Volley源码解析(二) 没有缓存的情况下直接走网络请求源码分析#
Volley源码一共40多个类和接口。除去一些工具类的实现,核心代码只有20多个类。所以相对来说分析起来没有那么吃力。但是要想分析透源码还是需要先宏观后微观的分支线式地来跟踪源码的来龙去脉。这才能把源码分析清楚。分析透彻。并且在了解源码的基础上根据自己的需求进行相应的改造。
Volley这个系列分析源码的人很多了。但是分析完代码能够带入实际工程场景进行改造改良使其适应自己工程的博文还是很少的。这里会按照先宏观后围观,先简单后复杂,一层一层的分析整个Volley源码。并且在下一篇文章中提供几个有趣的场景来改良Volley,让Volley适应工程场景的开发。
Volley宏观角度分析
Volley主干主要包括两方面,一方面是创建RequestQueue并在未添加请求时使其阻塞循环。另一方面是为RequestQueue添加Request请求对象。当请求装载以后RequestQueue就会被从阻塞中唤醒。执行队列里的请求。
其中RequestQueue包括着两类阻塞式具有优先级区分的队列,一个用于缓存的请求。另一个用于网络请求。
请求都是在子线程执行的,但是经过默认的ExecutorDelivery的分发(实际就是Handler的分发)重新将封装好的结果返回给主线程。
至此,整个躯干就描述的基本就成型了。
Volley微观角度分析
在对Volley有了一个初具棱角的印象以后就要步步入微的分析其源码。 我们先跟踪一条最简单的代码逻辑,不是用缓存,直接发送请求到网络,然后返回。这条路经分析起来最简单,也最直接。比较适合作为第一步分析的分支。
下面我们就从RequestQueue的创建开始:
不是用缓存直接发送网络请求的源码分析
先根据下面这个最简单的例子开始。
final TextView mTextView = (TextView) findViewById(R.id.text);
...
// Instantiate the RequestQueue. 初始化请求队列
RequestQueue queue = Volley.newRequestQueue(this);
String url ="http://www.google.com";
// Request a string response from the provided URL.构造请求对象
StringRequest stringRequest = new StringRequest(Request.Method.GET, url,
new Response.Listener<String>() {
@Override
public void onResponse(String response) {
// Display the first 500 characters of the response string.
mTextView.setText("Response is: "+ response.substring(0,500));
//UI线程
}
}, new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
mTextView.setText("That didn't work!");
//UI线程
}
});
// Add the request to the RequestQueue.
queue.add(stringRequest);
com.android.volley.toolbox.Volley.java
public static RequestQueue newRequestQueue(Context context, BaseHttpStack stack) {
BasicNetwork network;
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
network = new BasicNetwork(new HurlStack());
} else {
// Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
// At some point in the future we'll move our minSdkVersion past Froyo and can
// delete this fallback (along with all Apache HTTP code).
String userAgent = "volley/0";
try {
String packageName = context.getPackageName();
PackageInfo info = context.getPackageManager().getPackageInfo(packageName, 0);
userAgent = packageName + "/" + info.versionCode;
} catch (NameNotFoundException e) {
}
network = new BasicNetwork(
new HttpClientStack(AndroidHttpClient.newInstance(userAgent)));
}
} else {
network = new BasicNetwork(stack);
}
return newRequestQueue(context, network);
}
这段代码的意义在于初始化BasicNetwork对象。为了分析便捷这里直接给我三个类的描述:
- BasicNetwork: 用于执行网络请求前的而额外的header封装,以及请求返回后封装成NetworkResponse对象
- HurlStack:基于HttpUrlConnection发送网络请求。
- HttpClientStack:基于HttpClient发送网络请求。
- HurlStack,HttpClientStack是真正用于网络请求的类,真正的执行者。在BasicNetwork的performRequest中执行。使用
BasicNetwork的header封装,并把自己执行的结果交给BasicNetwork。
Volley广泛采用接口编程,这里吧BaseHttpStack作为抽象入口,所以可以做充分的扩展。言外之意就是你可以用Volley自己的HurlStack,HttpClientStack,也可以自己去实现请求的真实执行者。比如Okhttp等。
接着,我们的stack默认指定的是null.所以要根据API版本做判断。高于9则使用HttpUrlConnection做网络请求。低于9就是用HttpClient.这里做区分主要是低于9的版本时HttpUrlConnection有一个连接池的缺陷。现在可以低于9的版本很少了。可以忽略。
总结:这一步确定了使用哪种网络请求方法去做真正的网络请求
接着会调用下面的方法
private static RequestQueue newRequestQueue(Context context, Network network) {
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
queue.start();
return queue;
}
这段代码的核心意义在于创建一个用于缓存的文件,并new出一个RequestQueue对象。然后启动RequestQueue.
因为这里以分析无缓存的直接网络请求直线。所以DiskBasedCache里发生了什么暂时不去关心,直接进入RequestQueue.
com.android.volley.RequestQueue.java
public RequestQueue(Cache cache, Network network) {
this(cache, network, DEFAULT_NETWORK_THREAD_POOL_SIZE);//DEFAULT_NETWORK_THREAD_POOL_SIZE=4
}
public RequestQueue(Cache cache, Network network, int threadPoolSize) {//threadPoolSize默认4
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
/*
这里出现了一个ExecutorDelivery,进去看下是用主线程的Handler做了什么
*/
}
com.android.volley.ExecutorDelivery.java
/** Used for posting responses, typically to the main thread. */
private final Executor mResponsePoster;
/**
* Creates a new response delivery interface.
* @param handler {@link Handler} to post responses on
*/
public ExecutorDelivery(final Handler handler) {
// Make an Executor that just wraps the handler.
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
}
可以看到ExecutorDelivery只是用于利用Handler把Runnable里的代码发送到主线程去执行。
总结:这里就看出ExecutorDelivery的真正意义是把子线程中执行之后的结果带回主线程中
线面接着分析:
com.android.volley.RequestQueue.java
public RequestQueue(Cache cache, Network network, int threadPoolSize) {//threadPoolSize默认4
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
/*
这里出现了一个ExecutorDelivery,进去看下是用主线程的Handler做了什么
*/
}
public RequestQueue(Cache cache, Network network, int threadPoolSize,
ResponseDelivery delivery) {
mCache = cache;
mNetwork = network;
mDispatchers = new NetworkDispatcher[threadPoolSize];
mDelivery = delivery;
}
可以看到mDispatchers = new NetworkDispatcher[threadPoolSize];初始化了一个数组。这个数组包含四个NetworkDispatcher
跟进去NetworkDispatcher发现:
public class NetworkDispatcher extends Thread {
NetworkDispatcher本质就是一个线程。所以默认Volley起了四个线程去做网络请求的分发处理。在这个8核盛行的年月显然4线程有点过少,所以我们可以根据系统的核心数在这里做定制。充分发挥CPU性能。
总结:到这一步RequestQueue对象就产生了。他伴随着一个缓存类,一个网络请求类,一个网络请求分发的4个线程,以及请求结果回归主线程的mDelivery。
下面回到最开始的地方:
com.android.volley.toolbox.Volley.java
private static RequestQueue newRequestQueue(Context context, Network network) {
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
queue.start();
return queue;
}
生成RequestQueue以后调用了其queue.start();方法。
/**
* Starts the dispatchers in this queue.
*/
public void start() {
stop(); // Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// Create network dispatchers (and corresponding threads) up to the pool size.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
可以看到这里主要做了3件事:
- 如果先前有mCacheDispatcher线程和networkDispatcher线程在跑,先把他们中断掉。显然之前没有,那就不会被执行到
- new出一个CacheDispatcher线程,然后跑起来
- new出n个NetworkDispatcher线程,然后跑起来,这里n默认就是之前的4
接着就是执行线程run方法里代码了。这里只针对NetworkDispatcher线程分析。
com.android.volley.NetworkDispatcher.java
@Override
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
while (true) {//死循环地执行
try {
processRequest();
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {//当RequsstQueue stop方法调用时mQuit会执行,然后退出死循环,否则一直执行processRequest方法。
return;
}
}
}
}
进入processRequest方法
private void processRequest() throws InterruptedException {
// Take a request from the queue.
Request<?> request = mQueue.take();//当队列中没有数据时.这里是阻塞的
long startTimeMs = SystemClock.elapsedRealtime();
try {
request.addMarker("network-queue-take");
// If the request was cancelled already, do not perform the
// network request.
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
request.notifyListenerResponseNotUsable();
return;
}
addTrafficStatsTag(request);
// Perform the network request.
NetworkResponse networkResponse = mNetwork.performRequest(request);//这里是真正的网络请求执行的地方,并把结果封装后返回到这里
request.addMarker("network-http-complete");
// If the server returned 304 AND we delivered a response already,
// we're done -- don't deliver a second identical response. 304的时候结果不发送第二次
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
request.notifyListenerResponseNotUsable();
return;
}
// Parse the response here on the worker thread.
Response<?> response = request.parseNetworkResponse(networkResponse);//把请求相应结果再次封装成Response
request.addMarker("network-parse-complete");
// Write to cache if applicable.
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {//这里暂时不分析。只分析网络请求部分
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
// Post the response back.
request.markDelivered();
mDelivery.postResponse(request, response);//ResponseDelivery这里使用的是RQ里面的,所以会把相应结果从这个子线程回传到主线程(利用的Handler)
request.notifyListenerResponseReceived(response);
} catch (VolleyError volleyError) {
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
parseAndDeliverNetworkError(request, volleyError);
request.notifyListenerResponseNotUsable();
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
VolleyError volleyError = new VolleyError(e);
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
mDelivery.postError(request, volleyError);
request.notifyListenerResponseNotUsable();
}
}
这里是一个大概的流程。下面细致到各个对象中。
先从拿请求对象开始:
private final BlockingQueue<Request<?>> mQueue;
...
Request<?> request = mQueue.take();//当队列中没有数据时.这里是阻塞的
这个队列是一个特殊的队列,BlockingQueue是java.util.concurrent包中的接口
这里是API的解释:
BlockingQueue是支持两个附加操作的 Queue,这两个操作是:获取元素时等待队列变为非空,以及存储元素时等待空间变得可用
take()
获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。
可见这个队列在没有元素的时候是阻塞的。
执行网络请求的过程
// Perform the network request.
NetworkResponse networkResponse = mNetwork.performRequest(request);//这里是真正的网络请求执行的地方,并把结果封装后返回到这里
进入这个请求中:
com.android.volley.toolbox.BasicNetwork.java
@Override
public NetworkResponse performRequest(Request<?> request) throws VolleyError {
long requestStart = SystemClock.elapsedRealtime();
while (true) {//注意到这里是个死循环,但是遇到return则跳出循环
HttpResponse httpResponse = null;
byte[] responseContents = null;
List<Header> responseHeaders = Collections.emptyList();
try {
// Gather headers.
Map<String, String> additionalRequestHeaders =
getCacheHeaders(request.getCacheEntry());
httpResponse = mBaseHttpStack.executeRequest(request, additionalRequestHeaders);//为request补充额外的header
int statusCode = httpResponse.getStatusCode();//请求的返回码
responseHeaders = httpResponse.getHeaders();//响应头
// Handle cache validation.
if (statusCode == HttpURLConnection.HTTP_NOT_MODIFIED) {//304的时候表示数据无变化
Entry entry = request.getCacheEntry();
if (entry == null) {//缓存内容为空则表示数据为空,new的出翔参数传null
return new NetworkResponse(HttpURLConnection.HTTP_NOT_MODIFIED, null, true,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);
}
// Combine cached and response headers so the response will be complete.
List<Header> combinedHeaders = combineHeaders(responseHeaders, entry);
return new NetworkResponse(HttpURLConnection.HTTP_NOT_MODIFIED, entry.data,
true, SystemClock.elapsedRealtime() - requestStart, combinedHeaders);//entry缓存不空则按缓存返回
}
//检查返回提内容
// Some responses such as 204s do not have content. We must check.
InputStream inputStream = httpResponse.getContent();
if (inputStream != null) {
responseContents =
inputStreamToBytes(inputStream, httpResponse.getContentLength());
} else {
// Add 0 byte response as a way of honestly representing a
// no-content request.
responseContents = new byte[0];
}
// if the request is slow, log it.
long requestLifetime = SystemClock.elapsedRealtime() - requestStart;
logSlowRequests(requestLifetime, request, responseContents, statusCode);
if (statusCode < 200 || statusCode > 299) {
throw new IOException();//异常状态码抛IO异常,并且自己捕捉到
}
return new NetworkResponse(statusCode, responseContents, false,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);//正常请求下在这里返回封装结果
} catch (SocketTimeoutException e) {
attemptRetryOnException("socket", request, new TimeoutError());
} catch (MalformedURLException e) {
throw new RuntimeException("Bad URL " + request.getUrl(), e);
} catch (IOException e) {//IO异常捕捉到后,进行处理
int statusCode;
if (httpResponse != null) {
statusCode = httpResponse.getStatusCode();//返回数据不为空则后面尝试处理相应码
} else {
throw new NoConnectionError(e);//返回数据为空则直接抛异常,终止循环
}
VolleyLog.e("Unexpected response code %d for %s", statusCode, request.getUrl());
NetworkResponse networkResponse;
if (responseContents != null) {
networkResponse = new NetworkResponse(statusCode, responseContents, false,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);
if (statusCode == HttpURLConnection.HTTP_UNAUTHORIZED ||
statusCode == HttpURLConnection.HTTP_FORBIDDEN) {//对一401和403错误码进行重试操作
attemptRetryOnException("auth",
request, new AuthFailureError(networkResponse));//这个方法代表请求重试操作
} else if (statusCode >= 400 && statusCode <= 499) {//对于400到499的错误返回码不进行重发操作,直接结束死循环
// Don't retry other client errors.
throw new ClientError(networkResponse);
} else if (statusCode >= 500 && statusCode <= 599) {//对于5XX的返回码代表服务端出错,进行选择性的重试。重试与否取决于请求的标志位shouldRetryServerErrors()
if (request.shouldRetryServerErrors()) {
attemptRetryOnException("server",
request, new ServerError(networkResponse));
} else {
throw new ServerError(networkResponse);
}
} else {
// 3xx? No reason to retry.//对于3XX的返回码不重试
throw new ServerError(networkResponse);
}
} else {
attemptRetryOnException("network", request, new NetworkError());
}
}
}
}
Volley默认用的是的是BasicNetwork做网络请求处理。
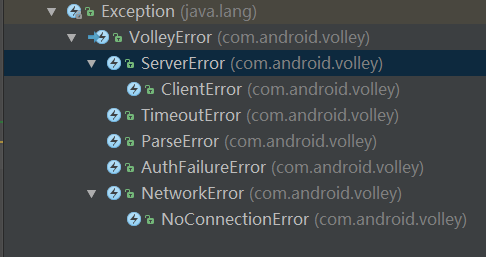
里面抛的异常都是被这个方法自己throw出去的。所以这种异常一旦发生死循环就会终止。
总结:
对于304 表示返回数据未更改,直接返回掉。
对于 <200 或者 >299的返回码抛IO异常并在循环中catch掉做特殊梳理。进行选择性的重试请求.
其中:
100 --- 200--- 300 ---400 ---500---599
- 401 403 进行请求重试
- 4XX的返回码 | 抛客户端错误异常,认为客户端请求有问题,不做准备请求重试
- 5XX的返回码 | 抛服务端错误异常,认为服务端出问题。这时,由请求对象自身决定是否准备请求重试
- 3XX的返回码 | 认为服务端错误异常。不做准备请求重试
- 除此之外的请求失败都进行准备重试
除了对反悔码的处理,还有超时的请求,会进行请求重试。
按照请求是否准备重试可区分为:
准备请求重试的返回码:
401 403 5XX(如果request有配置需要重试则允许重试请求) 超时请求
不进行准备重试的返回码:
剩余的返回码均不准备重试请求
下面进入attemptRetryOnException()方法一探究竟:
/**
* Attempts to prepare the request for a retry. If there are no more attempts remaining in the
* request's retry policy, a timeout exception is thrown.
* @param request The request to use.
*/
private static void attemptRetryOnException(String logPrefix, Request<?> request,
VolleyError exception) throws VolleyError {
RetryPolicy retryPolicy = request.getRetryPolicy();
int oldTimeout = request.getTimeoutMs();
try {
retryPolicy.retry(exception);
} catch (VolleyError e) {
request.addMarker(
String.format("%s-timeout-giveup [timeout=%s]", logPrefix, oldTimeout));
throw e;
}
request.addMarker(String.format("%s-retry [timeout=%s]", logPrefix, oldTimeout));
}
这个方法的目的就是为了请求准备重试而生。他会交给RetryPolicy结合request的超时时间设定,去做重试准备操作。
这里的所有请求默认都是使用DefaultRetryPolicy
public abstract class Request<T> implements Comparable<Request<T>> {
...
/**
* Creates a new request with the given method (one of the values from {@link Method}),
* URL, and error listener. Note that the normal response listener is not provided here as
* delivery of responses is provided by subclasses, who have a better idea of how to deliver
* an already-parsed response.
*/
public Request(int method, String url, Response.ErrorListener listener) {
mMethod = method;
mUrl = url;
mErrorListener = listener;
setRetryPolicy(new DefaultRetryPolicy());//所有请求默认用这个重试策略
mDefaultTrafficStatsTag = findDefaultTrafficStatsTag(url);
}
...
}
下面看一下默认的重试策略是什么样的:
DefaultRetryPolicy.java
/**
* Constructs a new retry policy using the default timeouts.
*/
public DefaultRetryPolicy() {
this(DEFAULT_TIMEOUT_MS, DEFAULT_MAX_RETRIES, DEFAULT_BACKOFF_MULT);//这三个值默认是 2500 1 1F
//代表超时时间2.5秒,最大重试次数1次, 乘数因子是1F
}
/**
* Constructs a new retry policy.
* @param initialTimeoutMs The initial timeout for the policy.
* @param maxNumRetries The maximum number of retries.
* @param backoffMultiplier Backoff multiplier for the policy.
*/
public DefaultRetryPolicy(int initialTimeoutMs, int maxNumRetries, float backoffMultiplier) {
mCurrentTimeoutMs = initialTimeoutMs;//2500
mMaxNumRetries = maxNumRetries;//1
mBackoffMultiplier = backoffMultiplier;//1f
}
/**
* Prepares for the next retry by applying a backoff to the timeout.
* @param error The error code of the last attempt.
*/
@Override
public void retry(VolleyError error) throws VolleyError {
mCurrentRetryCount++;
mCurrentTimeoutMs += (mCurrentTimeoutMs * mBackoffMultiplier);//按照默认参数,下一次请求超时的时间将是5s
if (!hasAttemptRemaining()) {//超过最大允许重试次数就抛异常
throw error;
}
}
/**
* Returns true if this policy has attempts remaining, false otherwise.
*/
protected boolean hasAttemptRemaining() {
return mCurrentRetryCount <= mMaxNumRetries;
}
这里的retry是为下一次用户请求做准备操作。延长超时时间。这样做有一个好处就是,对于请求超时或者失败的操作,进行了延长超时时间的处理,保证更大概率的得到返回数据,在请求重试发生的时候,会立即从catch的异常状态中,重新回到while循环的首行代码执行。
查看完这段代码就基本对这个方法有了真正的认识。这个死循环并不是一直在循环中执行。而是可以随时跳出的。死循环的目的就是为了给失败的请求一个重试的机会,
当然这里的重试处理不一定用抛异常的形式进行处理,但是按照正常逻辑写反而会造成代码复杂度提升。
while死循环和try catch return优雅的处理了请求重试,异常处理准备重试操作,和正确情况下的结果返回。
回到NetworkDispatcher processRequest()方法继续跟踪
@Override
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
while (true) {
try {
processRequest();
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
}
}
}
//这个方法运行在无返回的真-死循环中,除非主动把线程中断掉
private void processRequest() throws InterruptedException {
// Take a request from the queue.
Request<?> request = mQueue.take();
long startTimeMs = SystemClock.elapsedRealtime();
try {
request.addMarker("network-queue-take");
// If the request was cancelled already, do not perform the
// network request.
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
request.notifyListenerResponseNotUsable();
return;
}
addTrafficStatsTag(request);
// Perform the network request.
NetworkResponse networkResponse = mNetwork.performRequest(request);
request.addMarker("network-http-complete");
// If the server returned 304 AND we delivered a response already,
// we're done -- don't deliver a second identical response.
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
request.notifyListenerResponseNotUsable();
return;
}
// Parse the response here on the worker thread.结果交给各个扩展Request的子类自己做结果处理封装
Response<?> response = request.parseNetworkResponse(networkResponse);
request.addMarker("network-parse-complete");
// Write to cache if applicable.
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
// Post the response back.
request.markDelivered();
mDelivery.postResponse(request, response);//这里是核心的操作,从这个子线程中利用Handler回到主线程执行对结果的操作
request.notifyListenerResponseReceived(response);
} catch (VolleyError volleyError) {
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
parseAndDeliverNetworkError(request, volleyError);//这里是核心的操作,从这个子线程中利用Handler回到主线程执行对错误结果的操作
request.notifyListenerResponseNotUsable();
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
VolleyError volleyError = new VolleyError(e);
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
mDelivery.postError(request, volleyError);//这里是核心的操作,从这个子线程中利用Handler回到主线程执行对错误结果的操作
request.notifyListenerResponseNotUsable();
}
}
我们从刚开始RequestQueue初始化的时候知道这里的mDelivery是ExecutorDelivery的实例
@Override
public void postResponse(Request<?> request, Response<?> response) {
postResponse(request, response, null);
}
@Override
public void postResponse(Request<?> request, Response<?> response, Runnable runnable) {
request.markDelivered();
request.addMarker("post-response");
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
}
@Override
public void postError(Request<?> request, VolleyError error) {
request.addMarker("post-error");
Response<?> response = Response.error(error);
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, null));
}
最后都会调用:
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
也就是:
// Make an Executor that just wraps the handler.
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
new ResponseDeliveryRunnable(request, response, runnable)交给handler去处理
实际上ResponseDeliveryRunnable就是Runnable的一个实现
ResponseDeliveryRunnable.java
@SuppressWarnings("unchecked")
@Override
public void run() {
// NOTE: If cancel() is called off the thread that we're currently running in (by
// default, the main thread), we cannot guarantee that deliverResponse()/deliverError()
// won't be called, since it may be canceled after we check isCanceled() but before we
// deliver the response. Apps concerned about this guarantee must either call cancel()
// from the same thread or implement their own guarantee about not invoking their
// listener after cancel() has been called.
// If this request has canceled, finish it and don't deliver.
if (mRequest.isCanceled()) {
mRequest.finish("canceled-at-delivery");
return;
}
// Deliver a normal response or error, depending.
if (mResponse.isSuccess()) {
mRequest.deliverResponse(mResponse.result);
} else {
mRequest.deliverError(mResponse.error);
}
// If this is an intermediate response, add a marker, otherwise we're done
// and the request can be finished.
if (mResponse.intermediate) {
mRequest.addMarker("intermediate-response");
} else {
mRequest.finish("done");
}
// If we have been provided a post-delivery runnable, run it.
if (mRunnable != null) {
mRunnable.run();
}
}
因为ResponseDeliveryRunnable由handler发给主线程,所以上面run方法的所有操作都是在主线程中执行的。
最后
mRequest.deliverResponse(mResponse.result);
会调用esponse.Listener的onResponse方法。也就是最开始在new Request的时候实现的匿名ResponseListener接口
至此所有直接走网络的流程就走完了。
注意####
其中BasicNetwork的performRequest方法在执行网络请求以后以及对结果返回之前有一个重要的操作,就是把数据流转换为字节数组:
@Override
public NetworkResponse performRequest(Request<?> request) throws VolleyError {
long requestStart = SystemClock.elapsedRealtime();
while (true) {
HttpResponse httpResponse = null;
byte[] responseContents = null;
List<Header> responseHeaders = Collections.emptyList();
try {
// Gather headers.
Map<String, String> additionalRequestHeaders =
getCacheHeaders(request.getCacheEntry());
httpResponse = mBaseHttpStack.executeRequest(request, additionalRequestHeaders);
int statusCode = httpResponse.getStatusCode();
responseHeaders = httpResponse.getHeaders();
// Handle cache validation.
if (statusCode == HttpURLConnection.HTTP_NOT_MODIFIED) {
Entry entry = request.getCacheEntry();
if (entry == null) {
return new NetworkResponse(HttpURLConnection.HTTP_NOT_MODIFIED, null, true,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);
}
// Combine cached and response headers so the response will be complete.
List<Header> combinedHeaders = combineHeaders(responseHeaders, entry);
return new NetworkResponse(HttpURLConnection.HTTP_NOT_MODIFIED, entry.data,
true, SystemClock.elapsedRealtime() - requestStart, combinedHeaders);
}
// Some responses such as 204s do not have content. We must check.
InputStream inputStream = httpResponse.getContent();
if (inputStream != null) {
responseContents =
inputStreamToBytes(inputStream, httpResponse.getContentLength());//这里对流转换为字节的操作
} else {
// Add 0 byte response as a way of honestly representing a
// no-content request.
responseContents = new byte[0];
}
// if the request is slow, log it.
long requestLifetime = SystemClock.elapsedRealtime() - requestStart;
logSlowRequests(requestLifetime, request, responseContents, statusCode);
if (statusCode < 200 || statusCode > 299) {
throw new IOException();
}
return new NetworkResponse(statusCode, responseContents, false,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);
} catch (SocketTimeoutException e) {
attemptRetryOnException("socket", request, new TimeoutError());
} catch (MalformedURLException e) {
throw new RuntimeException("Bad URL " + request.getUrl(), e);
} catch (IOException e) {
int statusCode;
if (httpResponse != null) {
statusCode = httpResponse.getStatusCode();
} else {
throw new NoConnectionError(e);
}
VolleyLog.e("Unexpected response code %d for %s", statusCode, request.getUrl());
NetworkResponse networkResponse;
if (responseContents != null) {
networkResponse = new NetworkResponse(statusCode, responseContents, false,
SystemClock.elapsedRealtime() - requestStart, responseHeaders);
if (statusCode == HttpURLConnection.HTTP_UNAUTHORIZED ||
statusCode == HttpURLConnection.HTTP_FORBIDDEN) {
attemptRetryOnException("auth",
request, new AuthFailureError(networkResponse));
} else if (statusCode >= 400 && statusCode <= 499) {
// Don't retry other client errors.
throw new ClientError(networkResponse);
} else if (statusCode >= 500 && statusCode <= 599) {
if (request.shouldRetryServerErrors()) {
attemptRetryOnException("server",
request, new ServerError(networkResponse));
} else {
throw new ServerError(networkResponse);
}
} else {
// 3xx? No reason to retry.
throw new ServerError(networkResponse);
}
} else {
attemptRetryOnException("network", request, new NetworkError());
}
}
}
}
进入inputStreamToBytes方法一探究竟:
/** Reads the contents of an InputStream into a byte[]. */
private byte[] inputStreamToBytes(InputStream in, int contentLength)
throws IOException, ServerError {
PoolingByteArrayOutputStream bytes =
new PoolingByteArrayOutputStream(mPool, contentLength);
byte[] buffer = null;
try {
if (in == null) {
throw new ServerError();
}
buffer = mPool.getBuf(1024);
int count;
while ((count = in.read(buffer)) != -1) {
bytes.write(buffer, 0, count);
}
return bytes.toByteArray();
} finally {
try {
// Close the InputStream and release the resources by "consuming the content".
if (in != null) {
in.close();
}
} catch (IOException e) {
// This can happen if there was an exception above that left the stream in
// an invalid state.
VolleyLog.v("Error occurred when closing InputStream");
}
mPool.returnBuf(buffer);
bytes.close();
}
}
这里的ByteArrayPool的实例mPool实在RQ初始化的时候就已经初始化了的,其中默认对ByteArrayPool中字节数组池总量大小的限制默认是4KB.而且可以循环利用.
查看ByteArrayPool:
/**
* Returns a buffer from the pool if one is available in the requested size, or allocates a new
* one if a pooled one is not available.
*
* @param len the minimum size, in bytes, of the requested buffer. The returned buffer may be
* larger.
* @return a byte[] buffer is always returned.
*/
public synchronized byte[] getBuf(int len) {
for (int i = 0; i < mBuffersBySize.size(); i++) {
byte[] buf = mBuffersBySize.get(i);
if (buf.length >= len) {
mCurrentSize -= buf.length;
mBuffersBySize.remove(i);
mBuffersByLastUse.remove(buf);
return buf;
}
}
return new byte[len];
}
getBuf会返回一个不小于指定需要的大小的buf。
其中mCurrentSize代表所有分配过的字节数组大小的总值。用他来保证不会超过字节池的最大指定大小。
mBuffersBySize是一个列表。里面存着现有已经分配的buf数组。排列方式是按大小顺序存储。刚开始没有,只有returnBuf调用的时候才会回收回来放在这里。
mBuffersByLastUse里面存着现有已经分配的buf数组。但是排列方式是按照最近使用的先后存储。刚开始没有,只有returnBuf调用的时候才会回收回来放在这里。
这个存储列表的目的就是在下面的方法中:
**
* Removes buffers from the pool until it is under its size limit.
*/
private synchronized void trim() {
while (mCurrentSize > mSizeLimit) {
byte[] buf = mBuffersByLastUse.remove(0);
mBuffersBySize.remove(buf);
mCurrentSize -= buf.length;
}
}
一旦分配过的字节数组总量大小超过限定值,那么就按照最近最少使用的字节数组对象逐一清除。知道满足限定的最大字节大小。
**这样的一个字节数组池很有用。因为在频繁的网络请求中。如果不回收利用字节数组,那么可能出现内存波动。而且短时间内分配过的字节数组的堆空间不能及时释放。
直到下一次GC才能释放掉。而维护这样一个字节数组池就避免了反复的分配和释放字节数组的堆空间。所以会比较高效。
但是,这个字节数组的空间最大值不宜过大。
第一,这个字节数组用于流转换字节的缓冲buffer。一般不会过大。
第二,只要是分配过的字节数组,就相当于常驻在内存,过大会让内存持续被大量无效的字节数组对象占用。
第三,从这里拿出去的字节数组不一定会被回收,只要不掉用returnBuf方法。分配出去的字节数组就可以被释放。所以一般持续增长的情况不是很多。