深浅copy
和很多语言一样,Python中也分为简单赋值、浅拷贝、深拷贝这几种“拷贝”方式。
在学习过程中,一开始对浅拷贝理解很模糊。不过经过一系列的实验后,我发现对这三者的概念有了进一步的了解。
一、赋值
赋值算是这三种操作中最常见的了,我们通过一些例子来分析下赋值操作:
str例
1 >>> a = 'hello' 2 >>> b = 'hello' 3 >>> c = a 4 >>> [id(x) for x in a,b,c] 5 [4404120000, 4404120000, 4404120000]
由以上指令中,我们可以发现a, b, c三者的地址是一样的。所以以上赋值的操作就相当于c = a = b = 'hello'。
赋值是系统先给一个变量或者对象(这里是'hello')分配了内存,然后再将地址赋给a, b, c。所以它们的地址是相同的。
list例
1 >>> a = ['hello'] 2 >>> b = ['hello'] 3 >>> c = a 4 >>> [id(x) for x in a,b,c] 5 [4403975952, 4404095096, 4403975952]
但是这种情况却不一样了,a和b的地址不同。为何?
因为str是不可变的,所以同样是'hello'只有一个地址,但是list是可变的,所以必须分配两个地址。
这时,我们希望探究以上两种情况如果 修改值 会如何?
str例
1 >>> a = 'world' 2 >>> [id(x) for x in a,b,c] 3 [4404120432, 4404120000, 4404120000] 4 >>> print a, b, c 5 world hello hello
这时a的地址和值变了,但是b, c地址和值都未变。因为str的不可变性,a要重新赋值则需重新开辟内存空间,所以a的值改变,a指向的地址改变。b, c由于'hello'的不变性,不会发生改变。
list例
1 >>> a[0] = 'world' 2 >>> [id(x) for x in a,b,c] 3 [4403975952, 4404095096, 4403975952] 4 >>> print a, b, c 5 ['world'] ['hello'] ['world']
这时a, c的值和地址均改变,但二者仍相同,b不改变。由于list的可变性,所以修改list的值不需要另外开辟空间,只需修改原地址的值。所以a, c均改变。
在了解了以上的不同点之后,我们就能很好地分析浅拷贝和深拷贝了。
我们均用list作为例子。
二、浅拷贝
1 >>> a = ['hello', [123, 234]] 2 >>> b = a[:] 3 >>> [id(x) for x in a,b] 4 [4496003656, 4496066752] 5 >>> [id(x) for x in a] 6 [4496091584, 4495947536] 7 >>> [id(x) for x in b] 8 [4496091584, 4495947536]
Line3,4可以看出a, b地址不同,这符合list是可变的,应开辟不同空间。那浅拷贝就是拷贝了一个副本吗?再看Line5 - 8,我们发现a, b中元素的地址是相同的。如果说字符串'hello'地址一致还能理解,但是第二个元素是list地址仍一致。 这就说明了浅拷贝的特点,只是将容器内的元素的地址复制了一份 。
接着我们尝试修改a, b中的值:
1 >>> a[0] = 'world' 2 >>> a[1].append(345) 3 >>> print 'a = ', a, ' ', 'b = ', b 4 a = ['world', [123, 234, 345]] 5 b = ['hello', [123, 234, 345]]
a中第一个元素str改变,但是b中未改变;a中第二个元素改变,b中也改变。这就符合不可变的对象修改会开辟新的空间,可变的对象修改不会开辟新空间。也进一步证明了 浅拷贝仅仅是复制了容器中元素的地址 。
三、深拷贝
1 >>> from copy import deepcopy 2 >>> a = ['hello', [123, 234]] 3 >>> b = deepcopy(a) 4 >>> [id(x) for x in a, b] 5 [4496066824, 4496066680] 6 >>> [id(x) for x in a] 7 [4496091584, 4496067040] 8 >>> [id(x) for x in b] 9 [4496091584, 4496371792]
深拷贝后,可以发现a, b地址以及a, b中元素地址均不同。这才是完全 拷贝了一个副本 。
修改a的值后:
1 >>> a[0] = 'world' 2 >>> a[1].append(345) 3 >>> print 'a = ', a, ' ', 'b = ', b 4 a = ['world', [123, 234, 345]] 5 b = ['hello', [123, 234]]
从Line4,5中可以发现仅仅a修改了,b没有任何修改。 因为b是一个完全的副本,元素地址均与a不同,a修改,b不受影响 。
总结:
1. 赋值是将一个对象的地址赋值给一个变量,让变量指向该地址( 旧瓶装旧酒 )。
2. 浅拷贝是在另一块地址中创建一个新的变量或容器,但是容器内的元素的地址均是源对象的元素的地址的拷贝。也就是说新的容器中指向了旧的元素( 新瓶装旧酒 )。
3. 深拷贝是在另一块地址中创建一个新的变量或容器,同时容器内的元素的地址也是新开辟的,仅仅是值相同而已,是完全的副本。也就是说( 新瓶装新酒 )。
1 import copy 2 a = [1, 2, 3, 4, ['a', 'b']] #原始对象 3 4 b = a #赋值,传对象的引用 5 c = copy.copy(a) #对象拷贝,浅拷贝 6 d = copy.deepcopy(a) #对象拷贝,深拷贝 7 8 a.append(5) #修改对象a 9 a[4].append('c') #修改对象a中的['a', 'b']数组对象 10 11 print 'a = ', a 12 print 'b = ', b 13 print 'c = ', c 14 print 'd = ', d 15 16 输出结果: 17 a = [1, 2, 3, 4, ['a', 'b', 'c'], 5] 18 b = [1, 2, 3, 4, ['a', 'b', 'c'], 5] 19 c = [1, 2, 3, 4, ['a', 'b', 'c']] 20 d = [1, 2, 3, 4, ['a', 'b']]
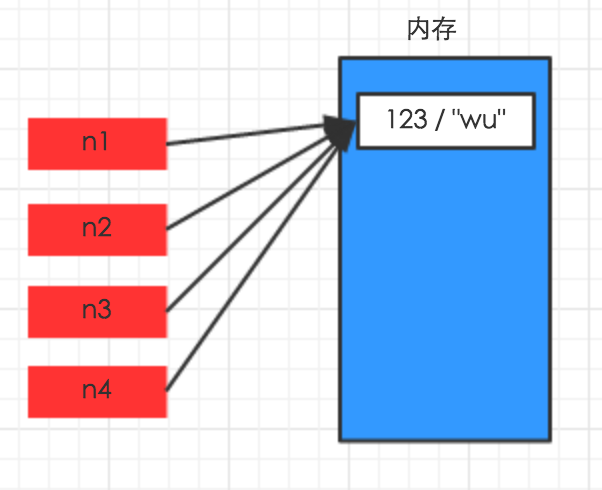
一、数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
1 import copy 2 # ######### 数字、字符串 ######### 3 n1 = 123 4 # n1 = "i am alex age 10" 5 print(id(n1)) 6 # ## 赋值 ## 7 n2 = n1 8 print(id(n2)) 9 # ## 浅拷贝 ## 10 n2 = copy.copy(n1) 11 print(id(n2)) 12 13 # ## 深拷贝 ## 14 n3 = copy.deepcopy(n1) 15 print(id(n3))
二、其他基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
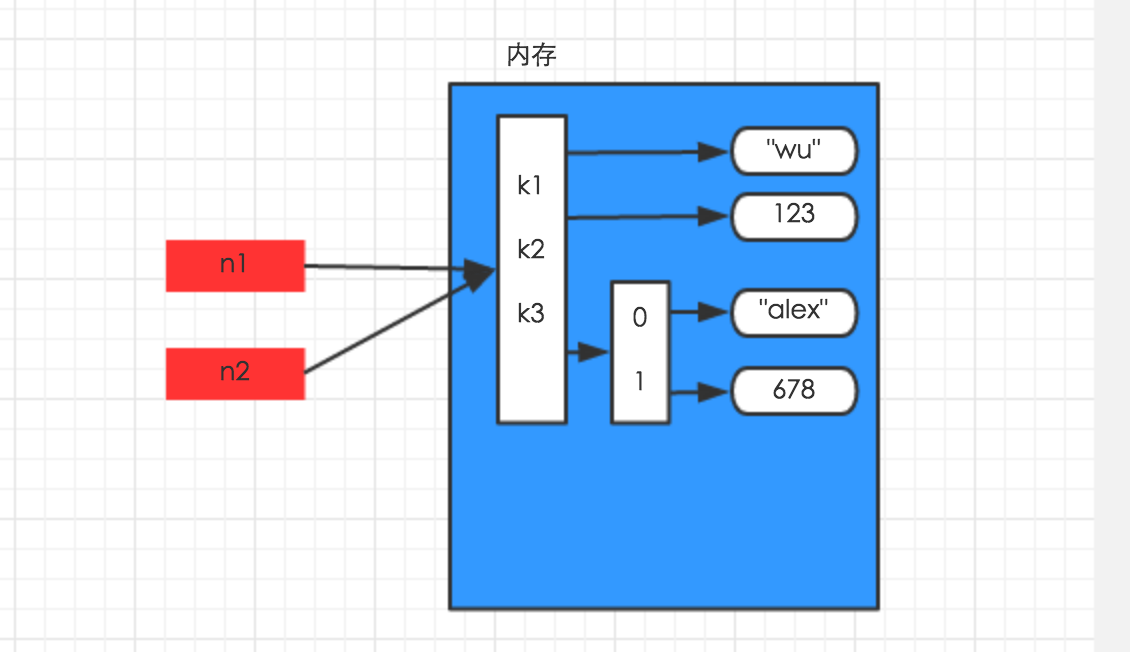
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
1 n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
2
3 n2 = n1
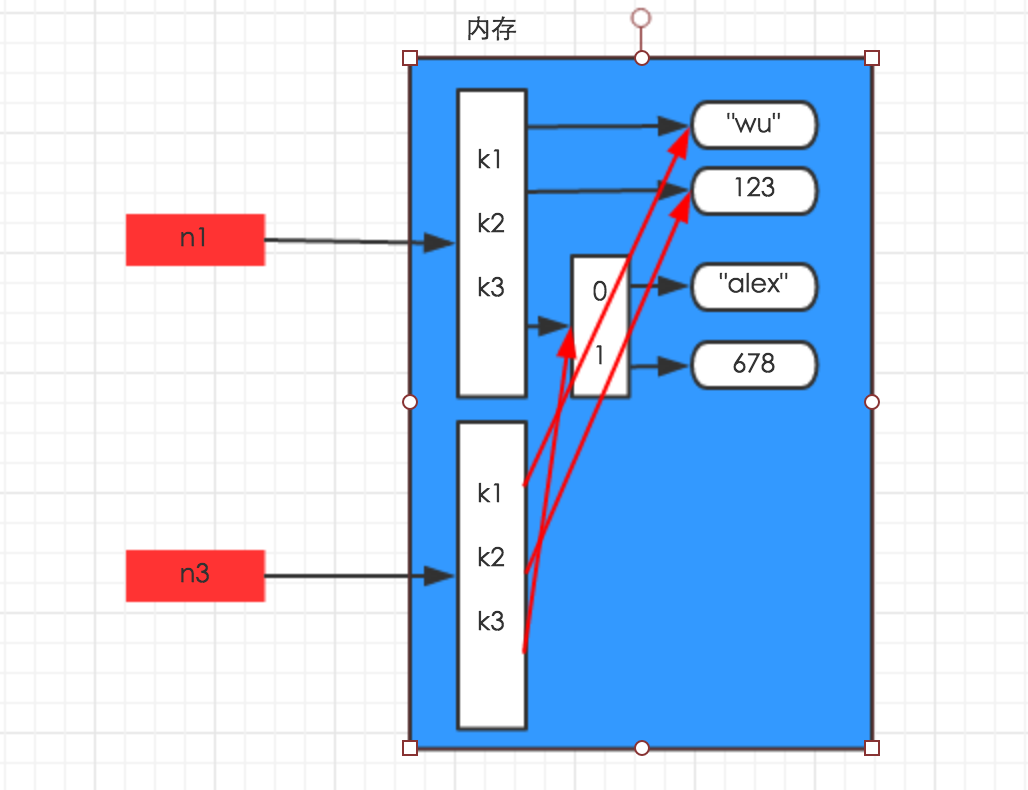
2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
1 import copy
2
3 n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
4
5 n3 = copy.copy(n1)
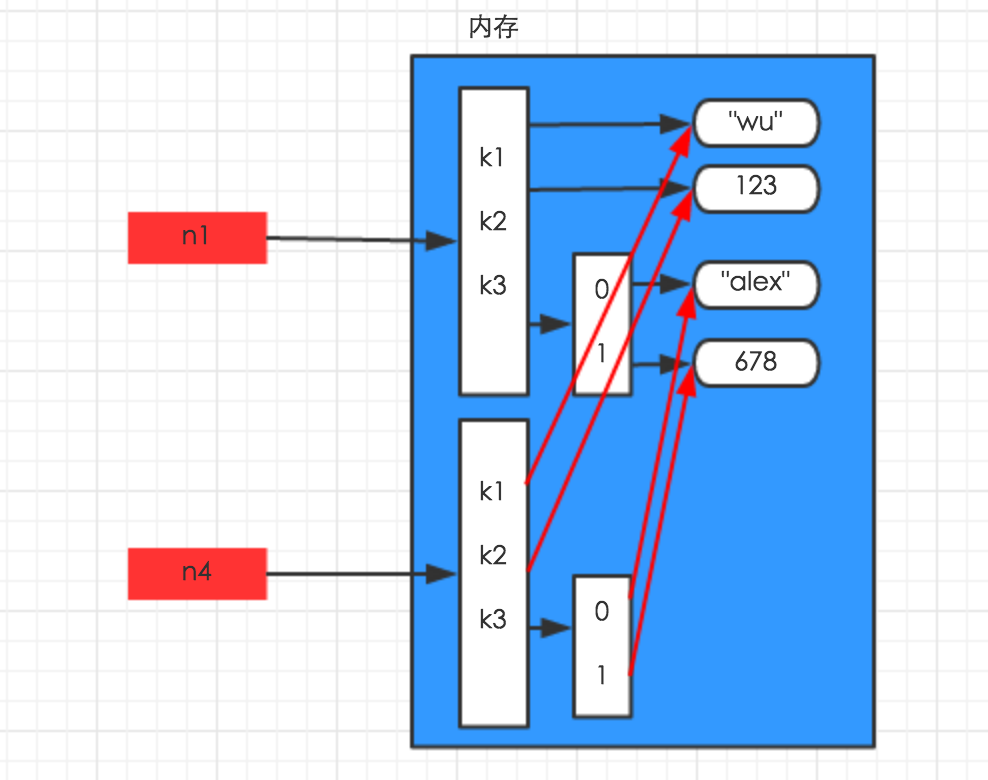
3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
1 import copy
2
3 n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
4
5 n4 = copy.deepcopy(n1)
为什么要拷贝?
当进行修改时,想要保留原来的数据和修改后的数据
数字字符串 和 集合 在修改时的差异?(深浅拷贝不同的终极原因)
1 在修改数据时: 2 数字字符串:在内存中新建一份数据 3 集合:修改内存中的同一份数据
对于集合,如何保留其修改前和修改后的数据?
在内存中拷贝一份
对于集合,如何拷贝其n层元素同时拷贝?
深拷贝
1 浅copy 2 >>> dict = {"a":("apple",),"bo":{"b":"banna","o":"orange"},"g":["grape","grapefruit"]} 3 >>> dict = {"a":("apple",),"bo":{"b":"banna","o":"orange"},"g":["grape","grapefruit"]} 4 >>> dict2 = dict.copy() 5 6 7 >>> dict["g"][0] = "shuaige" #第一次我修改的是第二层的数据 8 >>> print dict 9 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['shuaige', 'grapefruit']} 10 >>> print dict2 11 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['shuaige', 'grapefruit']} 12 >>> id(dict["g"][0]),id(dict2["g"][0]) 13 (140422980581296, 140422980581296) #从这里可以看出第二层他们是用的内存地址 14 >>> 15 16 17 >>> dict["a"] = "dashuaige" #注意第二次这里修改的是第一层 18 >>> print dict 19 {'a': 'dashuaige', 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['shuaige', 'grapefruit']} 20 >>> print dict2 21 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['shuaige', 'grapefruit']} 22 >>> 23 >>> id(dict["a"]),id(dict2["a"]) 24 (140422980580816, 140422980552272) #从这里看到第一层他们修改后就不会是相同的内存地址了! 25 >>> 26 27 28 #这里看下,第一次我修改了dict的第二层的数据,dict2也跟着改变了,但是我第二次我修改了dict第一层的数据dict2没有修改。 29 说明:浅copy只是第一层是独立的,其他层面是公用的!作用节省内存 30 31 深copy 32 33 >>> import copy #深copy需要导入模块 34 >>> dict = {"a":("apple",),"bo":{"b":"banna","o":"orange"},"g":["grape","grapefruit"]} 35 >>> dict2 = copy.deepcopy(dict) 36 >>> print dict 37 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['grape', 'grapefruit']} 38 >>> print dict2 39 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['grape', 'grapefruit']} 40 >>> dict["g"][0] = "shuaige" #修改第二层数据 41 >>> print dict 42 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['shuaige', 'grapefruit']} 43 >>> print dict2 44 {'a': ('apple',), 'bo': {'b': 'banna', 'o': 'orange'}, 'g': ['grape', 'grapefruit']} 45 >>> id(dict["g"][0]),id(dict2["g"][0]) 46 (140422980580816, 140422980580288) #从这里看到第二个数据现在也不是公用了 47 48 # 通过这里可以看出他们现在是一个完全独立的,当你修改dict时dict2是不会改变的因为是两个独立的字典!