第三章 索引
小结
- 火葬场用法 (用时一时爽,维护火葬场)
- 在loc[*, *] 中同时使用行索引和列索引,如df_demo.loc['Qiang Sun', 'Age']; 使用时需要指定列名和行索引名
- 使用df.query(),编译器没办法进行预测检查
- 使用链式赋值
- 在对表或者序列赋值时,应当在使用一层索引器后直接进行赋值操作,这样做是由于进行多次索引后赋值是赋在临时返回的 copy 副本上的,而没有真正修改元素从而报出 SettingWithCopyWarning 警告。
- 初写复杂修改语句的时候,比较容易遇见这种报错; 按照
A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value instead 的报错提示进行修改即可.
- 转换命令
- jupyter nbconvert --to markdown E:PycharmProjectsTianChiProject�0_山枫叶纷飞competitions�08_joyful-pandas�3_索引基础.ipynb
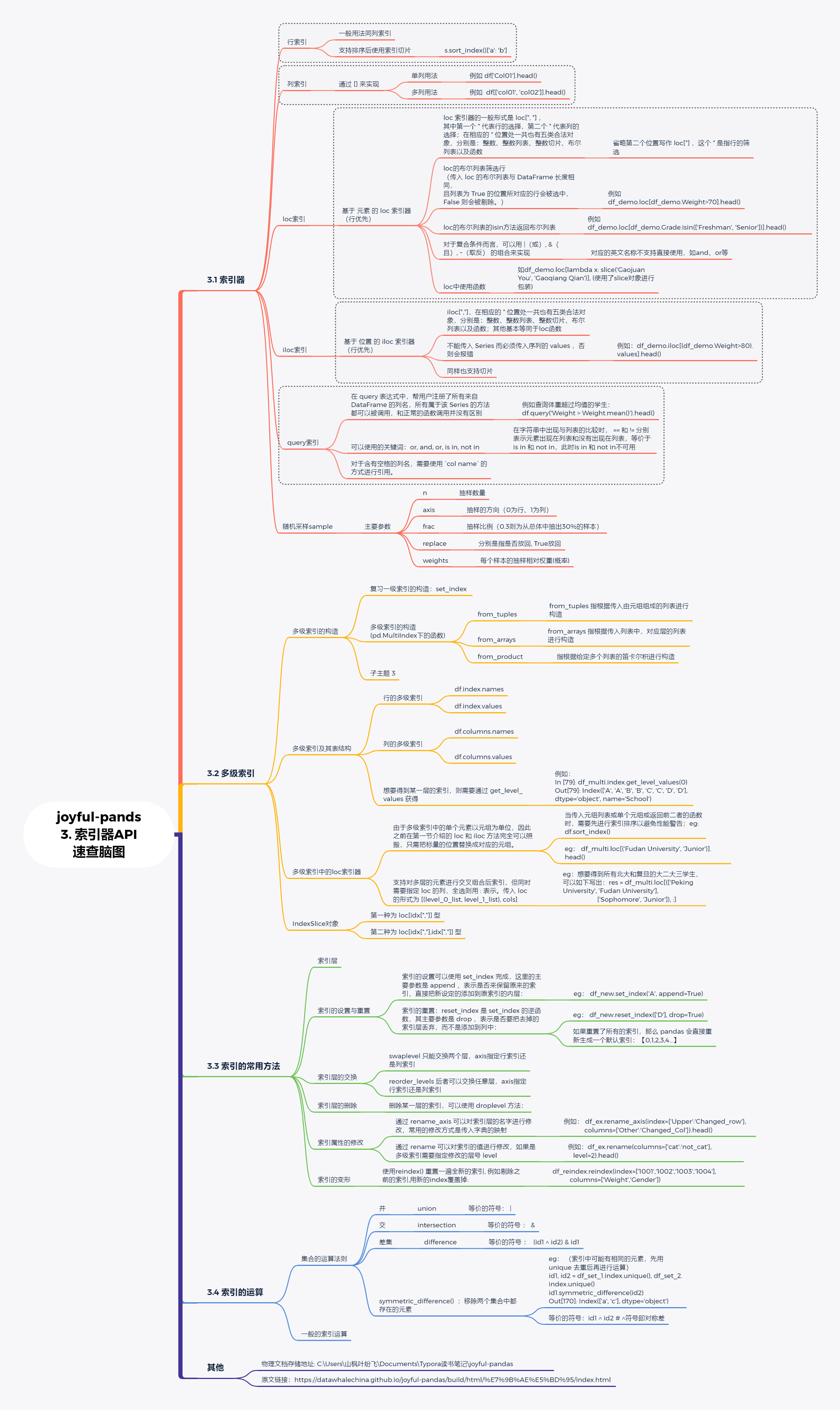
速查API脑图 (写成文章我以后肯定不会翻的,但脑图我可能会翻)
调包
import numpy as np
import pandas as pd
五、练习
Q1:公司员工数据集
现有一份公司员工数据集:
df = pd.read_csv('E:\PycharmProjects\DatawhaleChina\joyful-pandas\data\company.csv')
df.head(3)
|
EmployeeID |
birthdate_key |
age |
city_name |
department |
job_title |
gender |
| 0 |
1318 |
1/3/1954 |
61 |
Vancouver |
Executive |
CEO |
M |
| 1 |
1319 |
1/3/1957 |
58 |
Vancouver |
Executive |
VP Stores |
F |
| 2 |
1320 |
1/2/1955 |
60 |
Vancouver |
Executive |
Legal Counsel |
F |
df.columns
Index(['EmployeeID', 'birthdate_key', 'age', 'city_name', 'department',
'job_title', 'gender'],
dtype='object')
- 分别只使用
query和loc选出年龄不超过四十岁且工作部门为Dairy或Bakery的男性。
- 选出员工
ID号 为奇数所在行的第1、第3和倒数第2列。
print('1-1 使用query 火葬场式查询 选出年龄不超过四十岁且工作部门为`Dairy`或`Bakery`的男性。')
df.query("(age <= 40) and (department == ['Dairy', 'Bakery']) and (gender == 'M')")
|
EmployeeID |
birthdate_key |
age |
city_name |
department |
job_title |
gender |
| 3611 |
5791 |
1/14/1975 |
40 |
Kelowna |
Dairy |
Dairy Person |
M |
| 3613 |
5793 |
1/22/1975 |
40 |
Richmond |
Bakery |
Baker |
M |
| 3615 |
5795 |
1/30/1975 |
40 |
Nanaimo |
Dairy |
Dairy Person |
M |
| 3617 |
5797 |
2/3/1975 |
40 |
Nanaimo |
Dairy |
Dairy Person |
M |
| 3618 |
5798 |
2/4/1975 |
40 |
Surrey |
Dairy |
Dairy Person |
M |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 6108 |
8307 |
10/20/1994 |
21 |
Burnaby |
Dairy |
Dairy Person |
M |
| 6113 |
8312 |
11/12/1994 |
21 |
Burnaby |
Dairy |
Dairy Person |
M |
| 6137 |
8336 |
12/31/1994 |
21 |
Vancouver |
Dairy |
Dairy Person |
M |
| 6270 |
6312 |
5/14/1979 |
36 |
Grand Forks |
Dairy |
Dairy Person |
M |
| 6271 |
6540 |
2/14/1981 |
34 |
Victoria |
Bakery |
Baker |
M |
441 rows × 7 columns
print('1-2 使用`loc`选出年龄不超过四十岁且工作部门为`Dairy`或`Bakery`的男性。')
df.loc[((df['age'] <= 40) & df['department'].isin(['Dairy', 'Bakery']) & (df['gender'] == 'M'))]
loc 查询
|
EmployeeID |
birthdate_key |
age |
city_name |
department |
job_title |
gender |
| 3611 |
5791 |
1/14/1975 |
40 |
Kelowna |
Dairy |
Dairy Person |
M |
| 3613 |
5793 |
1/22/1975 |
40 |
Richmond |
Bakery |
Baker |
M |
| 3615 |
5795 |
1/30/1975 |
40 |
Nanaimo |
Dairy |
Dairy Person |
M |
| 3617 |
5797 |
2/3/1975 |
40 |
Nanaimo |
Dairy |
Dairy Person |
M |
| 3618 |
5798 |
2/4/1975 |
40 |
Surrey |
Dairy |
Dairy Person |
M |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 6108 |
8307 |
10/20/1994 |
21 |
Burnaby |
Dairy |
Dairy Person |
M |
| 6113 |
8312 |
11/12/1994 |
21 |
Burnaby |
Dairy |
Dairy Person |
M |
| 6137 |
8336 |
12/31/1994 |
21 |
Vancouver |
Dairy |
Dairy Person |
M |
| 6270 |
6312 |
5/14/1979 |
36 |
Grand Forks |
Dairy |
Dairy Person |
M |
| 6271 |
6540 |
2/14/1981 |
34 |
Victoria |
Bakery |
Baker |
M |
441 rows × 7 columns
print('2. 选出员工`ID`号 为奇数所在行的第1、第3和倒数第2列。')
df.iloc[((df['EmployeeID']+1)%2==0).values, [0,2,-2]]
2. 选出员工`ID`号 为奇数所在行的第1、第3和倒数第2列。
|
EmployeeID |
age |
job_title |
| 1 |
1319 |
58 |
VP Stores |
| 3 |
1321 |
56 |
VP Human Resources |
| 5 |
1323 |
53 |
Exec Assistant, VP Stores |
| 6 |
1325 |
51 |
Exec Assistant, Legal Counsel |
| 8 |
1329 |
48 |
Store Manager |
| ... |
... |
... |
... |
| 6276 |
7659 |
26 |
Cashier |
| 6277 |
7741 |
25 |
Cashier |
| 6278 |
7801 |
25 |
Dairy Person |
| 6280 |
8181 |
22 |
Cashier |
| 6281 |
8223 |
21 |
Cashier |
3126 rows × 3 columns
df.head()
|
EmployeeID |
birthdate_key |
age |
city_name |
department |
job_title |
gender |
| 0 |
1318 |
1/3/1954 |
61 |
Vancouver |
Executive |
CEO |
M |
| 1 |
1319 |
1/3/1957 |
58 |
Vancouver |
Executive |
VP Stores |
F |
| 2 |
1320 |
1/2/1955 |
60 |
Vancouver |
Executive |
Legal Counsel |
F |
| 3 |
1321 |
1/2/1959 |
56 |
Vancouver |
Executive |
VP Human Resources |
M |
| 4 |
1322 |
1/9/1958 |
57 |
Vancouver |
Executive |
VP Finance |
M |
print("""3. 按照以下步骤进行索引操作:
* 把后三列设为索引后交换内外两层
* 恢复中间一层
* 修改外层索引名为`Gender`
* 用下划线合并两层行索引
* 把行索引拆分为原状态
* 修改索引名为原表名称
* 恢复默认索引并将列保持为原表的相对位置""")
last_three_index= list(df.columns)[-3:]
df_2 = df.copy()
df_2 = df_2.set_index(last_three_index).swaplevel(0,2) # 默认按axis=0
df_2.reset_index(level=1, inplace=True)
# * 修改外层索引名为`Gender`
df_2.rename_axis(index={'gender':'Gender'}, inplace=True)
# df_2.head()
# * 用下划线合并两层行索引
df_2.index = df_2.index.map(lambda x:'_'.join(x))
# * 把行索引拆分为原状态
df_2.index = df_2.index.map(lambda x:tuple(str(x).split('_')))
# * 修改索引名为原表名称
df_2 = df_2.rename_axis(index=['gender', 'department'])
# * 恢复默认索引并将列保持为原表的相对位置
df_2 = df_2.reset_index().reindex(df.columns, axis=1)
df_2.head()
3. 按照以下步骤进行索引操作:
* 把后三列设为索引后交换内外两层
* 恢复中间一层
* 修改外层索引名为`Gender`
* 用下划线合并两层行索引
* 把行索引拆分为原状态
* 修改索引名为原表名称
* 恢复默认索引并将列保持为原表的相对位置
|
EmployeeID |
birthdate_key |
age |
city_name |
department |
job_title |
gender |
| 0 |
1318 |
1/3/1954 |
61 |
Vancouver |
Executive |
CEO |
M |
| 1 |
1319 |
1/3/1957 |
58 |
Vancouver |
Executive |
VP Stores |
F |
| 2 |
1320 |
1/2/1955 |
60 |
Vancouver |
Executive |
Legal Counsel |
F |
| 3 |
1321 |
1/2/1959 |
56 |
Vancouver |
Executive |
VP Human Resources |
M |
| 4 |
1322 |
1/9/1958 |
57 |
Vancouver |
Executive |
VP Finance |
M |
df_2.equals(df)
True
Q2:巧克力数据集
现有一份关于巧克力评价的数据集:
df = pd.read_csv('E:\PycharmProjects\DatawhaleChina\joyful-pandas\data\chocolate.csv')
df.head(3)
|
Company |
Review
Date |
Cocoa
Percent |
Company
Location |
Rating |
| 0 |
A. Morin |
2016 |
63% |
France |
3.75 |
| 1 |
A. Morin |
2015 |
70% |
France |
2.75 |
| 2 |
A. Morin |
2015 |
70% |
France |
3.00 |
- 把列索引名中的
替换为空格。
df.columns = [' '.join(i.split('
')) for i in list(df.columns)]
df.head(3)
|
Company |
Review Date |
Cocoa Percent |
Company Location |
Rating |
| 0 |
A. Morin |
2016 |
63% |
France |
3.75 |
| 1 |
A. Morin |
2015 |
70% |
France |
2.75 |
| 2 |
A. Morin |
2015 |
70% |
France |
3.00 |
- 巧克力
Rating评分为1至5,每0.25分一档,请选出2.75分及以下且可可含量Cocoa Percent高于中位数的样本。
df['Cocoa Percent'] = df['Cocoa Percent'].apply(lambda x : float(str(x).split('%')[0])/100)
df.loc[(df.Rating<2.75) & (df['Cocoa Percent'] > np.median(df['Cocoa Percent']) )]
|
Company |
Review Date |
Cocoa Percent |
Company Location |
Rating |
| 38 |
Alain Ducasse |
2013 |
0.0075 |
France |
2.50 |
| 39 |
Alain Ducasse |
2013 |
0.0075 |
France |
2.50 |
| 96 |
Ara |
2014 |
0.0072 |
France |
2.50 |
| 125 |
Artisan du Chocolat |
2010 |
0.0100 |
U.K. |
1.75 |
| 130 |
Artisan du Chocolat |
2009 |
0.0075 |
U.K. |
2.50 |
| ... |
... |
... |
... |
... |
... |
| 1720 |
Vintage Plantations (Tulicorp) |
2007 |
0.0100 |
U.S.A. |
2.00 |
| 1721 |
Vintage Plantations (Tulicorp) |
2007 |
0.0090 |
U.S.A. |
2.00 |
| 1734 |
Whittakers |
2011 |
0.0072 |
New Zealand |
2.50 |
| 1735 |
Wilkie's Organic |
2013 |
0.0075 |
Ireland |
2.50 |
| 1741 |
Willie's Cacao |
2013 |
0.0100 |
U.K. |
2.25 |
110 rows × 5 columns
- 将
Review Date和Company Location设为索引后,
选出Review Date在2012年之后且Company Location不属于France, Canada, Amsterdam, Belgium的样本。
df_copy = df.set_index(['Review Date', 'Company Location']).sort_index(level=0)
df.loc[(df['Review Date']>=2012) & (~df['Company Location'].isin(['France', 'Canada', 'Amsterdam', 'Belgium']))]
|
Company |
Review Date |
Cocoa Percent |
Company Location |
Rating |
| 23 |
Acalli |
2015 |
0.0070 |
U.S.A. |
3.75 |
| 24 |
Acalli |
2015 |
0.0070 |
U.S.A. |
3.75 |
| 40 |
Alexandre |
2017 |
0.0070 |
Netherlands |
3.50 |
| 41 |
Alexandre |
2017 |
0.0070 |
Netherlands |
3.50 |
| 42 |
Alexandre |
2017 |
0.0070 |
Netherlands |
3.50 |
| ... |
... |
... |
... |
... |
... |
| 1785 |
Zotter |
2012 |
0.0075 |
Austria |
3.00 |
| 1786 |
Zotter |
2012 |
0.0090 |
Austria |
3.25 |
| 1787 |
Zotter |
2012 |
0.0070 |
Austria |
3.75 |
| 1788 |
Zotter |
2012 |
0.0068 |
Austria |
3.25 |
| 1789 |
Zotter |
2012 |
0.0058 |
Austria |
3.50 |
972 rows × 5 columns