VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
摘要
研究主要贡献是通过非常小的3x3卷积核的神经网络架构全面评估了增加深度对网络的影响,结果表明16-19层的网络可以使现有设置的网络性能得到显著提高
引言
为得到更好的准确率,在本文中,研究着眼于卷积神经网络中的深度问题。为此,固定了架构中的其他参数,并通过添加卷积层稳定地增加网络深度,在每层都使用非常小的3x3卷积核
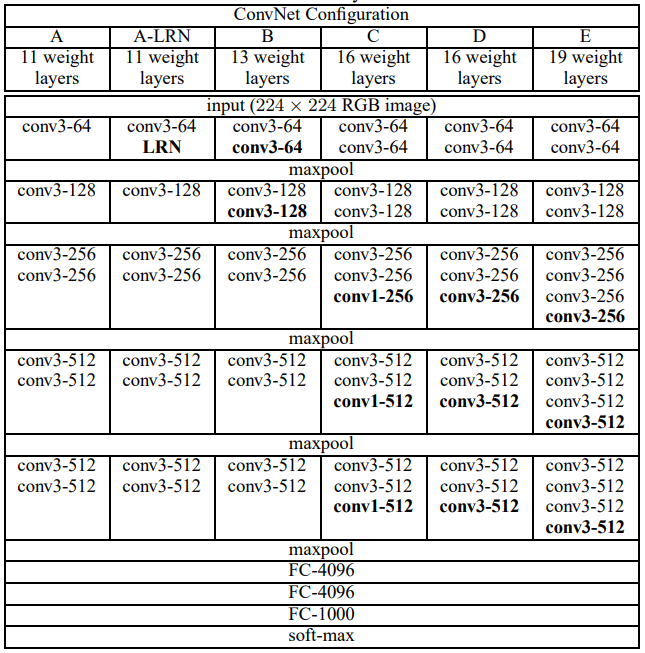
ConvNet配置
为了公平衡量增加卷积深度对网络的影响,所有卷积层的设置均使用与Ciresan(2011)和Krizhevsky(2012)相同的设计原则
架构
在整个训练中,卷积神经网络的输入为固定的224x224的RGB图片。唯一的预处理是对每个像素减去ImageNet训练集中RGB的平均值。图片通过一系列3x3卷积核(是用来获取上下左右及中心的最小尺寸)的卷积层。在一种配置中,也使用1x1的卷积核,这可以看做是输入通道的线性变换(后面接一个非线性变换)。卷积滑动步长固定为1;卷积层的空间填充模式为保留原空间分辨率,例如3x3的卷积层,padding为1。空间池化包含5个最大池化层,接在部分卷积层后面(不是所有卷积层)。最大池化层使用2x2的窗口,滑动步长为2。在一系列卷积层(不同架构有不同深度)后为3个全连接层(Fully-Connected):前两个每个含有4096个通道,第三个用来给ILSVRC进行分类,因此有1000个通道(1000个类)。最后一层使用softmax。全连接层的设置与所有网络一致。所有隐藏层都使用ReLU非线性激活函数
架构设置
参数数量

讨论
该研究中在整个网络使用3x3的卷积核,与每个像素值进行卷积(步长为1)。很明显,两个3x3卷积层(中间没有池化层)相当于5x5的接受域;三个这样的层相当于7x7的接受域
使用更小的卷积核的好处
- 包含三个非线性修正层而非单一层,这使决策函数更具有区分性
- 减少了参数数量
1x1卷积层的加入是一种为决策增加非线性因素的方式,不影响卷积层接受域。尽管1x1的卷积实质上是相同空间维度的线性投影(输入和输出通道相同),但是修正函数引入了非线性因素
训练
通过用包含动量的小批量梯度下降(基于反向传播)做多项式逻辑回归的优化器来对模型进行训练。批次大小为256,动量为0.9,通过权值衰减(L2惩罚因子设置为5*10-4)和对前两个全连接层进行dropout(比率0.5)实现正则化。学习率初始化为0.01,当验证集准确率不提升时以10倍速率衰减(除以10)。总的来说,学习率会衰减3次,然后训练次数为370K(epoch=74)
此处,与一些之前的网络相比,虽然网络参数更多,深度更深,但是只需要更少的epoch次数就达到了收敛,原因有
- 深度及更小的滤波器数量隐式增强了正则化
- 某些层执行了预初始化
网络权重的初始化很重要,由于深度网络梯度下降的不稳定性,不好的初始化会阻碍学习。为了规避这个问题,从训练网络A开始,它足够浅,能用随机初始化。然后,当训练更深网络结构时,用网络A的权重初始化前四个卷积层和后三个全连接层(中间层随机)
为了得到固定的224x224的RGB输入图片,随机地从经过尺寸缩放的训练集图片中进行裁剪(每张图的每次SGD迭代时裁剪一次)。为了进一步对训练集数据进行增强,被裁剪图片将进行随机水平翻转及RGB颜色转换
考虑使用两种方式来设置训练尺寸S
- 固定S,针对单尺寸图片的训练。在实验中,评估了两种固定尺寸的训练模型:S=256(在之前研究中广泛使用)和S=384。给一个卷积神经网络,首先用S=256训练。为了加速S=384的训练,使用在S=256上的预训练权重来初始化权重,并且使用较小的初始学习率0.001
- 使用多尺寸图像训练,即每个训练图片的尺寸是[Smin,Smax]之间的随机数(这里使用Smin=256, Smax=512)。由于图像中的对象可能大小不一,所以训练中采用这种方式是有利的
结论
本研究评估了深度卷积网络(到19层)在大规模图片分类中的应用。结果表明,深度有益于提高分类的正确率
总结
- 使用堆叠3*3卷积核来取代5*5和7*7的卷积核
堆叠小的卷积核可以获得和大卷积核相同大小的视野,但是只使用了更少的参数,使得计算量变得更小,同时拥有更多的非线性变换,增加了CNN对特征的学习能力
- 引入1*1的卷积核
在不影响输入输出维度的情况下,引入非线性变换,增强了网络的表达能力
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度
- 采用了Multi-Scale的方法来训练和预测
可以增加训练的数据量,防止模型过拟合,提升预测准确率