一、TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
7、UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
二、udp如何实现可靠性传输?
传输层无法保证数据的可靠传输,只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
实现确认机制、重传机制。
实现流量控制:滑动窗口。
实现拥塞控制:慢开始和拥塞避免,快重传和快恢复。
目前有如下开源程序利用udp实现了可靠的数据传输。分别为RUDP、RTP、UDT。
三、工作内存和主内存。(JMM)
Java 内存模型来屏蔽掉各种硬件和操作系统的内存差异,达到跨平台的内存访问效果。JLS(Java语言规范)定义了一个统一的内存管理模型JMM(Java Memory Model)
Java内存模型规定了所有的变量都存储在主内存中,此处的主内存仅仅是虚拟机内存的一部分,而虚拟机内存也仅仅是计算机物理内存的一部分(为虚拟机进程分配的那一部分)。
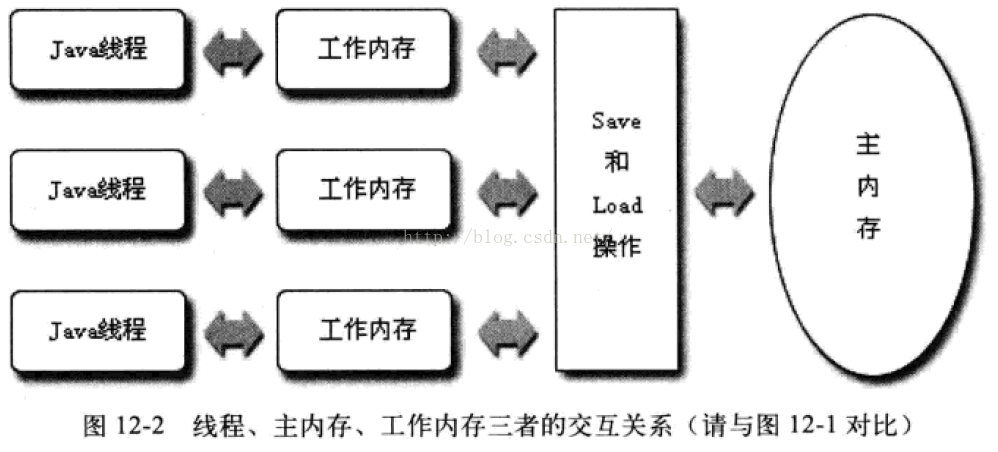
Java内存模型分为主内存,和工作内存。主内存是所有的线程所共享的,工作内存是每个线程自己有一个,不是共享的。
每条线程还有自己的工作内存,线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝。线程对变量的所有操作(读取、赋值),都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者之间的交互关系如下图:
四、GC
五、volatile,volatile和synchronized的区别。
1.保证可见性
2.防止重排序
区别:
1.volatile不进行加锁操作,是比synchronized更轻量级的同步机制,也不会造成线程阻塞
2.volatile不如synchronized安全,不能保证原子性。
3.volatile只能作用于变量,使用范围较小。synchronized可以作用于变量、方法、类、同步代码块等。
六、调试器断点机制的实现
要在被调试进程中的某个目标地址上设定一个断点,调试器需要做下面两件事情:
1. 保存目标地址上的数据
2. 将目标地址上的第一个字节替换为int 3指令
然后,当调试器向操作系统请求开始运行进程时(通过前一篇文章中提到的PTRACE_CONT),进程最终一定会碰到int 3指令。此时进程停止,操作系统将发送一个信号。这时就是调试器再次出马的时候了,接收到一个其子进程(或被跟踪进程)停止的信号,然后调试器要做下面几件事:
1. 在目标地址上用原来的指令替换掉int 3
2. 将被跟踪进程中的指令指针向后递减1。这么做是必须的,因为现在指令指针指向的是已经执行过的int 3之后的下一条指令。
3. 由于进程此时仍然是停止的,用户可以同被调试进程进行某种形式的交互。这里调试器可以让你查看变量的值,检查调用栈等等。
4. 当用户希望进程继续运行时,调试器负责将断点再次加到目标地址上(由于在第一步中断点已经被移除了),除非用户希望取消断点。
七、地址对齐
八、linux下运行程序的原理
作为UNIX操作系统的一种,Linux的操作系统提供了一系列的接口,这些接口被称为系统调用(System Call)。在UNIX的理念中,系统调用"提供的是机制,而不是策略"。C语言的库函数通过调用系统调用来实现,库函数对上层提供了C语言库文件的接口。在应用程序层,通过调用C语言库函数和系统调用来实现功能。一般来说,应用程序大多使用C语言库函数实现其功能,较少使用系统调用。
九、重写和重载的区别
1.重写不能再同一个类中,要在继承或实现关系的类中;重载都可以
2.重写方法名,返回类型,参数类型全部相同;重载方法名相同,参数列表不同,和返回类型无关。
3.重写子类访问修饰符大于父类;异常类型小于父类
十、HTTP实现断点续传
在Http的请求上多定义了断点续传相关的HTTP头 Range和Content-Range字段而已。
可以通过标识文件最后修改时间和对文件进行唯一标识来确定是不是同一个文件。
十一、ArrayList与LinkedList的区别:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.ArrayList查找操作更快,linkedlist的插入删除操作更快。
十二、List如何删除。(为什么用iterator的不用List的删除方法,讲了一下ConcurrentModificationException)
list会报异常,因为 iterator的修改计数器和 list的修改计数器不一致就会返回异常。
十三、多态的底层实现。(看的不是很明白,复习完jvm后应该再理解一遍)
1、先从操作栈中找到对象的实际类型 class;
2、找到 class 中与被调用方法签名相同的方法,如果有访问权限就返回这个方法的直接引用,如果没有访问权限就报错 java.lang.IllegalAccessError ;
3、如果第 2 步找不到相符的方法,就去搜索 class 的父类,按照继承关系自下而上依次执行第 2 步的操作;
4、如果第 3 步找不到相符的方法,就报错 java.lang.AbstractMethodError ;
可以看到,如果子类覆盖了父类的方法,则在多态调用中,动态绑定过程会首先确定实际类型是子类,从而先搜索到子类中的方法。这个过程便是方法覆盖的本质。
十四、Object有哪些公有方法。
clone:对象要实现 Cloneable接口
-浅拷贝:被复制对象的所有值属性都含有与原来对象的相同,而所有的对象引用属性仍然指向原来的对象。
-深拷贝:在浅拷贝的基础上,所有引用其他对象的变量也进行了clone,并指向被复制过的新对象。
equals:在Object中与==是一样的,子类一般需要重写该方法
==:对于基本数据类型,比较的是值;对于引用数据类型,比较的是地址;
String中equals重写过了,比较的是值。
hashCode:计算对象的哈希值,重写过equals后一定要重写hashCode,因为对象默认的hashCode计算是根据对象的地址进行计算的,哈希值的规定是两个对象相同,则哈希值肯定相等,这就与equals冲突了,所以要重新写hashCode。
getClass:class类的提供了你反射操作这个类的一个入口。
wait:调用某个对象的wait()方法,相当于让当前线程交出此对象的monitor,然后进入等待状态;
notify:唤醒一个线程
notify:唤醒所有线程.
toString : 默认打印类名+地址。一般需要重写。
十五、堆溢出、栈溢出
十六、类加载机制,什么时候需要对类进行初始化。
1.new的时候,如果没有初始化,则初始化
2、执行反射操作的时候
3、初始化一个类时,父类没有初始化,则先初始化其父类
4、虚拟机启动时,先初始化主类(包含main方法的类)
十七、如何减少GC
1、对象不用时设置为null
2、少使用 system.gc()
3.少使用静态变量
4.字符串累加时尽量使用stringbuffer
5.分散对象创建时间
6.增大-Xmx的值
7.少使用装箱类
十八、http报文格式
1.请求报文:
请求行:url,http版本,getpost方法
请求头部
空行
请求内容
2.响应报文
状态码
头部
空行
响应内容
十九、http状态码:
100,已收到请求的第一部分,继续发送请求
2**,成功
3**,重定向
4**,请求错误
5**,服务器错误
600,响应报文没有头部只有内容。
二十、get/post的区别
| get | post | |
| 安全性 | 不安全,在url上显示了 | 安全 |
| 大小 | 较小,受浏览器限制 | 大 |
| 书签,缓存 | 可存书签缓存,因为url显示 | 不可以 |
| 作用 | 一般用于获取数据 | 一般用于更新数据 |
二十一、用户输入url后经历了什么。
二十二、进程线程的区别
-
进程是资源分配的最小单位,线程是程序执行的最小单位。
-
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
-
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
-
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。