一、回溯引用
1.将页面中合法的标题找出来,使用回溯引用匹配 (需要使用 -E 或 -P 来扩展grep语法支持)

2.查找连续出现的单词

二、前后查找 (grep 只能使用 -P 选项)
1. 向前查找
(1)查找协议名称
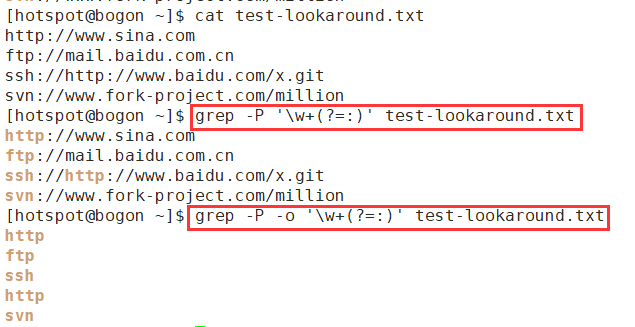
(2)只要行首协议名称

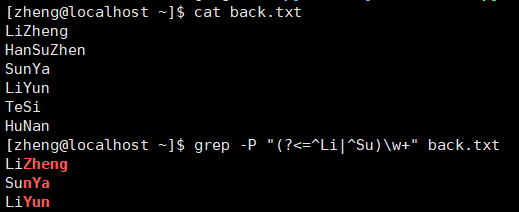
2.向后查找
查找以Li开头的名字
三、嵌入条件( grep 只有-P选项可用来进行嵌入条件查找)

(2) 查找首尾都是数字的行(不使用嵌入条件会更简单,这里仅是演示)
[zheng@localhost ~]$ cat embed.txt 1bei3 1shangdf 1guang9 shen [zheng@localhost ~]$ grep -P '(d+).*(?(1)d+)$' embed.txt 1bei3 1guang9
四、获得本机IP
ip addr show | grep -P '(?<=inets)([0-9]{1,3}.){3}([0-9]{1,3})(?=.*globals+e)' -o
which ip &>/dev/null && ip addr show | grep 'brd.*global'| grep -v 'vir' | cut -d '/' -f 1 | sed 's/[^0-9.]//g'
五、获得操作系统名字(适用于Ubuntu CentOS)
cat /etc/os-release | grep -P "(?<=^NAME=").*(?=")" -o
六、grep使用
(1)选项
-c 统计匹配行数 -o 只输出匹配结果 -n 输出行号 -v 反转输出 -E 扩展正则表达式 -P 使用Perl正则表达式
(2)单词个数
6.2.1输出文本中包含的单词set的个数
grep -o ’set‘ fileName | wc -l
6.2.2输出多少行包含 set
grep -c 'set' fileName
使用扩展正则 grep -E 'regex' fileName