ORM聚合函数详解-aggregate和annotate:
aggregate和annotate的区别:
1、aggregate :返回使用聚合函数后的字段和值。
2、annotate :在原来模型字段的基础之上添加一个使用了聚合函数的字段,并且在使用聚合函数的时候,会使用当前这个模型的主键进行分组(group by)。比如以上 Sum 的例子,如果使用的是 annotate ,那么将在每条图书的数据上都添加一个字段叫做 total ,计算这本书的销售总额。而如果使用的是 aggregate ,那么将求所有图书的销售总额。
下面是需求是(基于上节课程情况),求每本书多少钱卖出去的:
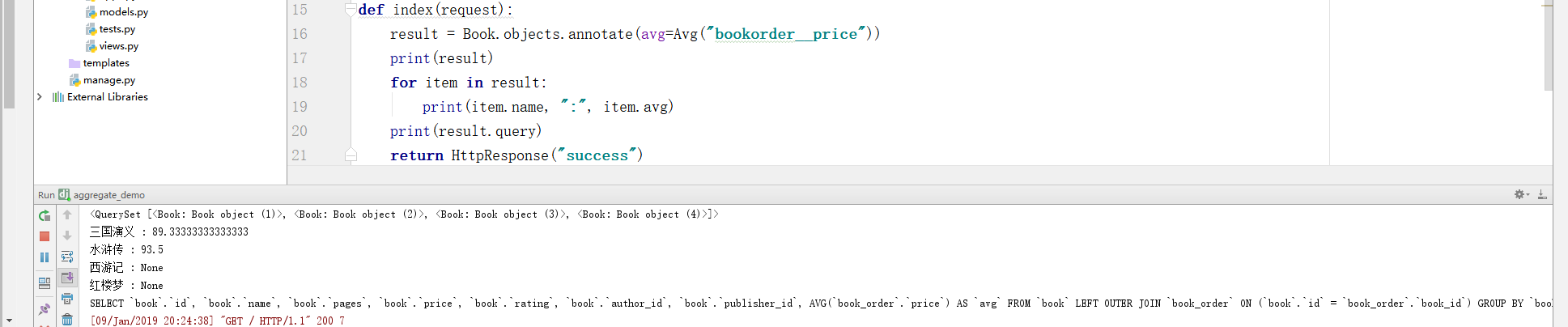
def index(request): result = Book.objects.annotate(avg=Avg("bookorder__price")) print(result) for item in result: print(item.name, ":", item.avg) print(result.query) return HttpResponse("success")
结果是:
<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>]> 三国演义 : 89.33333333333333 水浒传 : 93.5 西游记 : None 红楼梦 : None SELECT `book`.`id`, `book`.`name`, `book`.`pages`, `book`.`price`, `book`.`rating`, `book`.`author_id`, `book`.`publisher_id`, AVG(`book_order`.`price`) AS `avg` FROM `book` LEFT OUTER JOIN `book_order` ON (`book`.`id` = `book_order`.`book_id`) GROUP BY `book`.`id` ORDER BY NULL
实例截图如下: