我用的是Ubuntu16.04,显卡是2070s,python3.6,cuda版本是9.0(系统环境安装),pytorch版本是1.0.0。
一、运行的一些注意事项:
1.数据集linemod_preprocessed(一共有13个类:1、2、4、5、6、8、9、10、11、12、13、14、15)
| class | 1 | 2 | 4 | 5 | 6 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | total |
| train | 186 | 181 | 181 | 180 | 177 | 179 | 189 | 188 | 184 | 186 | 173 | 185 | 184 | 2373 |
| test | 1050 | 1031 | 1020 | 1016 | 1002 | 1009 | 1065 | 1065 | 1036 | 1051 | 979 | 1042 | 1041 | 13407 |
文件夹linemod_preprocessed下的子文件夹为:data、models、segnet_results。
其中
(1)data文件夹:虽然序号是到15,但是实际上只有13个文件夹,3和7文件夹是没有的。分别对应13个类别。

随便进入一个文件夹,如1:

1. depth(目录): 深度图;
2. mask(目录):目标物体的掩码,为标准的分割结果;
3. rgb(目录):保存为RGB图像;
4. gt.yml(文件):保存了拍摄每张图片时,其对应的旋转矩阵和偏移矩阵,以及目标物体的标准box, 和该图像中目标物体所属于的类别;
5. info.yml(文件):拍摄每张图像,对应的摄像头的内参,以及深度缩放的比例;
6.test.txt(文件):划分好的测试数据集;
7.train.txt(文件):划分好的训练数据集。
(2)models文件夹
Linemod_preprocessedmodels中每个ply文件,其中的点云信息,都是以linemodLinemod_preprocesseddataxx gb�000.png作为参考面的。有了这个参考面的点云数据(包含了整个目标的完整点云),我们就能根据其他的拍摄照片时的摄像头参数(旋转和偏移矩阵),计算出其他的视觉对应的点云数据了。
models_info.yml文件,其保存的是每个目标点云模型的半径,x,y,z轴的起始值和大小范围。
(3)segnet_results文件夹
在训练模型的时候,是拿最标准的数据去训练我们的模型,所以训练和验证时,都是使用最标准的mask(Linemod_preprocessed/data/mask),作为分割的标签。
但是在测试的时候,要结合应用场景,我们希望越接近实际场景越好,在实际场景中,DenseFusion网络是对分割出来的目标进行姿态预测,所以实际应用中,还需要一个分割网络。所以segnet_results中,保存的就是语义分割网络分割出来的图片,为了和实际场景更加接近,这也是其和标准的mask的一点区别。

2.软链接的问题
将代码文件夹的数据集文件夹链接到解压缩的数据集文件夹:ln -s 解压缩后的数据集文件夹的路径 代码里的数据集文件夹路径
ln -s /home/zza/datasets/LineMOD/Linemod_preprocessed /home/zza/code/DenseFusion-master/datasets/linemod/Linemod_preprocessed
解压缩后数据集的路径(这里的Linemod_preprocessed文件夹是实际存在的) 代码的数据集文件夹路径(这里的Linemod_preprocessed文件夹不用创建,运行这句命令后会自动生成,会是一个带有向上箭头的文件夹,如下图:)

3.将训练好的模型用于测试:
python3 ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed --model trained_models/linemod/pose_model_current.pth --refine_model trained_models/linemod/pose_refine_model_current.pth
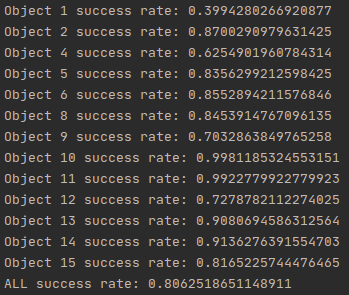
测试结果(成功率)为:
二、运行出现的问题:
1.下载的版本的问题
DenseFusion-master:是0.4版本。https://github.com/j96w/DenseFusion
DenseFusion-Pytorch-1.0:是1.0版本。https://github.com/j96w/DenseFusion/tree/Pytorch-1.0
2.在运行./experiments/scripts/eval_linemod.sh的问题
'AttributeError: module 'lib.knn.knn_pytorch' has no attribute 'knn'' .
解决办法:
在/home/zza/code/DenseFusion-Pytorch-1.0/lib/knn运行:python setup.py build和python setup.py install,然后会在/home/zza/code/DenseFusion-Pytorch-1.0/lib/knn生成dist文件夹,将里面的knn_pytorch-0.1-py3.6-linux-x86_64.egg文件解压,将knn_pytorch-0.1-py3.6-linux-x86_64.egg_FILES/knn_pytorch里面的knn_pytorch.cpython-36m-x86_64-linux-gnu.so和knn_pytorch.py文件复制到/home/zza/code/DenseFusion-Pytorch-1.0/lib/knn目录。
还会有一个问题:
将一个语句的前面的“_,”去掉即可。

3.在运行./experiments/scripts/train_linemod.sh的问题
每记错的话应该是这个ImportError: libcudart.so.9.0: cannot open shared object file: No such file or directory
我一开始是cuda9.0,然后换成了cuda10.0和在pytorch官网安装了对应的pytorch; 然后又换回cuda9.0,再在pytorch官网安装了对应的pytorch就可以了,也不知道为啥。
4.在训练时如果出现中断,可以加载训练了一段时间的模型(--resume_posenet pose_model_current.pth),继续训练,而不用重新训练。
python3 ./tools/train.py --dataset linemod --dataset_root ./datasets/linemod/Linemod_preprocessed --resume_posenet pose_model_current.pth
5.在训练过程中会中断,是因为误差满足要求,要开始训练refinenet,代码出现错误。
RuntimeError: the derivative for 'index' is not implemented
解决办法是:
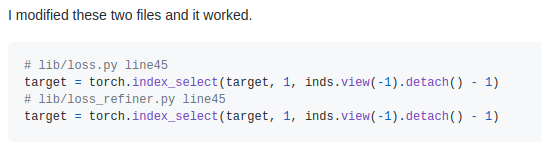
添加了.detach()
三、开始复现
训练过程:训练过程包含两个部分:(i)DenseFusion模型的训练。(ii)训练迭代优化模型。在此代码中,将首先训练DenseFusion模型。当平均测试距离结果(非对称对象的ADD,对称对象的ADD-S)小于一定的余量(refine_margin)时,迭代优化模型的训练将自动开始,然后DenseFusion模型将被固定。您可以更改此margin以在不进行细化的情况下获得更好的DenseFusion结果,但它比迭代细化后的最终结果差。
checkpoints和resuming:每训练1000个批次后,将保存一个pose_model_current.pth/pose_refine_model_current.pth检查点。您可以使用它来恢复训练。在每个测试时期之后,如果平均距离结果是迄今为止最好的,则将保存一个pose_model_(epoch)_(best_score).pth/ pose_model_refiner_(epoch)_(best_score).pth检查点。您可以将其用于评估。
注意:迭代精化模型的训练需要一些时间。请耐心等待,经过约30次练习后,情况才会有所改善。
训练之前我先用linemod_preprocessed数据集给定的模型进行了验证,结果如图所示:
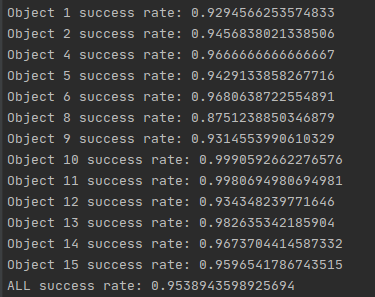
可见,成功率有0.95。
训练的时候会加载2373张训练集,但会重复训练20次,所以就会有2373X20=47460帧,但是由于batch_size是8,所以47460/8=5932.5,最后不足8张,所以只会有5932个batch加载,即:5932X8=47456帧。
加载1336张测试集。
1.第一次训练只需要加载训练要用的数据集即可:epoch:29(1~30),在第30个epoch停止。时间:9h53m30s。Avg dis:0.011346239087811091。Avg dis:平均距离(average distance)ADD。
python3 ./tools/train.py --dataset linemod --dataset_root ./datasets/linemod/Linemod_preprocessed
其实不止29个epoch,因为之前训练出现了中断之类的很多情况,这里我是直接用了之前训练的姿态估计模型来继续训练,由于refine_margin没有达到预定的值(0.013),所以没有进行姿态细化模型的训练,自然也就没有它的模型了,所以也加载不了。
python ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed --model pose_model_current.pth
训练会产生一些log文件和训练出来的模型(包括姿态估计(pose_model_current.pth)和姿态细化(pose_refine_model_current.pth)的模型),
其中log文件保存在/home/zza/code/DenseFusion-Pytorch-1.0/experiments/logs/linemod,
模型保存在/home/zza/code/DenseFusion-Pytorch-1.0/trained_models/linemod。
训练完成之后可以使用验证脚本进行验证:(--model是自己训练好的姿态估计模型,--refine_model是自己训练好的姿态细化模型)
python ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed --model trained_models/linemod/pose_model_current.pth --refine_model trained_models/linemod/pose_refine_model_current.pth
验证结果如图所示:
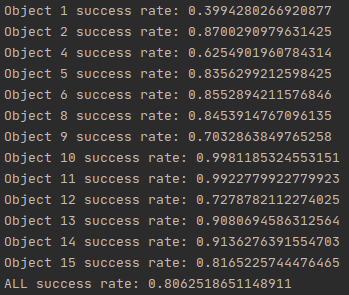
成功率只有0.8,可知结果并不是很好。
2.第二次训练:epoch:29(30~59),在第59个epoch停止。时间:12h17m09s。Avg dis:0.011077157911425595。
由于第一次的成功率并不高,我以为将refine_margin(当Avg dis小于refine_margin时就会开始训练姿态细化模型)这个参数设置低一点,结果会有所提升,我就将默认的值(0.013)改成了0.0013(后面又该成0.065),由于第一次训练Avg dis就低于refine_margin,第一次训练就有姿态细化模型了,但是我并没有对它进行加载,而只加载了姿态估计模型,但是设置的refine_margin过于低了,导致训练完所有周期也没有开始重新(没有加载先前训练好的姿态细化模型,会重新进行训练。但是由于Avg dis并没有低于refine_margin而没有进行训练)训练姿态细化模型,因为很难达到那么低的值。我觉得这也是导致这次结果比第一次结果还要差的原因:没有进行姿态细化模型的训练,而是使用了第一次训练的姿态细化模型来进行验证。
验证结果如图所示:

成功率比第一次还要低了。
3. 第三次训练:epoch:30(1~31),在第31个epoch停止。时间:9h15m23s。Avg dis:0.008868885608165159。
这一次训练我将refine_margin改回了默认值(0.013),并且加载第一次训练的姿态细化模型,所以它就会停止训练姿态估计模型,并开始训练姿态细化模型。可见下图:输出的第一个模型名字就是姿态细化模型的名字(pose_refine_model_1_0.010882976234449258.pth),而不是姿态估计模型的名字,代码就是这样,如果没有加载姿态细化模型且Avg dis并没有低于refine_margin,那么输出的模型名字就是姿态估计模型的名字。
python3 ./tools/train.py --dataset linemod --dataset_root ./datasets/linemod/Linemod_preprocessed --resume_posenet pose_model_current.pth --resume_refinenet pose_refine_model_current.pth
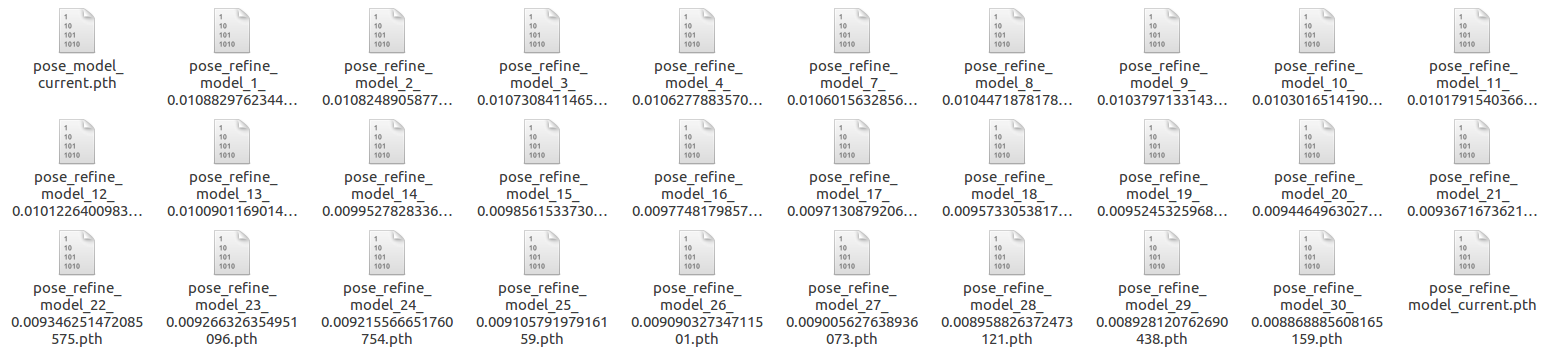
验证结果如图所示:
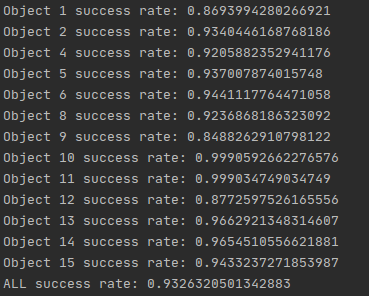
这次的结果有所改善,且开始接近linemod_preprocessed数据集给定的模型验证的成功率。
所以1、2、3一共训练了有88(29+29+30)次以上。
4. 第四次训练:epoch:30(31~61),在第61个epoch停止。时间:9h14m22s。Avg dis:0.007780234729972233。
这一次我修改了refine_margin:0.008,并且同时加载姿态估计模型和姿态细化模型,而且由于加载了姿态细化模型,那么它就只会训练姿态细化模型(看代码是这样的,要么加载了姿态细化模型,要么Avg dis低于refine_margin,它就会开始训练姿态细化模型),而不会训练姿态估计模型。可见下图:输出的第一个模型名字就是姿态细化模型的名字(pose_refine_model_31_0.008742919701296547.pth),而不是姿态估计模型的名字,代码就是这样,如果没有加载姿态细化模型且Avg dis并没有低于refine_margin,那么输出的模型名字就是姿态估计模型的名字。
验证结果如图所示:
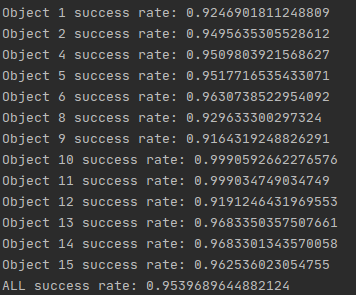
可见这次的结果已经优于linemod_preprocessed数据集给定的模型验证的成功率了。
所以1、2、3、4一共训练了有118(29+29+30+30)次以上。
5. 第五次训练:epoch:30(61~91),在第91个epoch停止。时间:9h26m27s。Avg dis:0.007370748565341262。
这一次我保持上次的refine_margin:0.008,还是同时加载姿态估计模型和姿态细化模型,而且由于加载了姿态细化模型,那么它就只会训练姿态细化模型(看代码是这样的,要么加载了姿态细化模型,要么Avg dis低于refine_margin,它就会开始训练姿态细化模型),而不会训练姿态估计模型。可见下图:输出的第一个模型名字就是姿态细化模型的名字(pose_refine_model_61_0.007777808692393766.pth),而不是姿态估计模型的名字,代码就是这样,如果没有加载姿态细化模型且Avg dis并没有低于refine_margin,那么输出的模型名字就是姿态估计模型的名字。

验证结果如图所示:
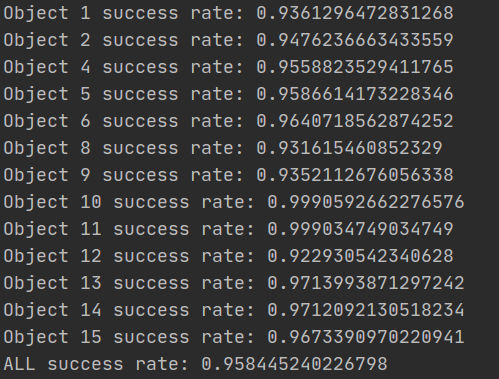
可见这次的结果也是优于linemod_preprocessed数据集给定的模型验证的成功率。
所以1、2、3、4、5一共训练了有148(29+29+30+30+30)次以上。
时间一共用了:50h6m51s