参考链接:
通常,我们要统计一个字段有几种值有两种方法:在语句中使用DISTINCT或者GROUP BY,配合count进行查询。
例如:
SELECT count(DISTINCT col) FROM table;
SELECT count(1) FROM (SELECT 1 FROM table GROUP BY col) alias;那么这两者的效率究竟如何呢?网上的答案可谓前篇一律,大多说GROUP BY更胜一筹!对此,DISTINCT表示不服,那我是不是白活了!
今天我们就来了解一下这两者的实现原理,最后才能知道它们究竟有啥区别。
DISTINCT:这种方式会将全部内容存储在一个hash结构里,最后通过计算hash结构中key的个数即可得到结果,典型的以空间换取时间的方式。
GROUP BY:这种方式是先将字段排序(一般使用sort),然后进行计数,典型的以时间换取空间。
了解原理之后,我们可以得出,
| 数据越是离散,DISTINCT需要消耗的空间越大,效率也就越低,此时GROUP BY的空间优势就显现了;相反,数据越是集中,DISTINCT空间占用变小,时间优势就显现出来了。 |
但是,空口无凭,我们需要动手证明。
第一步,创建一张测试表:
CREATE TABLE `comments` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` int(10) unsigned NOT NULL COMMENT '用户uid',
`aid` int(8) NOT NULL COMMENT '文章aid',
`content` text CHARACTER SET utf8mb4 NOT NULL COMMENT '发表内容',
`picture` varchar(255) NOT NULL DEFAULT '' COMMENT '图片',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '显示状态 0:不显示 1:显示',
`qid` int(10) NOT NULL DEFAULT '0' COMMENT '引用id',
`praise_num` int(10) NOT NULL DEFAULT '0' COMMENT '被赞数',
`floor_num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '楼层',
`ip` int(10) NOT NULL COMMENT 'ip地址',
`update_time` int(10) unsigned NOT NULL COMMENT '发表时间',
`create_time` int(10) unsigned NOT NULL COMMENT '发表时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;第二步,写入500万条记录
一些测试的关键字段总数如下: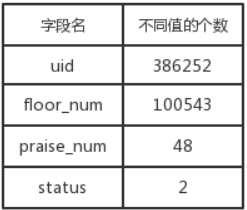
第三步,对上面的四个字段分别进行测试:
status字段
A: SELECT count(DISTINCT status) FROM comments;
B: SELECT count(1) FROM (SELECT 1 FROM comments GROUP BY status) alias;分别执行100次,A语句的平均耗时为0.882秒,B语句的平均耗时为1.257秒
praise_num字段
A: SELECT count(DISTINCT praise_num) FROM comments;
B: SELECT count(1) FROM (SELECT 1 FROM comments GROUP BY praise_num) alias;分别执行100次,A语句的平均耗时为1.589秒,B语句的平均耗时为1.848秒
floor_num字段
A: SELECT count(DISTINCT floor_num) FROM comments;
B: SELECT count(1) FROM (SELECT 1 FROM comments GROUP BY floor_num) alias;分别执行100次,A语句的平均耗时为1.840秒,B语句的平均耗时为1.811秒
uid字段
A: SELECT count(DISTINCT uid) FROM comments;
B: SELECT count(1) FROM (SELECT 1 FROM comments GROUP BY uid) alias;分别执行100次,A语句的平均耗时为3.003秒,B语句的平均耗时为1.927秒
以上测试表明,我们得出的结论是正确的,实际应用中要使用哪个,还得根据实际情况来决定。