本文链接:http://www.cnblogs.com/zhenghongxin/p/8885879.html
我们知道redis是有主从复制的,例如下图:

但如果master主进程挂掉之后,没有slave站出来当master,那么整个写redis业务就崩溃了。虽然其他业务可以从从redis上继续读取数据,当主写redis已经崩溃了,势必造成影响。而redis为我们提供了Sentinel来做redis的高可用工具,因此个人觉得实际上redis并不需要像Nginx那样,与keepalived组合成高可用,或者进行集群化操作,用多sentinel与主从即可。当然集群也有着它的好处:构建多节点,节点上的数据都不一样把数据都分散存放到各个节点上进行存储,某个节点的退出依旧有其他节点补充。引用网上的图:

(集群节点)
主从是master或者slave都会备份一份数据,集群是节点共享数据,在中间件模式中,可以使用集群与主从相结合的模式开发。
部署
构建简单的一个sentinel,一个 master redis ,两个slove redis 。
在linux上自建的conf配置目录(/code/redis/conf)下,可以看到四个conf文件:
[root@VM_71_225_centos conf]# ll
-rw-r----- 1 root root 138 Apr 19 19:17 redis-6379.conf
-rw-r--r-- 1 root root 108 Apr 19 19:15 redis-6380.conf
-rw-r--r-- 1 root root 86 Apr 19 19:15 redis-6381.conf
-rw-r--r-- 1 root root 447 Apr 19 19:18 sentinel-26379.conf
分别配置如下:
(这里只是简单的配置版本,实际生产环境中,需要注意主从库的备份机制,备份方式,只读权限,连接密码等细节)
redis-6379.conf ==>
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
dir "/tmp/log"
redis-6380.conf ==>
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
dir "/tmp/log"
slaveof 127.0.0.1 6379
redis-6381.conf ==>
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
dir "/tmp/log"
slaveof 127.0.0.1 6379
sentinel-26379.conf ==>
port 26379
dir "/tmp/log"
logfile "26379.log"
sentinel monitor mymaster 127.0.0.1 6379 1 # 当前Sentinel节点监控 127.0.0.1:6379 这个主节点 , 1 代表判断主节点失败至少需要2个Sentinel节点节点同意
sentinel down-after-milliseconds mymaster 10000 # 每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过10000毫秒且没有回复,则判定不可达
sentinel failover-timeout mymaster 900000 # 故障转移超时时间
请测试的时候,把注释去掉
启动
启动主从redis
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
分别查看info replication 信息:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=15,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=15,lag=0
master_repl_offset:15
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:14
[root@VM_71_225_centos conf]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:11
master_sync_in_progress:0
slave_repl_offset:99
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
此时,6379为主,其他两个端口为从
启动sentinel
redis-sentinel sentinel-26379.conf &
查看info信息:
redis-cli -h 127.0.0.1 -p 26379 INFO Sentinel
[root@VM_71_225_centos conf]# redis-cli -h 127.0.0.1 -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=1
//这里可以看到 6379为主,有两个slaves 和一个sentinels ,这也意味着,sentinels是可以多个集群的
如果我们想要多个sentinel集群,方法一致,只是端口不一致而已,其他配置一致。
这样我们将会构成如下的模式:
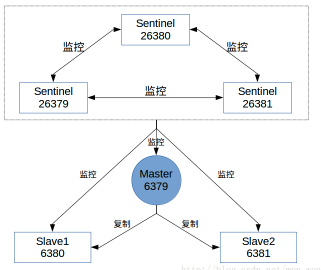
再看sentinel-26379.conf 的配置,已经被sentinel改写:
port 26379
dir "/tmp/log"
logfile "26379.log"
sentinel myid 45ad97bb868a74e2f7ba5cdba7ba723af1095027
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 10000
# Generated by CONFIG REWRITE
sentinel failover-timeout mymaster 900000
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 127.0.0.1 6381
sentinel known-slave mymaster 127.0.0.1 6380
sentinel current-epoch 0
模拟master redis 挂掉后
sentinel 自动把其中一个slave拉起作为master,再看sentinel的信息:
[root@VM_71_225_centos conf]# redis-cli -h 127.0.0.1 -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=1
已经被sentinel改写
其他命令:
- sentinel monitor mymaster 127.0.0.1 6379 2
当前Sentinel节点监控 127.0.0.1:6379 这个主节点
2代表判断主节点失败至少需要2个Sentinel节点节点同意
mymaster是主节点的别名
- sentinel down-after-milliseconds mymaster 30000
每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒且没有回复,则判定不可达
sentinel parallel-syncs mymaster 1
当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1。
- sentinel failover-timeout mymaster 180000
故障转移超时时间为180000
- sentinel auth-pass
如果Sentinel监控的主节点配置了密码,可以通过sentinel auth-pass配置通过添加主节点的密码,防止Sentinel节点无法对主节点进行监控。
例如:sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
- sentinel notification-script
在故障转移期间,当一些警告级别的Sentinel事件发生(指重要事件,如主观下线,客观下线等)时,会触发对应路径的脚本,想脚本发送相应的事件参数。
例如:sentinel notification-script mymaster /var/redis/notify.sh
- sentinel client-reconfig-script
在故障转移结束后,触发应对路径的脚本,并向脚本发送故障转移结果的参数。
例如:sentinel client-reconfig-script mymaster /var/redis/reconfig.sh。