:告诉浏览器可以从缓存中获取所请求的资源
403:服务器拒绝此请求
405:请求的方式不对
7.介绍HTTPS
HTTP存在的安全问题:1.通信使用明文,内容可能会被窃听。2.不验证通信方的身份,因此有可能遭遇伪装。3.无法证明报文的完整性,所以有可能已遭篡改。这些问题在其它未加密的协议中也会存在。HTTPS通信机制可以有效地防止这些问题。
在网络模型中添加了安全层SSL/TSL,原先是应用层将数据直接给到TCP进行传输,现在改成应用层将数据给到TLS/SSL,将数据加密后,再给到TCP进行传输。
8.介绍SSL和TLS
SSL:(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层。SSL通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。该协议由两层组成:SSL记录协议和SSL握手协议。
TLS:(Transport Layer Security,传输层安全协议),用于两个应用程序之间提供保密性和数据完整性。该协议由两层组成:TLS记录协议和TLS握手协议。
参考https://kb.cnblogs.com/page/197396/
9.介绍DNS解析
浏览器输入访问地址后,会先进行本地解析hosts,如果本地没有则开始DNS解析:
会先在LDNS进行解析,如果没有则请求gTLD Server服务器(根),gTLD Server服务器返回
会返回给LDNS这个域名所属的顶级域服务器gTLD,然后LDNS会重新向这个gTLD发送解析请求,gTLD查找到访问地址是xx在某个服务提供商注册的域名,它就会找到这个服务提供商的服务器Name Server,然后Name Server在它的数据库中查找到访问地址对应的ip并将其返回,最终完成解析工作。
关于js的问题
1.前端通过什么做到并发请求
通过Promise.all(),web worker
关于web worker可以事先了解js运行机制j https://zhuanlan.zhihu.com/p/78113300
2. 说说JavaScript中有哪些异步编程方式?
1>回调函数 f1(f2)
回调函数是异步编程的基本方法。其优点是易编写、易理解和易部署;缺点是不利于代码的阅读和维护,各个部分之间高度耦合 (Coupling),流程比较混乱,而且每个任务只能指定一个回调函数。
2>事件监听 f1.on('done',f2)
事件监听即采用事件驱动模式,任务的执行不取决于代码的顺序,而取决于某个事件是否发生。其优点是易理解,可以绑定多个事件,每个事件可以指定多个回调函数,可以去耦合, 有利于实现模块化;缺点是整个程序都要变成事件驱动型,运行流程会变得不清晰。
3>发布/订阅
f1: jQuery.publish("done");
f2: jQuery.subscribe("done", f2);
假定存在一个"信号中心",某个任务执行完成,就向信号中心"发布"(publish)一个信号,其他任务可以向信号中心"订阅"(subscribe)这个信号,从而知道什么时候自己可以开始执行,这就叫做 "发布/订阅模式" (publish-subscribe pattern),又称 "观察者模式" (observer pattern)。该 方法的性质与"事件监听"类似,但其优势在于可以 通过查看"消息中心",了解存在多少信号、每个信号有多少订阅者,从而监控程序的运行。
4>promise对象 f1().then(f2)
Promises对象是CommonJS工作组提出的一种规范,目的是为异步编程提供 统一接口 ;思想是, 每一个异步任务返回一个Promise对象,该对象有一个then方法,允许指定回调函数。其优点是回调函数是链式写法,程序的流程非常清晰,而且有一整套的配套方法, 可以实现许多强大的功能,如指定多个回调函数、指定发生错误时的回调函数, 如果一个任务已经完成,再添加回调函数,该回调函数会立即执行,所以不用担心是否错过了某个事件或信号;缺点就是编写和理解相对比较难。
3.Bind、Call、Apply的区别
https://www.runoob.com/w3cnote/js-call-apply-bind.html
https://www.cnblogs.com/zhaozhenghao/p/11096000.html
4.从输入URL到页面加载全过程
1.读取缓存:
搜索自身的 DNS 缓存。(如果 DNS 缓存中找到IP 地址就跳过了接下来查找 IP 地址步骤,直接访问该 IP 地址。)
2.DNS 解析:将域名解析成 IP 地址
3.TCP 连接:TCP 三次握手,简易描述三次握手
客户端:服务端你在么?
服务端:客户端我在,你要连接我么?
客户端:是的服务端,我要链接。
连接打通,可以开始请求来
4.发送 HTTP 请求
5.服务器处理请求并返回 HTTP 报文
6.浏览器解析渲染页面
7.断开连接:TCP 四次挥手
关于第六步浏览器解析渲染页面又可以聊聊如果返回的是html页面
根据 HTML 解析出 DOM 树
根据 CSS 解析生成 CSS 规则树
结合 DOM 树和 CSS 规则树,生成渲染树
根据渲染树计算每一个节点的信息
根据计算好的信息绘制页面
5.介绍暂时性死区
ES6 明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
总之,在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”
ES6 规定暂时性死区和let、const语句不出现变量提升,主要是为了减少运行时错误,防止在变量声明前就使用这个变量,从而导致意料之外的行为。这样的错误在 ES5 是很常见的,现在有了这种规定,避免此类错误就很容易了。
总之,暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
6.ES6中的Map和原生的对象有什么区别
区别
object和Map存储的都是键值对组合。但是:
object的键的类型是 字符串;
map的键的类型是 可以是任意类型
另外注意,object获取键值使用Object.keys(返回数组);
Map获取键值使用 map变量.keys() (返回迭代器)。
参考https://www.cnblogs.com/mengfangui/p/9934849.html
7. 介绍一下ES6的新特性
•const和let
•模板字符串
•箭头函数
•函数的参数默认值
•Spread / Rest 操作符 https://yugasun.com/post/es6-spread-rest.html
•二进制和八进制字面量(通过在数字前面添加0o或0O即可将其转为八进制值,二进制使用0b或者0B)
•对象和数组解构
•ES6中的类(class)
•Promise
•Set()和Map()数据结构
•Modules(模块, 如import, export)
•for..of 循环
8.对闭包的看法,为什么要用闭包
闭包就是使一个函数能访问另一个函数作用域中的变量。形成闭包之后,该变量不会被垃圾回收机制回收。
闭包的原理其实还是作用域。
使用闭包的优点是可以避免全局变量污染,缺点是容易造成内存泄露。
在es5中,内部可访问外部的变量,外部无法访问内部的变量。想要调用函数内部变量时,不能直接使用,所以需要闭包的出现
参考(https://juejin.im/post/5c35d1ed518825255f0f39d8)
9.手写数组去重函数
// 数组去重 es5 let arr = [0,1,8,1,6,5,7,8,1,0,10] function demo(arr){ let as= []; for(var i =0;i<arr.length;i++){ if(as.indexOf(arr[i]) === -1){ as.push(arr[i]) } } return as.sort((a,b)=>{ return a-b }); } console.log(demo(arr)) function unique(arr){ for(var i=0; i<arr.length; i++){ for(var j=i+1; j<arr.length; j++){ if(arr[i]==arr[j]){ arr.splice(j,1); j--; } } } return arr; } var arr3 = [0,9,10,15,0,5,9,10]; console.log(unique(arr3)) //es6 let arr2 = [true,"true",0,1,9,9,4,4,0] function demo2(list){ return Array.from(new Set(list)) } console.log(demo2(arr2)) function demo4(arr) { var array =[]; for(var i = 0; i < arr.length; i++) { if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值 array.push(arr[i]); } } return array } console.log(demo4(arr2))
10.手写数组扁平化函数
console.log([1, [2, [3]]].flat(Infinity))//如果不管有多少层嵌套,都要转成一维数组,可以用Infinity关键字作为参数 console.log([1, 2, [3, [4, 5]]].flat(2))//flat()的参数为2,表示要“拉平”两层的嵌套数组 var arr5 = [1, [2, [3, 4]]]; function flatten(arr) { return arr.reduce(function(prev, next){ console.log(prev, next) return prev.concat(Array.isArray(next) ? flatten(next) : next) }, []) } console.log(flatten(arr5))
11.合并两个数组
//第一种 var array = ['a', 'b']; var elements = [0, 1, 2]; array.push.apply(array, elements); console.info(array); // ["a", "b", 0, 1, 2] //第二种 var c = a.concat(b);//c=[1,2,3,4,5,6] //第三种 for(var i in b){ a.push(b[i]); }
12.内存泄漏
内存泄漏指的是应用程序中存在不需要的引用未被清除或释放
一般指向定时器未清除干净,以及闭包的使用,解决方法引用计数 变量为null,或者标记清除
13.原型
每一个构造函数都拥有一个prototype属性,这个属性指向一个对象,也就是原型对象。当使用这个构造函数创建实例的时候,prototype属性指向的原型对象就成为实例的原型对象。
14.原型链
每个原型原型对象自身也是一个对象,它也有自己的原型对象,这样层层上溯,就形成了一个类似链表的结构,这就是原型链
15.js中如何判断一个值的类型
typeof运算符
console.log(typeof 123); 它对于数值、字符串、布尔值分别返回number、string、boolean,函数返回function,undefined返回undefined,除此以外,其他情况都返回object。
instanceof运算符
instanceof运算符返回一个布尔值,表示指定对象是否为某个构造函数的实例。
instanceof运算符的左边是实例对象,右边是构造函数。它会检查右边构造函数的ptototype属性,是否在左边对象的原型链上。
var b = [];
b instanceof Array //true
b instanceof Object //trueinstanceof运算符只能用于对象,不适用原始类型的值Object.prototype.toString方法
console.log(Object.prototype.toString.call(null)) //[object Null]
console.log(Object.prototype.toString.call(undefined)) //[object Undefined]
16.谈谈你对前端工程化的理解
推荐:https://baijiahao.baidu.com/s?id=1684111492756036632&wfr=spider&for=pc
自我总结:
前端工程化是模块化,组件化,规范化,自动化的一个集成,其目的是为了提高开发效率,降低成本,比如时间
组件化:ui 视图层级别 进行组件的嵌套,一个大组件由中阶组件构成,再由细粒组件构成,一个完整的视图
模块化:把代码,文件进行归类,对代码和资源的拆分;
规范化:制定开发标准,团队以标准进行开发
自动化:针对简单,不必要的指令,交给机器来做,实现自动化。如:部署集成
17.什么是微前端
推荐:微前端到底是什么? - 黯羽轻扬的文章 - 知乎 https://zhuanlan.zhihu.com/p/96464401
微前端借鉴了后端微服务的理念,将前端应用分解成一些更小、更简单的能够独立开发、测试、部署的小块,而在用户看来仍然是内聚的单个产品
将庞大的整体拆成可控的小块,并明确它们之间的依赖关系。关键优势在于:
- 代码库更小,更内聚、可维护性更高
- 松耦合、自治的团队可扩展性更好
- 渐进地升级、更新甚至重写部分前端功能成为了可能
关于vue面试题
1.vue的生命周期
| beforeCreate | 创建前,$el,data还没有创建 |
| created | 创建后,$el未创建,data已被初始化 |
| beforeMount | 挂在前,¥el和data,已创建,方法可调用,未被实例化 |
| mounted | 挂载后,数据实例化,展示在页面 |
| beforeUpdate | 更新前,组件未被渲染 |
| updated | 更新后,数组已渲染完成 |
| beforeDestroy | 销毁前,实例仍然完全可用 |
| destroyed | 销毁后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除 |
2.vue数据双向绑定原理

我们已经知道实现数据的双向绑定,首先要对数据进行劫持监听,所以我们需要设置一个监听器Observer,用来监听所有属性。如果属性发上变化了,就需要告诉订阅者Watcher看是否需要更新。因为订阅者是有很多个,所以我们需要有一个消息订阅器Dep来专门收集这些订阅者,然后在监听器Observer和订阅者Watcher之间进行统一管理的。接着,我们还需要有一个指令解析器Compile,对每个节点元素进行扫描和解析,将相关指令对应初始化成一个订阅者Watcher,并替换模板数据或者绑定相应的函数,此时当订阅者Watcher接收到相应属性的变化,就会执行对应的更新函数,从而更新视图。因此接下去我们执行以下3个步骤,实现数据的双向绑定:
1.实现一个监听器Observer,用来劫持并监听所有属性,如果有变动的,就通知订阅者。
2.实现一个订阅者Watcher,可以收到属性的变化通知并执行相应的函数,从而更新视图。
3.实现一个解析器Compile,可以扫描和解析每个节点的相关指令,并根据初始化模板数据以及初始化相应的订阅器。
3.说说你对 SPA 单页面的理解,它的优缺点分别是什么?
spa初始化后,相应加载html,css,js。SPA 不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
1> 前后端分离,架构清晰
2>用户体验好,不需要进行重新加载页面或者刷新,
缺点:
1>不利于seo搜索
2>对浏览器的前进后退不友好,建议前端写一个自己的堆栈管理
4.怎样理解 Vue 的单向数据流?
父子之间只有向下传流,props,反过来不行,防止从子组件意外改变父级组件的状态,从而导致你的应用的数据流向难以理解。
如果想要向上传流,只能通过自定义事件$emit()
5.谈谈你对 keep-alive 的了解?
keep-alive是vue内置组件,主要用于缓存组件
里面有俩个属性:include,exclude,两者都支持字符串或正则表达式,其中include是名称匹配的组件会被缓存,exclude 表示任何名称匹配的组件都不会被缓存 ,其中 exclude 的优先级比 include 高;
对应两个钩子函数 activated 和 deactivated ,当组件被激活时,触发钩子函数 activated,当组件被移除时,触发钩子函数 deactivated。
6.组件中 data 为什么是一个函数?
7.使用过vuex么?
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。每一个 Vuex 应用的核心就是 store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 ( state )。
(1)Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
(2)改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化。
主要包括以下几个模块:
- State:定义了应用状态的数据结构,可以在这里设置默认的初始状态。
- Getter:允许组件从 Store 中获取数据,mapGetters 辅助函数仅仅是将 store 中的 getter 映射到局部计算属性。
- Mutation:是唯一更改 store 中状态的方法,且必须是同步函数。
- Action:用于提交 mutation,而不是直接变更状态,可以包含任意异步操作。
- Module:允许将单一的 Store 拆分为多个 store 且同时保存在单一的状态树中。
8.vue-router 路由模式有几种?
vue-router 有 3 种路由模式:hash、history、abstract其中,3 种路由模式的说明如下:
-
hash: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
-
history : 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式;
-
abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式.
9.能说下 vue-router 中常用的 hash 和 history 路由模式实现原理吗?
(1)hash 模式的实现原理
早期的前端路由的实现就是基于 location.hash 来实现的。其实现原理很简单,location.hash 的值就是 URL 中 # 后面的内容。
hash 路由模式的实现主要是基于下面几个特性:
- URL 中 hash 值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash 部分不会被发送;
- hash 值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制hash 的切换;
- 可以通过 a 标签,并设置 href 属性,当用户点击这个标签后,URL 的 hash 值会发生改变;或者使用 JavaScript 来对 loaction.hash 进行赋值,改变 URL 的 hash 值;
- 我们可以使用 hashchange 事件来监听 hash 值的变化,从而对页面进行跳转(渲染)。
(2)history 模式的实现原理
HTML5 提供了 History API 来实现 URL 的变化。其中做最主要的 API 有以下两个:history.pushState() 和 history.repalceState()。这两个 API 可以在不进行刷新的情况下,操作浏览器的历史纪录。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录,如下所示:
window.history.pushState(null, null, path);
history 路由模式的实现主要基于存在下面几个特性:
- pushState 和 repalceState 两个 API 来操作实现 URL 的变化 ;
- 我们可以使用 popstate 事件来监听 url 的变化,从而对页面进行跳转(渲染);
- history.pushState() 或 history.replaceState() 不会触发 popstate 事件,这时我们需要手动触发页面跳转(渲染)。
10.Proxy 与 Object.defineProperty 优劣对比
Proxy 的优势如下:
- Proxy 可以直接监听对象而非属性;
- Proxy 可以直接监听数组的变化;
- Proxy 有多达 13 种拦截方法,不限于 apply、ownKeys、deleteProperty、has 等等是 Object.defineProperty 不具备的;
- Proxy 返回的是一个新对象,我们可以只操作新的对象达到目的,而 Object.defineProperty 只能遍历对象属性直接修改;
- Proxy 作为新标准将受到浏览器厂商重点持续的性能优化,也就是传说中的新标准的性能红利;
Object.defineProperty 的优势如下:
- 兼容性好,支持 IE9,而 Proxy 的存在浏览器兼容性问题,而且无法用 polyfill 磨平,因此 Vue 的作者才声明需要等到下个大版本( 3.0 )才能用 Proxy 重写。
11虚拟 DOM 实现原理?
虚拟 DOM 的实现原理主要包括以下 3 部分:
- 用 JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象;
- diff 算法 — 比较两棵虚拟 DOM 树的差异;
- pach 算法 — 将两个虚拟 DOM 对象的差异应用到真正的 DOM 树。
12.vue 中的 key 有什么作用?
Vue 中 key 的作用是:key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
更准确:因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确。
更快速:利用 key 的唯一性生成 map 对象来获取对应节点,比遍历方式更快
13.你有对 Vue 项目进行哪些优化?
如果没有对 Vue 项目没有进行过优化总结的同学,可以参考本文作者的另一篇文章《 Vue 项目性能优化 — 实践指南 》,文章主要介绍从 3 个大方面,22 个小方面详细讲解如何进行 Vue 项目的优化。
(1)代码层面的优化
- v-if 和 v-show 区分使用场景
- computed 和 watch 区分使用场景
- v-for 遍历必须为 item 添加 key,且避免同时使用 v-if
- 长列表性能优化
- 事件的销毁
- 图片资源懒加载
- 路由懒加载
- 第三方插件的按需引入
- 优化无限列表性能
- 服务端渲染 SSR or 预渲染
(2)Webpack 层面的优化
- Webpack 对图片进行压缩
- 减少 ES6 转为 ES5 的冗余代码
- 提取公共代码
- 模板预编译
- 提取组件的 CSS
- 优化 SourceMap
- 构建结果输出分析
- Vue 项目的编译优化
(3)基础的 Web 技术的优化
-
开启 gzip 压缩
-
浏览器缓存
-
CDN 的使用
-
使用 Chrome Performance 查找性能瓶颈
14.对于即将到来的 vue3.0 特性你有什么了解的吗?
Vue 3.0 正走在发布的路上,Vue 3.0 的目标是让 Vue 核心变得更小、更快、更强大,因此 Vue 3.0 增加以下这些新特性:
(1)监测机制的改变
3.0 将带来基于代理 Proxy 的 observer 实现,提供全语言覆盖的反应性跟踪。这消除了 Vue 2 当中基于 Object.defineProperty 的实现所存在的很多限制:
-
只能监测属性,不能监测对象
-
检测属性的添加和删除;
-
检测数组索引和长度的变更;
-
支持 Map、Set、WeakMap 和 WeakSet。
新的 observer 还提供了以下特性:
- 用于创建 observable 的公开 API。这为中小规模场景提供了简单轻量级的跨组件状态管理解决方案。
- 默认采用惰性观察。在 2.x 中,不管反应式数据有多大,都会在启动时被观察到。如果你的数据集很大,这可能会在应用启动时带来明显的开销。在 3.x 中,只观察用于渲染应用程序最初可见部分的数据。
- 更精确的变更通知。在 2.x 中,通过 Vue.set 强制添加新属性将导致依赖于该对象的 watcher 收到变更通知。在 3.x 中,只有依赖于特定属性的 watcher 才会收到通知。
- 不可变的 observable:我们可以创建值的“不可变”版本(即使是嵌套属性),除非系统在内部暂时将其“解禁”。这个机制可用于冻结 prop 传递或 Vuex 状态树以外的变化。
- 更好的调试功能:我们可以使用新的 renderTracked 和 renderTriggered 钩子精确地跟踪组件在什么时候以及为什么重新渲染。
(2)模板
模板方面没有大的变更,只改了作用域插槽,2.x 的机制导致作用域插槽变了,父组件会重新渲染,而 3.0 把作用域插槽改成了函数的方式,这样只会影响子组件的重新渲染,提升了渲染的性能。
同时,对于 render 函数的方面,vue3.0 也会进行一系列更改来方便习惯直接使用 api 来生成 vdom 。
(3)对象式的组件声明方式
vue2.x 中的组件是通过声明的方式传入一系列 option,和 TypeScript 的结合需要通过一些装饰器的方式来做,虽然能实现功能,但是比较麻烦。3.0 修改了组件的声明方式,改成了类式的写法,这样使得和 TypeScript 的结合变得很容易。
此外,vue 的源码也改用了 TypeScript 来写。其实当代码的功能复杂之后,必须有一个静态类型系统来做一些辅助管理。现在 vue3.0 也全面改用 TypeScript 来重写了,更是使得对外暴露的 api 更容易结合 TypeScript。静态类型系统对于复杂代码的维护确实很有必要。
(4)其它方面的更改
vue3.0 的改变是全面的,上面只涉及到主要的 3 个方面,还有一些其他的更改:
- 支持自定义渲染器,从而使得 weex 可以通过自定义渲染器的方式来扩展,而不是直接 fork 源码来改的方式。
- 支持 Fragment(多个根节点)和 Protal(在 dom 其他部分渲染组建内容)组件,针对一些特殊的场景做了处理。
- 基于 treeshaking 优化,提供了更多的内置功能。
15.导航守卫
导航守卫分为三类
全局守卫钩子,
路由独享守卫钩子
组件守卫钩子
1>全局守卫钩子
beforeEach-----全局前置守卫
beforeResolve-----全局解析守卫
afterEach(to, from)-----全局后置守卫
2>路由独享钩子
beforeEnter----和beforeEach完全相同,如果都设置则在beforeEach之后紧随执行
3>组件守卫钩子
beforeRouterEnter-----组件实例创建之前
beforeRouterUpdate-----当前路由改变,但是该组件被复用时调用
beforeRouteLeave-----组件离开时调用