2018-10-5 14:47:57
越努力越幸运!永远不要高估自己!
ORM的聚合和分组查询!!!
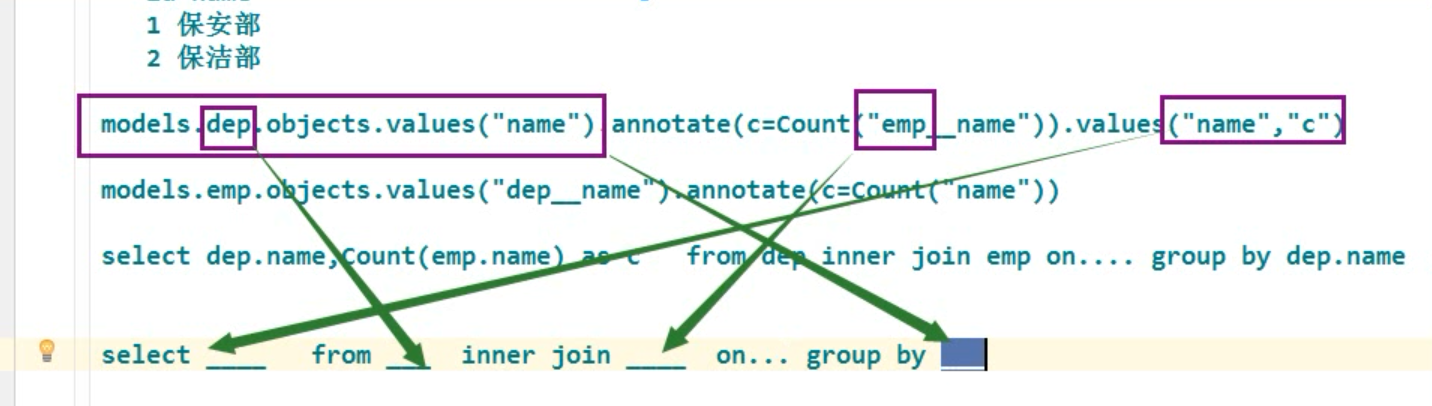
# #####################聚合和分组############################ #####################聚合 # 查询所有书籍的价格 from django.db.models import Sum, Count, Avg ret = models.Bool.objects.all().aggregate(price_sum=Sum("price")) print(ret) # {'price_sum': 'Decimal('554.00')'} # 查询所有作者的平均年龄 ret = models.Author.objects.all().aggregate(age_avg=Avg("age")) ####----------------------------------------分组 """ 单表分组 emp id name age dep 1 alex 22 保安部 2 egon 33 保安部 1 wenzhou 44 保洁部 sql select Count(id) from emp group by dep; orm : 对象关系映射 models.emp.objects.values("dep").annotate(c=Count("id")) # 哪个字段分组,就values谁,然候count 任意一个字段就好了 ######################################################## emp id name age dep_id 1 alex 22 1 2 egon 33 1 1 wenzhou 44 2 dep id name 1 保安部 2 保洁部 查询每一个部门的人数 sql: select * from emp inner join dep on emp.dep_id= dep.id id name age dep_id dep.id dep.name 1 alex 22 1 1 保安部 2 egon 33 1 1 保安部 1 wenzhou 44 2 2 保洁部 select * from emp inner join dep on emp.dep_id= dep.id group by dep.id, dep.name ORM: 关键点: 1. query对象.annotate() 2. annotate进行分组统计,按照前面select的字段进行group by 3. annotate() 返回值依然是queryset对象, 增加了分组统计之后的键值对 # 先join 表 基表是dep ,然后得到emp里面拿到name数据,跨表 反向 写表名小写,,和queryset跨表查数据一样 models.dep.objects.all().annotate(Count("emp__name")) models.dep.objects.values("name").annotate(c=Count("emp_name")).values("name", "c") # 反向查询 models.emp.objects.values("dep__name").annotate(c=Count("name")).values("dep_name", "c")) # 正向查询 sql selcet dep.name, Count(emp.name) as c from dep inner join emp on .......... group by dep.name; 分组查询 先有个轮廓 select Count(emp.name) as c , dep.name from emp inner join dep on .... group by dep.name; select _____ from ____ inner join______ on ........ group by _______________ """ # 查询每一个作者的名字以及出版过的最高价格的书 from djang.db.models import Sum, Count, Max, Avg ret = models.Author.objects.values("name").annotate(max_price=Max("book_price")).values("name",max_price) """ select Max(book.price) as max_price from author inner join book_authors on .... inner join book on..... group by author.name; """ # 查询每一个出版社出版过的书籍的平均价格 # 可以按字段.values("") 也可以直接 .all() models.Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name", "avg_price") # 查询每一本书籍的作者个数 modes.Book.values("title").annotate(c=Count("authors__name")).values("title","c") # 查询每一个分类的名称以及对应的文章数 models.Category.objects.all().annotate(c=Count("articles__title")).values("title", "c") # 统计不止一个作者的图书名称 """ sql: # 先分组再统计 select book.title, Count(author.name) as c from book inner join book-authors on .... inner join author on .... group by book.id having c >1; """ # filter () 在这里翻译成 having 的意思,,以前的都翻译成 where models.Book.objects.all().annotate(c=Count("authors__name")).filter(c__gt=1).values("title", "c")