前面突然想起一个问题,我们常说栈的存储是先进后出,那么事件循环里面的事件为啥是先进先执行的呢,这不是和栈存储方式向驳论了吗,还有所谓的宏任务和微任务的调用优先级之分是如何处理的呢,基于弄清楚其中的具体流程和机制,这里做一份总结记录
背景
JS是单线程
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。(在JAVA和c#中的异步均是通过多线程实现的,没有循环队列一说,直接在子线程中完成相关的操作)
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质
-
JS解析线程 (javaScript属于单线程,每次只能去处理一件事)
-
GUI渲染线程 (可以理解成解析加载css tree和 dom tree,生成render tree生成页面,包括重绘都是会触发GUI线程,与此同时 ,GUI线程和JS主线程是互斥的,即不能同时存在)
-
网络请求线程 (它可以异步处理http请求,请求回来的数据仍在事件队列线程中,等JS线程空下来之后, 才会推到JS线程中执行, 属于微任务)
-
定时器线程 ( 指的是setTimeout,setInterval,JS线程没办法读秒,所以读秒的任务就是定时器线程在做, 定时器属于宏任务)
-
事件队列线程 ( 这个线程指的是异步回调结束之后, 暂时放在这个线程中,等待JS线程空下来后再次执行 )
如下:
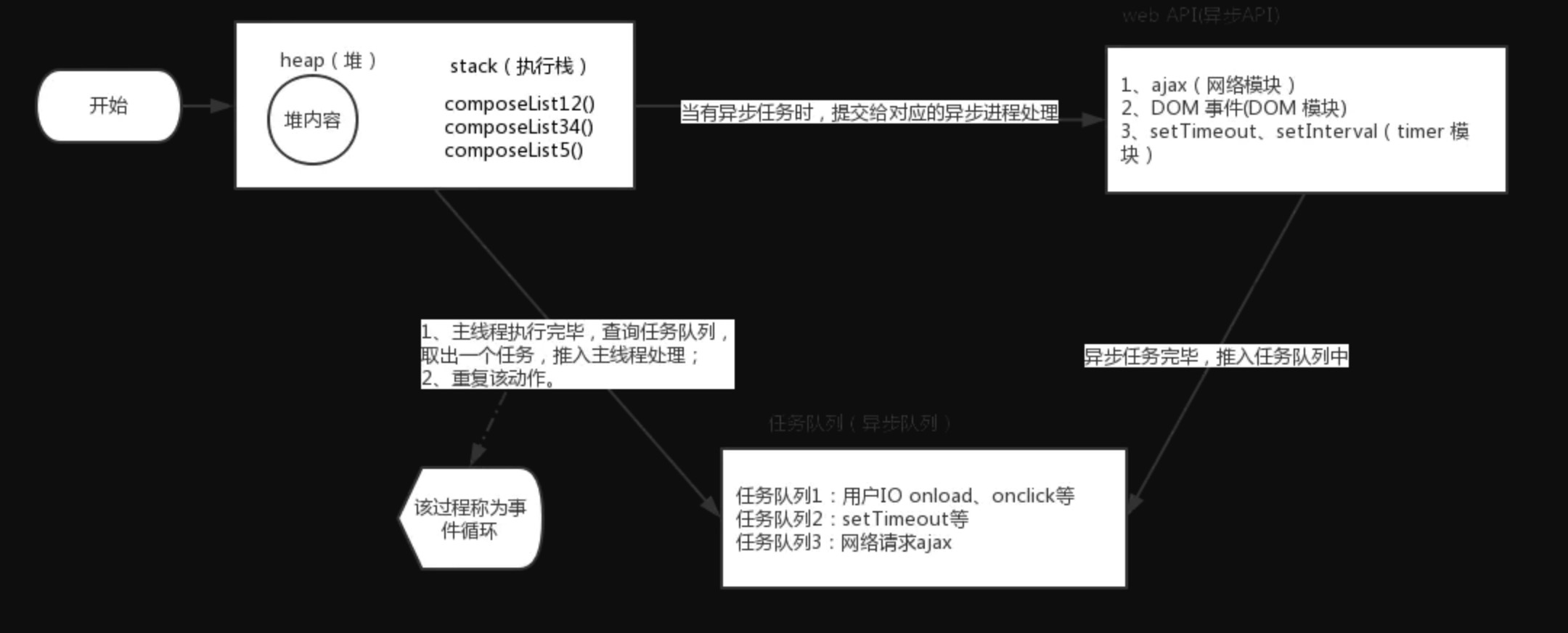
JS的异步是通过回调函数实现的,即通过任务队列,在主线程执行完当前的任务栈(所有的同步操作),主线程空闲后轮询任务队列,并将任务队列中的任务(回调函数)取出来执行。"回调函数"(callback),就是那些会被主线程挂起来的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
虽然JS是单线程的但是浏览器的内核是多线程的,在浏览器的内核中不同的异步操作由不同的浏览器内核模块调度执行,异步操作会将相关回调添加到任务队列中。而不同的异步操作添加到任务队列的时机也不同,如 onclick, setTimeout, ajax 处理的方式都不同,这些异步操作是由浏览器内核的 webcore 来执行的,webcore 包含上图中的3种 webAPI,分别是 DOM Binding、network、timer模块
-
-
setTimeout 会由浏览器内核的 timer 模块来进行延时处理,当时间到达的时候,才会将回调函数添加到任务队列中
-
ajax 则会由浏览器内核的 network 模块来处理,在网络请求完成返回之后,才将回调添加到任务队列中
总结得出异步运行机制如下:
-
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)
-
主线程之外,还存在一个"任务队列"(task queue),只要异步任务有了运行结果,就在"任务队列"之中放置一个事件
-
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行
-
主线程不断重复上面的第三步
只要主线程空了,就会去读取"任务队列",这就是JavaScript的运行机制。这个过程会不断重复。(该过程又称之为事件轮询)
执行栈
所有的 JS 代码在运行时都是在执行上下文中进行的。执行上下文是一个抽象的概念,JS 中有三种执行上下文:
-
全局执行上下文,默认的,在浏览器中是 window 对象,并且 this 在非严格模式下指向它
-
函数执行上下文,JS 的函数每当被调用时会创建一个上下文
-
Eval 执行上下文,eval 函数会产生自己的上下文,这里不讨论
通常,我们的代码中都不止一个上下文,那这些上下文的执行顺序应该是怎样的?从上往下依次执行?
栈,是一种数据结构,具有先进后出的原则。JS 中的执行栈就具有这样的结构,当引擎第一次遇到 JS 代码时,会产生一个全局执行上下文并压入执行栈,每遇到一个函数调用,就会往栈中压入一个新的上下文。引擎执行栈顶的函数,执行完毕,弹出当前执行上下文
function foo() {
console.log('1')
bar();
console.log('3')
}
function bar() {
console.log('2')
}
foo()
以引例来说明。当 foo() 函数被调用,将 foo 函数的执行上下文压入执行栈,接着执行输出 ‘1’;当 bar() 函数被调用,将 bar 函数的执行上下文压入执行栈,接着执行输出 ‘2’;bar() 执行完毕,被弹出执行栈,foo() 函数接着执行,输出 ‘3’;foo() 函数执行完毕,被弹出执行栈
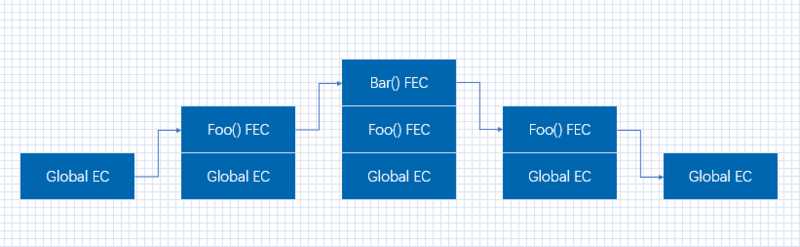
调用堆栈顾名思义是一个具有LIFO(后进先出)结构的堆栈,用于存储在代码执行期间创建的所有执行上下文
JS 只有一个调用栈,因为它是一种单线程编程语言,调用堆栈具有 LIFO 结构,这意味着项目只能从堆栈顶部添加或删除
回到代码,尝试理解代该码是如何在JS引擎中执行
const second = () => {
console.log('Hello there!')
}
const first = () => {
console.log('Hi there!')
second();
console.log('The End')
}
first()
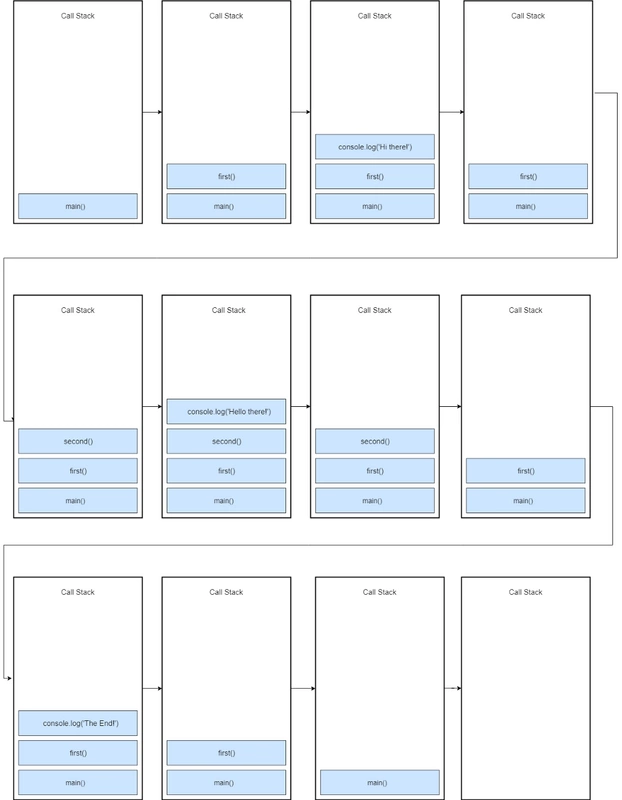
接下来,console.log('Hi there!')被推送到堆栈的顶部,当它完成时,它会从堆栈中弹出。之后,我们调用second(),因此second()函数被推到堆栈的顶部
console.log('Hello there!')被推送到堆栈顶部,并在完成时弹出堆栈。second() 函数结束,因此它从堆栈中弹出
console.log(“the End”)被推到堆栈的顶部,并在完成时删除。之后,first()函数完成,因此从堆栈中删除它
程序在这一点上完成了它的执行,所以全局执行上下文(main())从堆栈中弹出
可以看出其实执行栈和调用堆栈是可以相互嵌套的
事件轮询的工作是监听调用堆栈,并确定调用堆栈是否为空。如果调用堆栈是空的,它将检查消息队列,看看是否有任何挂起的回调等待执行
在这种情况下,消息队列包含一个回调,此时调用堆栈为空。因此,事件轮询将回调推到堆栈的顶部
然后是 console.log(“Async Code”) 被推送到堆栈顶部,执行并从堆栈中弹出。此时,回调已经完成,因此从堆栈中删除它,程序最终完成
消息队列还包含来自DOM事件(如单击事件和键盘事件)的回调。例如:
document.querySelector('.btn').addEventListener('click',(event) => {
console.log('Button Clicked')
})
对于DOM事件,事件侦听器位于web api环境中,等待某个事件(在本例中单击event)发生,当该事件发生时,回调函数被放置在等待执行的消息队列中
同样,事件轮询检查调用堆栈是否为空,并在调用堆栈为空并执行回调时将事件回调推送到堆栈
在JS中ES6 中新增的任务队列(promise)是在事件循环之上的,事件循环每次 tick 后会查看 ES6 的任务队列中是否有任务要执行,也就是 ES6 的任务队列比事件循环中的任务(事件)队列优先级更高
如 Promise 就使用了 ES6 的任务队列特性。也即在执行完任务栈后首先执行的是任务队列中的promise任务,也就是我们常说的微任务。其他的上面常见的异步操作加入队列的时间没有相应的优先级
总结
所以开文所说的栈的存储先进后出没有错,因为我们的调用堆栈就是这么存储的,事件的优先级和栈的存储关系并不大,因为事件未推入调用堆栈前是使用队列来存储的,所以并未驳论