一:explain演示
1. 构建数据
为了方便演示,我需要create ten dayyy to inventory,而且还是要在no index 的情况下,比如下面这样:
1 db.inventory.insertMany([
2 { "_id" : 1, "item" : "f1", type: "food", quantity: 500 },
3 { "_id" : 2, "item" : "f2", type: "food", quantity: 100 },
4 { "_id" : 3, "item" : "p1", type: "paper", quantity: 200 },
5 { "_id" : 4, "item" : "p2", type: "paper", quantity: 150 },
6 { "_id" : 5, "item" : "f3", type: "food", quantity: 300 },
7 { "_id" : 6, "item" : "t1", type: "toys", quantity: 500 },
8 { "_id" : 7, "item" : "a1", type: "apparel", quantity: 250 },
9 { "_id" : 8, "item" : "a2", type: "apparel", quantity: 400 },
10 { "_id" : 9, "item" : "t2", type: "toys", quantity: 50 },
11 { "_id" : 10, "item" : "f4", type: "food", quantity: 75 }]);
|
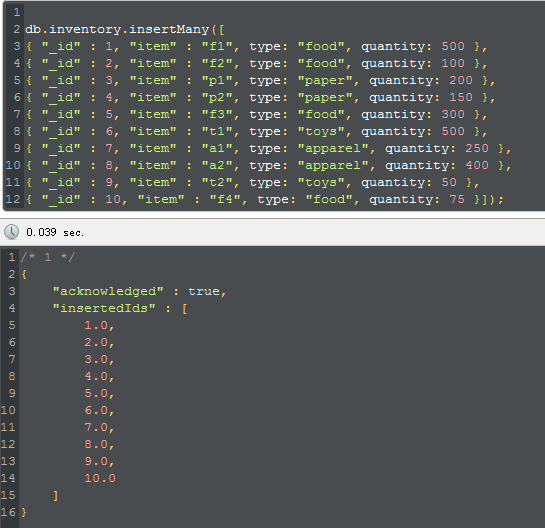
2. 无索引查询
b.inventory.find(
{ quantity: { $gte: 100, $lte: 200 } }
).explain("executionStats")
|
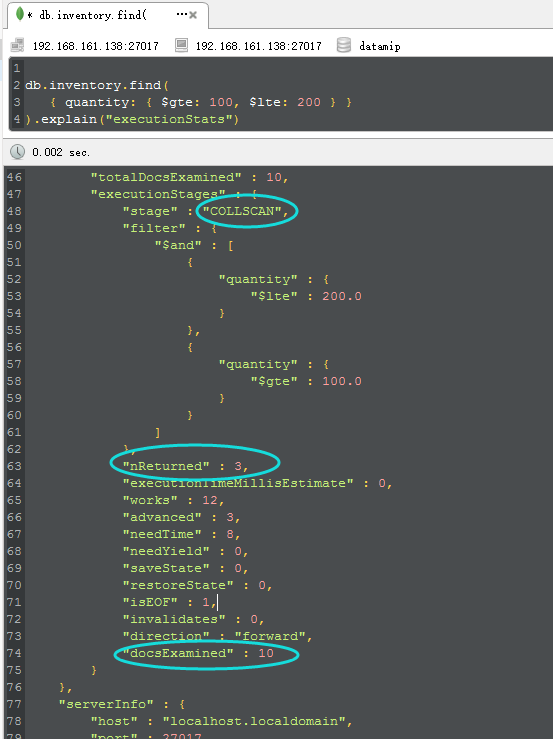
从上图中,我们看到了三个圈圈,这些都是我们在find中非常重要的信息,具体信息解释如下:
<1>COLLSCAN
这个是什么意思呢? 如果你仔细一看,应该知道就是CollectionScan,就是所谓的“集合扫描”,对不对,看到集合扫描是不是就可以直接map到 数据库中的yyyble scan/heap scan呢??? 是的,这个就是所谓的性能最烂最无奈的由来。
<2> nReturned
这个很简单,就是所谓的numReturned,就是说最后返回的num个数,从图中可以看到,就是最终返回了三条。。。
<3> docsExamined
那这个是什么意思呢??就是documentsExamined,检查了10个documents。。。而从返回上面的nReturned。。。
ok,那从上面三个信息中,我们可以得出,原来我examine 10 条数据,最终才返回3条,说明做了7条数据scan的无用功,那么这个时候问题就来了,如何减少examine的documents。。。
3. 使用single field 加速查找
知道前因后果之后,我们就可以进行针对性的建立索引,比如在quality字段之上,如下:
db.inventory.createIndex({ quantity: 1})
db.inventory.find(
{ quantity: { $gte: 100, $lte: 200 } }
).explain("executionStats")
|
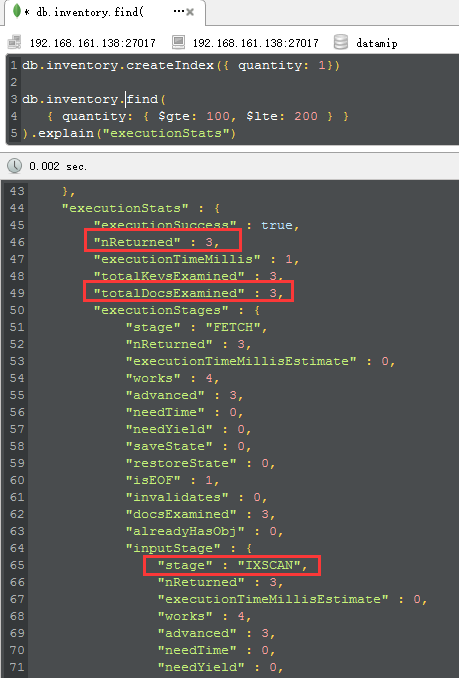
好了,这时候就有意思了,当我们执行完createindex之后,再次explain,4个重要的parameters就漂下来了:
<1> IXSCAN
这个时候再也不是所谓的COLLSCAN了,而是IndexScan,这就说明我们已经命中索引了。
<2> nReturned,totalDocsExamined,totalKeysExamined
从图中可以看到三个参数都是3,这就说明我们的mongodb查看了3个key,3个document,返回3个文档,这个就是所谓的高性能所在,对吧。
二:hint演示
说到hint,我想大家也是知道的,很好玩的一个东西,就是用来force mongodb to excute special index,对吧,为了方便演示,我们做两组复合索 引,比如这次我们在quality和type上构建一下:
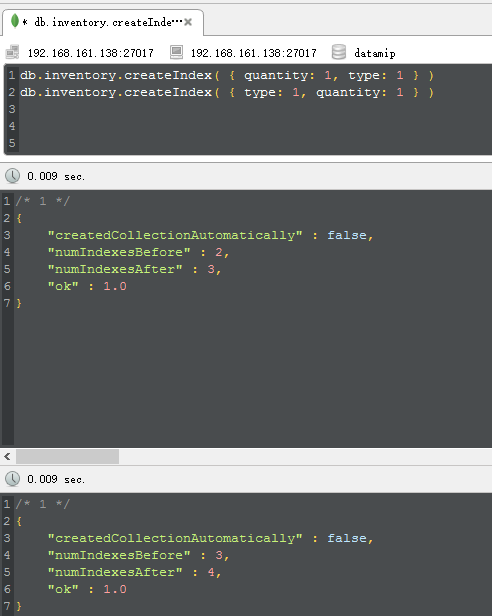
building完成之后,我们故意这一个这样的查询,针对quantity是一个范围,而type是一个定值的情况下,我们force mongodb去使用quantity开头 的复合索引,从而强制mongodb give up 那个以{type:1,quantity:1}的复合索引,很有意思哦,比如下图:
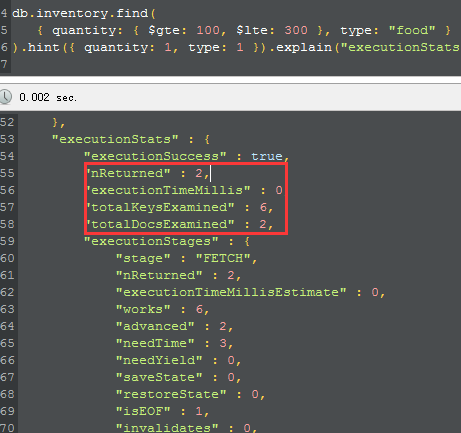
从图中,可以看到,我们检查了6个keys,而从最终找到了2个文档,现在我们就知道了,2和6之间还是有不足的地方等待我们去优化了,对吧,下面 我们不hint来看一下mongodb的最优的plan是怎么样的。

除此之外,也可以强迫查询不适用索引,做表扫描:
db.users.find().hint({"$natural":1})
关于文件系统
MongoDB在WiredTiger存储引擎下建议使用XFS文件系统。Ext4最为常见,但是由于ext文件系统的内部journal和WiredTiger有所冲突,所以在IO压力较大情况下表现不佳。
透明大页
Transparent Huge Pages (THP) 是Linux的一种内存管理优化手段,通过使用更大的内存页来减少Translation Lookaside Buffer(TLB)的额外开销。 MongoDB数据库大部分是比较分散的小量数据读写,THP对MongoDB这种工况会有负面的影响所以建议关闭。
http://docs.mongoing.com/manual-zh/tutorial/transparent-huge-pages.html
对慢查询日志进行监控
默认情况下MongoDB会在日志文件中(mongod.log)记录超过100ms的数据库操作。如下:
2020-04-03T16:53:07.985+0800 I WRITE [conn44] update fff.systemErrorLog query: { _id: "-1" } planSummary: IDHACK update: { _class: "com.xxx.yyy.base.model.SystemErrorLog", _id: "
-1", errorCode: "-1", errorInfo: "系统参数hsta.serverMode不存在,请在application.properties中设置,具体参见BaseConfigConst说明!", stackTrace: " at com.xxx.yyy.base.BaseConfig.getConfig(Bas
eConfig.java:105)
at com.xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:110)
at org.apache.iba..." } keysExamined:1 docsExamined:1 nMatched:1 nModified:1 writeConflicts:32 numYields:32 locks:{ Global: { acquireCount: { r: 33, w: 33 } }, Dayyybase: { acquireCoun
t: { w: 33 } }, Collection: { acquireCount: { w: 33 } } } 138ms
2020-04-03T16:53:07.985+0800 I COMMAND [conn44] command fff.$cmd command: update { update: "systemErrorLog", ordered: false, updates: [ { q: { _id: "-1" }, u: { _class: "com.xxx.t
a.base.model.SystemErrorLog", _id: "-1", errorCode: "-1", errorInfo: "系统参数hsta.serverMode不存在,请在application.properties中设置,具体参见BaseConfigConst说明!", stackTrace: " at com.
xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:105)
at com.xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:110)
at org.apache.iba..." }, upsert: true } ] } numYields:0 reslen:59 locks:{ Global: { acquireCount: { r: 33, w: 33 } }, Dayyybase: { acquireCount: { w: 33 } }, Collection: { acquireCount
: { w: 33 } } } protocol:op_query 221ms
2020-04-03T16:53:07.985+0800 I WRITE [conn40] update fff.systemErrorLog query: { _id: "-1" } planSummary: IDHACK update: { _class: "com.xxx.yyy.base.model.SystemErrorLog", _id: "
-1", errorCode: "-1", errorInfo: "系统参数hsta.serverMode不存在,请在application.properties中设置,具体参见BaseConfigConst说明!", stackTrace: " at com.xxx.yyy.base.BaseConfig.getConfig(Bas
eConfig.java:105)
at com.xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:110)
at org.apache.iba..." } keysExamined:1 docsExamined:1 nMatched:1 nModified:1 writeConflicts:32 numYields:32 locks:{ Global: { acquireCount: { r: 33, w: 33 } }, Dayyybase: { acquireCoun
t: { w: 33 } }, Collection: { acquireCount: { w: 33 } } } 130ms
2020-04-03T16:53:07.985+0800 I COMMAND [conn40] command fff.$cmd command: update { update: "systemErrorLog", ordered: false, updates: [ { q: { _id: "-1" }, u: { _class: "com.xxx.t
a.base.model.SystemErrorLog", _id: "-1", errorCode: "-1", errorInfo: "系统参数hsta.serverMode不存在,请在application.properties中设置,具体参见BaseConfigConst说明!", stackTrace: " at com.
xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:105)
at com.xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:110)
at org.apache.iba..." }, upsert: true } ] } numYields:0 reslen:59 locks:{ Global: { acquireCount: { r: 33, w: 33 } }, Dayyybase: { acquireCount: { w: 33 } }, Collection: { acquireCount
: { w: 33 } } } protocol:op_query 214ms
2020-04-03T16:53:07.985+0800 I WRITE [conn38] update fff.systemErrorLog query: { _id: "-1" } planSummary: IDHACK update: { _class: "com.xxx.yyy.base.model.SystemErrorLog", _id: "
-1", errorCode: "-1", errorInfo: "系统参数hsta.serverMode不存在,请在application.properties中设置,具体参见BaseConfigConst说明!", stackTrace: " at com.xxx.yyy.base.BaseConfig.getConfig(Bas
eConfig.java:105)
at com.xxx.yyy.base.BaseConfig.getConfig(BaseConfig.java:110)
at org.apache.iba..." } keysExamined:1 docsExamined:1 nMatched:1 nModified:1 writeConflicts:32 numYields:32 locks:{ Global: { acquireCount: { r: 33, w: 33 } }, Dayyybase: { acquireCoun
t: { w: 33 } }, Collection: { acquireCount: { w: 33 } } } 128ms
mongostat、mongotop
有时候,单个语句并不慢,但是整体应用慢,此时可以通过mongostat或mongotop监控整体负载情况。他们是mongodb自带的工具,和jdk的工具类似。这两个命令对于我们处理MongoDB数据库变慢等等问题非常有用,能详细的统计MongoDB当前的状态信息。除此之外,还可以用db.serverStatus()、db.Stats()、开启profile功能通过查看日志进行监控分析。
例如,查看整体当前的负载使用mongostat,如下:
[root@hs-10-20-37-72 bin]# ./mongostat insert query update delete getmore command dirty used flushes vsize res qrw arw net_in net_out conn time *0 *0 *0 *0 0 3|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 245b 51.8k 11 Apr 10 22:13:44.775 *0 *0 *0 *0 0 1|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 157b 45.3k 11 Apr 10 22:13:45.776 *0 *0 *0 *0 0 1|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 157b 45.3k 11 Apr 10 22:13:46.777 *0 *0 *0 *0 0 1|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 157b 45.2k 11 Apr 10 22:13:47.779 *0 *0 *0 *0 0 3|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 216b 45.7k 11 Apr 10 22:13:48.775 *0 *0 *0 *0 0 1|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 157b 45.3k 11 Apr 10 22:13:49.776 *0 *0 *0 *0 0 1|0 0.0% 0.1% 0 1.19G 100M 0|0 0|0 157b 45.3k 11 Apr 10 22:13:50.776
每列的含义可通过./bin/mongostat --help查看。
mongotop可以查看每个集合的负载情况,如下:
[root@hs-10-20-37-72 bin]# ./mongotop 2020-04-10T22:15:21.220+0800 connected to: 127.0.0.1 ns total read write 2020-04-10T22:15:22+08:00 admin.system.roles 0ms 0ms 0ms admin.system.users 0ms 0ms 0ms admin.system.version 0ms 0ms 0ms local.startup_log 0ms 0ms 0ms local.system.replset 0ms 0ms 0ms xx.processTemplate 0ms 0ms 0ms xx.systemErrorLog 0ms 0ms 0ms xx.systemLog 0ms 0ms 0ms xx.system_log_field_deyyyil 0ms 0ms 0ms ns total read write 2020-04-10T22:15:23+08:00 admin.system.roles 0ms 0ms 0ms admin.system.users 0ms 0ms 0ms admin.system.version 0ms 0ms 0ms local.startup_log 0ms 0ms 0ms local.system.replset 0ms 0ms 0ms xx.processTemplate 0ms 0ms 0ms xx.systemErrorLog 0ms 0ms 0ms xx.systemLog 0ms 0ms 0ms xx.system_log_field_deyyyil 0ms 0ms 0ms
它每秒钟刷新一次状态值,提供良好的可读性,通过这些参数可以观察到一个整体的性能情况。
正确使用写关注设置(Write Concern)
MongoDB的建议最小部署是一个复制集,包含3个数据节点。默认情况下应用的写操作(更新,插入或者删除)在主节点上完成后就会立即返回。写操作则通过OPLOG方式在后台异步方式复制到其他节点。在极端情况下,这些写操作可能还未在复制到从节点的时候主节点就出现宕机。这个时候发生主备节点切换,原主节点的写操作会被回滚到文件而对应用不可见。为防止这种情况出现,MongoDB建议对重要的数据使用 {w: “marjority”} 的选项。{w: “majority”} 可以保证数据在复制到多数节点后才返回成功结果。使用该机制可以有效防止数据回滚的发生。
另外你可以使用 {j:1} (可以和 w:”majrotiy” 结合使用) 来指定数据必须在写入WAL日志之后才向应用返回成功确认。这个会导致写入性能有所下降,但是对于重要的数据可以考虑使用。
正确使用读选项设置(Read Preference)
MongoDB由于是一个分布式系统,一份数据会在多个节点上进行复制。从哪个节点上读数据,要根据应用读数据的需求而定。以下是集中可以配置的读选项:
-
primary: 默认,在主节点上读数据
-
priaryPreferred: 先从主节点上读,如果为成功再到任意一台从节点上读
-
secondary: 在从节点上读数据(当有多台节点的时候,随机的使用某一台从节点)
-
secondaryPreferred: 首先从从节点上读,如果从节点由于某种原因不能提供服务,则从主节点上进行读
-
nearest: 从距离最近的节点来读。距离由ping操作的时间来决定。
除第一个选项之外,其他读选项都存在读到的数据不是最新的可能。原因是数据的复制是后台异步完成的。
不要实例化多个MongoClient
MongoClient是个线程安全的类,自带线程池。通常在一个JVM内不要实例化多个MongoClient实例,避免连接数过多和资源的不必要浪费。
对写操作使用Retry机制
MongoDB使用复制集技术可以实现99.999%的高可用。当一台主节点不能写入时,系统会自动故障转移到另一台节点。转移可能会耗时几秒钟,在这期间应用应该捕获相应的Exception并执行重试操作。重试应该有backoff机制,例如,分别在1s,2s,4s,8s等时候进行重试。
建索引要在后台运行
在对一个集合创建索引时,该集合所在的数据库将不接受其他读写操作。对数据量的集合建索引,建议使用后台运行选项 {background: true}
预读值(readahead)设置
预读值是文件操作系统的一个优化手段,大致就是在程序请求读取一个页面的时候,文件系统会同时读取下面的几个页面并返回。这原因是因为很多时候IO最费时的磁盘寻道。通过预读,系统可以提前把紧接着的数据同时返回。假设程序是在做一个连续读的操作,那么这样可以节省很多磁盘寻道时间。
MongoDB很多时候会做随机访问。对于随机访问,这个预读值应该设置的较小为好.一般来说32是一个不错的选择。
你可以使用下述命令来显示当前系统的预读值:
sudo blockdev --report
要更改预读值,可以用以下命令:
sudo blockdev --setra 32
把 换成合适的存储设备。
分配足够的Oplog空间
足够的Oplog空间可以保证有足够的时间让你从头恢复一个从节点,或者对从节点执行一些比较耗时的维护操作。假设你最长的下线维护操作需要H小时,那么你的Oplog 一般至少要保证可以保存 H 2 或者 H3 小时的oplog。
如果你的MongoDB部署的时候未设置正确的Oplog 大小,可以参照下述链接来调整:
http://docs.mongoing.com/manual-zh/tutorial/change-oplog-size.html
是否适合分页查询?分片情况下如何?
文档大小
MongoDB中BSON文档最大支持16M,用户应该避免一些特定的应用程序无限制的使文档增大。例如,电商平台应用中,很难估算每个商品可能会收到多少用户评价,所以,通常的做法是只显示一部分商品评价,比如最近的以及最广泛的评价。相比把商品和评价放在一个文档中,把每个评价或者一组评价单独放在一个文档中会更方便,同时,在存放商品的文档中存放一些主要的评价以便快速访问即可。
GridFS
大于16M的文件,MongoDB提供了GridFS这种功能,所有的驱动程序都支持这种功能。GridFS可以自动地把大的数据分成多个块,每个块256KB,同时维护这些块的元数据。GridFS能检索单个块也能检索整个文档。比如,应用可以快速的跳转到一段视频的具体某个时间戳的位置。GridFS通常用来存储照片以及视频这些比较大的二进制文件。
Capped Collections
Capped Collections是固定大小的集合,支持高流量的数据读写。Capped Collections类似于循环缓冲区:数据按照插入的顺序依次插入文档中,当集合的大小达到设定的阈值后,最先插入的数据会被删除掉,为最新插入的数据腾出空间。例如,把日志信息存储在一个高容量的Capped Collections集合中,就可以快速的检索到最新的日志信息。
https://www.cnblogs.com/Tsoagyyy/p/8877404.html
Mongodb count不准原因分析
https://yq.aliyun.com/articles/704434
Mongodb的性能优化可参考https://www.mongodb.com/blog/post/performance-best-practices-benchmarking。