You Only Look Once: Unified, Real-Time Object Detection
前言
近几年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),他们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region proposal上做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。第一类方法是准确率高一些,但是速度慢,但是第二类算法是速度快,但是准确率要低一些。这里我们谈的是Yolo-v1版本算法,其性能是差于后来的SSD算法的,但是Yolo后来也继续进行改进,产生了Yolo9000算法。本文主要讲述Yolo-v1算法的原理,特别是算法的训练与预测中详细细节,最后将给出如何使用TensorFlow实现Yolo算法。
滑动窗口与CNN
在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图1所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。

如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图2所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-cNN算法。
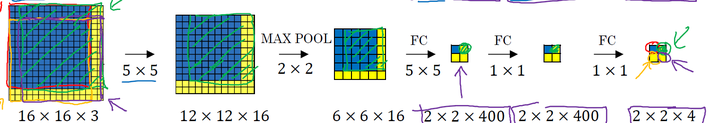
上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念。
设计理念
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图3所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。
相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

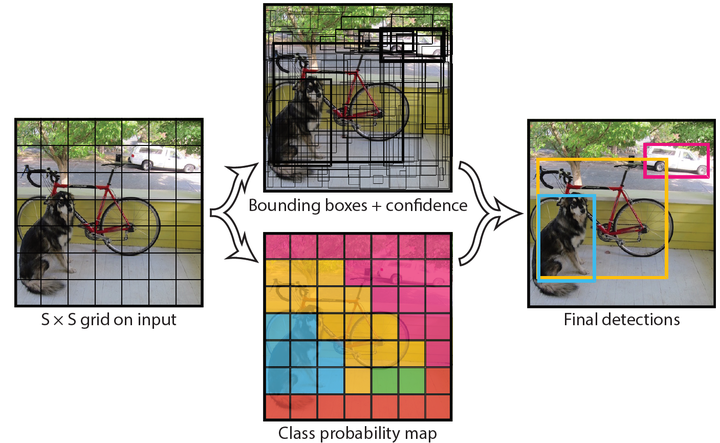
具体来说,Yolo的CNN网络将输入的图片分割成 S*S 网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图4所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测 B 个边界框(bounding box)以及边界框的置信度(confidence score)。
所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为$Pr(object)$ ,当该边界框是背景时(即不包含目标),此时 $Pr(object)=0$。而当该边界框包含目标时, $Pr(object)=1$ 。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为$IOU_{pred}^{truth}$ 。因此置信度可以定义为 $Pr(object)*IOU_{pred}^{truth}$ 。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:$(x,y,w,h)$ ,其中$(x,y)$是边界框的中心坐标,而 $w$和 $h$ 是边界框的宽与高。还有一点要注意,中心坐标的预测值 (x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图4所示。而边界框的 $w$ 和 $h$ 预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在 [0,1] 范围。这样,每个边界框的预测值实际上包含5个元素:$(x,y,w,h,c)$ ,其中前4个表征边界框的大小与位置,而最后一个值是置信度。

还有分类问题,对于每一个单元格其还要给出预测出 [公式] 个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率,即 [公式] 。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores): $Pr(class_{i}|object)Pr(object)IOU_{pred}{truth}=Pr(class_{i})*IOU_{pred}{truth}$ 。
边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。后面会说,一般会根据类别置信度来过滤网络的预测框。
总结一下,每个单元格需要预测$(B5+C)$个值。如果将输入图片划分为$(SS)$网格,那么最终预测值为$(SS(B5+C))$大小的张量。整个模型的预测值结构如下图所示。对于PASCAL VOC数据,其共有20个类别,如果使用 $S=7$,$B=2$ ,那么最终的预测结果就是 $77*30$ 大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
网络设计
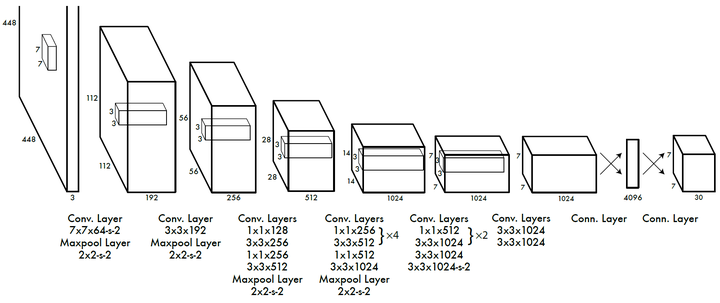
Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图8所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:$max(x,0.1x)$ 。但是最后一层却采用线性激活函数。
可以看到网络的最后输出为 $7 imes7 imes30$ 大小的张量。这和前面的讨论是一致的。这个张量所代表的具体含义如图7所示。对于每一个单元格,前20个元素是类别概率值,然后2个元素是边界框置信度,两者相乘可以得到类别置信度,最后8个元素是边界框的 $(x,y,w,h)$.大家可能会感到奇怪,对于边界框为什么把置信度 $(x,y,w,h)$ 和 $c$ 都分开排列,而不是按照 $(x,y,w,h,c)$ 这样排列,其实纯粹是为了计算方便,因为实际上这30个元素都是对应一个单元格,其排列是可以任意的。但是分离排布,可以方便地提取每一个部分。这里来解释一下,首先网络的预测值是一个二维张量 $P$,其shape为$[batch,7 imes7 imes30]$.采用切片,那么$ P_{[:,0:7 imes7 imes30]}$就是类别概率部分,而$P_{[:,7 imes7 imes30:7 imes7 imes(20+2)]}$是置信部分,最后部分$ P_{[:,7 imes7 imes(20+2):]}$是边界框的预测结果。这样,提取每个部分是非常方便的,这会方便后面的训练及预测时的计算。

网络训练
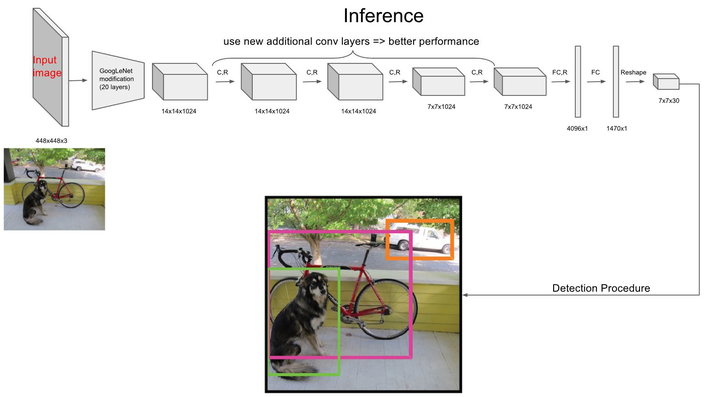
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图6中前20个卷积层,然后添加一个average-pool层和全连接层。预训练好的模型,在ImageNet 2012验证集上获得了88%的精准率。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。整个网络的流程如下图所示:
下面是损失函数的分析,Yolo算法采用的是平方和误差,因为它很容易进行优化,但是它并不完全符合最大化平均精度,它将局部化误差与分类误差同等加权,而在每个图像中,许多网格单元不包含任何对象,将这些单元格的“置信度”分数减少到0,通常也会减少包含对象单元格的渐变,容易导致模型不稳定,从而导致训练早期发生分歧,所以Yolo增加了边界框坐标预测的损失,并减少了不包含对象的框的置信度预测损失,使用两个参数$lambda_{coord}=5$和$lambda_{noobj}=0.5$来实现。平方和误差中同样包含对不同大小边界框的坐标误差,但是实际上较小的边界框的坐标误差应该要比比较大的边界框要敏感,为了解决这一点,这里使用的是预测边界框宽度和高度的平方根,而不是宽度和高度,即预测值变为$(x,y,sqrt{w},sqrt{h})$ 另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,坐标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
综上讨论,最终的损失函数计算如下:

在训练的时候使用动态变化的学习率:对于第一个epoch,慢慢将学习率从$10{{-3}}$提高到$10{{-2}}$,这里是为了避免从高学习率开始训练,从而模型由于不稳定的梯度而发散,然后继续使用$10{{-2}}$训练75个epoch,然后使用$10{{-3}}$训练30个epoch,最后使用$10^{{-4}}$训练30个epoch
Yolo的TF实现
Yolo的源码是用C实现的,但是好在Github上有很多开源的TF复现。这里我们参考gliese581gg的YOLO_tensorflow的实现来分析Yolo的Inference实现细节。我们的代码将构建一个end-to-end的Yolo的预测模型,利用的已经训练好的权重文件,你将可以用自然的图片去测试检测效果。
import tensorflow as tf
import numpy as np
import cv2
# !pip install -i https://pypi.douban.com/simple opencv-python
def leak_relu(x, alpha=0.1):
return tf.maximum(alpha * x,x)
class Yolo(object):
def __init__(self, weights_file):
self.verbose = True # #一个开关,打开时,打印清晰的训练数据
# detection params
self.S = 7 # cell size
self.B = 2 # boxes_per_cell
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train","tvmonitor"]
self.C = len(self.classes) # number of classes
# offset for box center (top left point of each cell)
self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)]*self.S*self.B),
[self.B, self.S, self.S]), [1, 2, 0])
self.y_offset = np.transpose(self.x_offset, [1, 0, 2])
self.threshold = 0.2 # confidence scores threshold
self.iou_threshold = 0.5
self.sess = tf.Session()
self._build_net()
self._load_weights(weights_file)
def _build_net(self):
"""build the network"""
if self.verbose:
print("Start to build the network ...")
self.images = tf.placeholder(tf.float32, [None, 448, 448, 3])
net = self._conv_layer(self.images, 1, 64, 7, 2)
net = self._maxpool_layer(net, 1, 2, 2)
net = self._conv_layer(net, 2, 192, 3, 1)
net = self._maxpool_layer(net, 2, 2, 2)
net = self._conv_layer(net, 3, 128, 1, 1)
net = self._conv_layer(net, 4, 256, 3, 1)
net = self._conv_layer(net, 5, 256, 1, 1)
net = self._conv_layer(net, 6, 512, 3, 1)
net = self._maxpool_layer(net, 6, 2, 2)
net = self._conv_layer(net, 7, 256, 1, 1)
net = self._conv_layer(net, 8, 512, 3, 1)
net = self._conv_layer(net, 9, 256, 1, 1)
net = self._conv_layer(net, 10, 512, 3, 1)
net = self._conv_layer(net, 11, 256, 1, 1)
net = self._conv_layer(net, 12, 512, 3, 1)
net = self._conv_layer(net, 13, 256, 1, 1)
net = self._conv_layer(net, 14, 512, 3, 1)
net = self._conv_layer(net, 15, 512, 1, 1)
net = self._conv_layer(net, 16, 1024, 3, 1)
net = self._maxpool_layer(net, 16, 2, 2)
net = self._conv_layer(net, 17, 512, 1, 1)
net = self._conv_layer(net, 18, 1024, 3, 1)
net = self._conv_layer(net, 19, 512, 1, 1)
net = self._conv_layer(net, 20, 1024, 3, 1)
net = self._conv_layer(net, 21, 1024, 3, 1)
net = self._conv_layer(net, 22, 1024, 3, 2)
net = self._conv_layer(net, 23, 1024, 3, 1)
net = self._conv_layer(net, 24, 1024, 3, 1)
net = self._flatten(net)
net = self._fc_layer(net, 25, 512, activation=leak_relu)
net = self._fc_layer(net, 26, 4096, activation=leak_relu)
net = self._fc_layer(net, 27, self.S*self.S*(self.C+5*self.B))
self.predicts = net
def _conv_layer(self, x, id, num_filters, filter_size, stride):
"""Conv layer"""
in_channels = x.get_shape().as_list()[-1]
weight = tf.Variable(tf.truncated_normal([filter_size, filter_size,
in_channels, num_filters], stddev=0.1))
bias = tf.Variable(tf.zeros([num_filters,]))
# padding, note: not using padding="SAME"
pad_size = filter_size // 2
pad_mat = np.array([[0, 0], [pad_size, pad_size], [pad_size, pad_size], [0, 0]])
x_pad = tf.pad(x, pad_mat)
conv = tf.nn.conv2d(x_pad, weight, strides=[1, stride, stride, 1], padding="VALID")
output = leak_relu(tf.nn.bias_add(conv, bias))
if self.verbose:
print(" Layer %d: type=Conv, num_filter=%d, filter_size=%d, stride=%d, output_shape=%s"
% (id, num_filters, filter_size, stride, str(output.get_shape())))
return output
def _fc_layer(self, x, id, num_out, activation=None):
"""fully connected layer"""
num_in = x.get_shape().as_list()[-1]
weight = tf.Variable(tf.truncated_normal([num_in, num_out], stddev=0.1))
bias = tf.Variable(tf.zeros([num_out,]))
output = tf.nn.xw_plus_b(x, weight, bias)
if activation:
output = activation(output)
if self.verbose:
print(" Layer %d: type=Fc, num_out=%d, output_shape=%s"
% (id, num_out, str(output.get_shape())))
return output
def _maxpool_layer(self, x, id, pool_size, stride):
output = tf.nn.max_pool(x, [1, pool_size, pool_size, 1],
strides=[1, stride, stride, 1], padding="SAME")
if self.verbose:
print(" Layer %d: type=MaxPool, pool_size=%d, stride=%d, output_shape=%s"
% (id, pool_size, stride, str(output.get_shape())))
return output
def _flatten(self, x):
"""flatten the x"""
tran_x = tf.transpose(x, [0, 3, 1, 2]) # channle first mode
nums = np.product(x.get_shape().as_list()[1:])
return tf.reshape(tran_x, [-1, nums])
def _load_weights(self, weights_file):
"""Load weights from file"""
if self.verbose:
print("Start to load weights from file:%s" % (weights_file))
saver = tf.train.Saver()
saver.restore(self.sess, weights_file)
def detect_from_file(self, image_file, imshow=True, deteted_boxes_file="boxes.txt",
detected_image_file="detected_image.jpg"):
"""Do detection given a image file"""
# read image
image = cv2.imread(image_file)
img_h, img_w, _ = image.shape
predicts = self._detect_from_image(image)
predict_boxes = self._interpret_predicts(predicts, img_h, img_w)
self.show_results(image, predict_boxes, imshow, deteted_boxes_file, detected_image_file)
def _detect_from_image(self, image):
"""Do detection given a cv image"""
img_resized = cv2.resize(image, (448, 448))
img_RGB = cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB)
img_resized_np = np.asarray(img_RGB)
_images = np.zeros((1, 448, 448, 3), dtype=np.float32)
_images[0] = (img_resized_np / 255.0) * 2.0 - 1.0
predicts = self.sess.run(self.predicts, feed_dict={self.images: _images})[0]
return predicts
def _interpret_predicts(self, predicts, img_h, img_w):
"""Interpret the predicts and get the detetction boxes"""
idx1 = self.S*self.S*self.C
idx2 = idx1 + self.S*self.S*self.B
# class prediction
class_probs = np.reshape(predicts[:idx1], [self.S, self.S, self.C])
# confidence
confs = np.reshape(predicts[idx1:idx2], [self.S, self.S, self.B])
# boxes -> (x, y, w, h)
boxes = np.reshape(predicts[idx2:], [self.S, self.S, self.B, 4])
# convert the x, y to the coordinates relative to the top left point of the image
boxes[:, :, :, 0] += self.x_offset
boxes[:, :, :, 1] += self.y_offset
boxes[:, :, :, :2] /= self.S
# the predictions of w, h are the square root
boxes[:, :, :, 2:] = np.square(boxes[:, :, :, 2:])
# multiply the width and height of image
boxes[:, :, :, 0] *= img_w
boxes[:, :, :, 1] *= img_h
boxes[:, :, :, 2] *= img_w
boxes[:, :, :, 3] *= img_h
# class-specific confidence scores [S, S, B, C]
scores = np.expand_dims(confs, -1) * np.expand_dims(class_probs, 2)
scores = np.reshape(scores, [-1, self.C]) # [S*S*B, C]
boxes = np.reshape(boxes, [-1, 4]) # [S*S*B, 4]
# filter the boxes when score < threhold
scores[scores < self.threshold] = 0.0
# non max suppression
self._non_max_suppression(scores, boxes)
# report the boxes
predict_boxes = [] # (class, x, y, w, h, scores)
max_idxs = np.argmax(scores, axis=1)
for i in range(len(scores)):
max_idx = max_idxs[i]
if scores[i, max_idx] > 0.0:
predict_boxes.append((self.classes[max_idx], boxes[i, 0], boxes[i, 1],
boxes[i, 2], boxes[i, 3], scores[i, max_idx]))
return predict_boxes
def _non_max_suppression(self, scores, boxes):
"""Non max suppression"""
# for each class
for c in range(self.C):
sorted_idxs = np.argsort(scores[:, c])
last = len(sorted_idxs) - 1
while last > 0:
if scores[sorted_idxs[last], c] < 1e-6:
break
for i in range(last):
if scores[sorted_idxs[i], c] < 1e-6:
continue
if self._iou(boxes[sorted_idxs[i]], boxes[sorted_idxs[last]]) > self.iou_threshold:
scores[sorted_idxs[i], c] = 0.0
last -= 1
def _iou(self, box1, box2):
"""Compute the iou of two boxes"""
inter_w = np.minimum(box1[0]+0.5*box1[2], box2[0]+0.5*box2[2]) -
np.maximum(box1[0]-0.5*box2[2], box2[0]-0.5*box2[2])
inter_h = np.minimum(box1[1]+0.5*box1[3], box2[1]+0.5*box2[3]) -
np.maximum(box1[1]-0.5*box2[3], box2[1]-0.5*box2[3])
if inter_h < 0 or inter_w < 0:
inter = 0
else:
inter = inter_w * inter_h
union = box1[2]*box1[3] + box2[2]*box2[3] - inter
return inter / union
def show_results(self, image, results, imshow=True, deteted_boxes_file=None,
detected_image_file=None):
"""Show the detection boxes"""
img_cp = image.copy()
if deteted_boxes_file:
f = open(deteted_boxes_file, "w")
# draw boxes
for i in range(len(results)):
x = int(results[i][1])
y = int(results[i][2])
w = int(results[i][3]) // 2
h = int(results[i][4]) // 2
if self.verbose:
print(" class: %s, [x, y, w, h]=[%d, %d, %d, %d], confidence=%f" % (results[i][0],
x, y, w, h, results[i][-1]))
cv2.rectangle(img_cp, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
cv2.rectangle(img_cp, (x - w, y - h - 20), (x + w, y - h), (125, 125, 125), -1)
cv2.putText(img_cp, results[i][0] + ' : %.2f' % results[i][5], (x - w + 5, y - h - 7),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
if deteted_boxes_file:
f.write(results[i][0] + ',' + str(x) + ',' + str(y) + ',' +
str(w) + ',' + str(h)+',' + str(results[i][5]) + '
')
if imshow:
cv2.imshow('YOLO_small detection', img_cp)
cv2.waitKey(1)
if detected_image_file:
cv2.imwrite(detected_image_file, img_cp)
if deteted_boxes_file:
f.close()
if __name__ == "__main__":
yolo_net = Yolo("./YOLO_tensorflow/weights/YOLO_small.ckpt")
yolo_net.detect_from_file("./YOLO_tensorflow/test/person.jpg")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-e386a74c938d> in <module>
1 if __name__ == "__main__":
----> 2 yolo_net = Yolo("./YOLO_tensorflow/weights/YOLO_small.ckpt")
3 yolo_net.detect_from_file("./YOLO_tensorflow/test/person.jpg")
NameError: name 'Yolo' is not defined
参考链接:
论文阅读:You Only Look Once: Unified, Real-Time Object Detection
What makes for effective detection proposals?
专有名词:
Region Proposal:候选区域