提到全文检索,大多数开发人员都不陌生,其被应用于搜索引擎,查询检索等领域。我们在网络上的大部分搜索服务都用到了全文检索技术。对于数据量大、数据结构不固定的数据可采用全文检索方式,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。对于搜索引擎以外的场景,通常包括资讯、研报、企业信息及文档搜索,通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来。还可以根据中文词语进行查询,并且可能包含支持多个条件查询,根据不同的结果排序,比如相关度,相同相关度时根据日期远近排序。
全文检索的一般用法
对于结构化数据,我们一般采用数据库实现,甚至对于一小部分需要模拟匹配的字段如客户名称、企业名称等,我们也会保存在数据库中,然后通过like模糊匹配进行搜索,虽然可能速度很慢,但是还是接受了。有些并发量不高的系统也会研究下mysql全文搜索,但是发现经常出现like能够匹配到的到全文搜索后查询不到,于是只好退回到like阶段。
如果实在是慢的受不了,那就拉几个查询库,做下读写分离。如下:
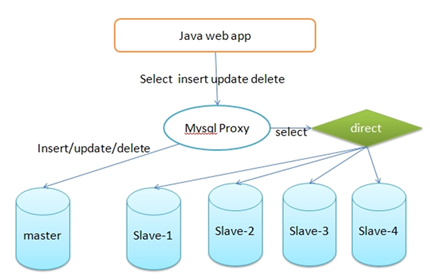
这样至少就不影响生产库了。
对于非结构化数据如资讯的搜索,通常首先想到的是Elasticsearch(后面简称ES),快、成熟、安装简单,就像mysql一样。首先将数据抽取到ES,ES会将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,该过程通常称之索引。其整体过程如下:
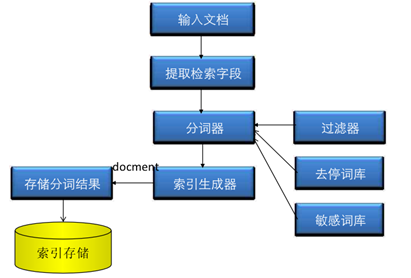
索引完成之后,会建立一个倒排索引结构(底层可能是B树或字典树),即维护词素和所属文档(Posting List,即倒排表)的对应关系,如下:
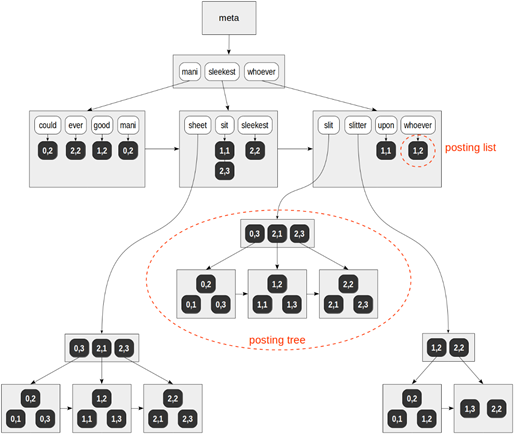
通常这棵树的键并不大(不会超过词典中词素的数量)。
这样,基于关键字进行搜索的时候,很快就能够找到要搜索的内容。同样,搜索的时候被搜索关键字仍然认为是一个文档,会首先进行分词,然后在倒排索引中搜索,最后计算相似度、权重、排序等等,最后返回结果。其过程如下:
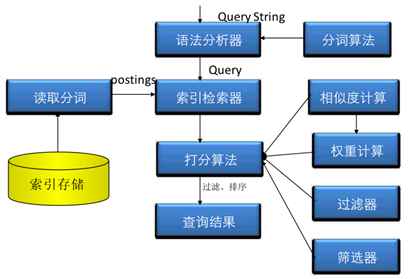
看起来完美无瑕!确实,基本搜索问题解决了。
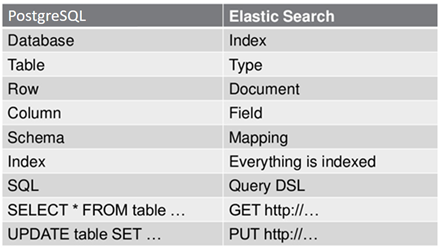
在正式开始入局之前,先看一下ES和关系型数据库主要概念的对应关系。
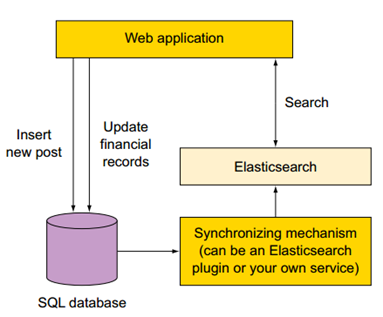
随着微服务架构的大规模应用,对于新上的系统,很多有like模糊匹配需求的系统一开始就规划了ES搜索层,数据入库后实时同步到ES。如下:
balabala,测试了一把,速度很快,终于摆脱了蜗牛一样的like,任意字段都能匹配。总结起来ES的优点包括:
终于开始进入开发阶段了。
ES全文检索失败翻车现场一
第一个功能是查询最近N天交易最活跃的客户,需要支持根据名称、资产范围、级别、网点等条件,卧槽,要关联客户信息、资产信息、交易明细balabala五张表,like还是可选的。如下:
select sum(o.xxx), sum() … from client c, asset a,order o,fund f,client_ext ce where c.id = a.c_id and c.id = o.c_id and c.id=f.c_id and c.id = ce.c_id …… group by … order by … limit 20
这尼玛让我怎么从SQL改成从ES查?全改成宽表,先不说数据一致性和同步,各种一对多逻辑怎么拆分干净、怎么保证查询正确都是个问题。
那就只缓存客户信息吧?不查询客户信息的时候,就不去ES查,好歹能够加速一把。
if (StringUtils.isNotBlank(query.getCustName()) { …… es.getClientIdList() } …...mapper.queryXXX(clientIdList);
查询恒生、升恒都没问题,那就查个姓王的吧,尼玛带王的客户有200万个!总不能在搞个黑名单吧?算了,就这样吧,不改了。以后打死不再需要复杂关联的场景用ES。有些开发会说,ES本来就不适合复杂场景,拆分SQL就解决了。
ES全文检索翻车现场二
有个功能只要查询用户/企业/资讯信息,数据量1亿,不用关联查询,但是要支持名称、简介、类别、代码等任意分页查询,最匹配的先返回,响应时间不能超过100毫秒!经过预研,mysql、oracle、分库分表后优化后都是各种慢得一塌糊涂,终于到了ES上场了!
public void query_String(){ SearchResponse searchResponse = client.prepareSearch("sanguo").setTypes("dahan") .setQuery(QueryBuilders.queryStringQuery("孙尚香")).get(); SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象 System.out.println("查询结果有:" + hits.getTotalHits() + "条"); Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()) { SearchHit next = iterator.next(); System.out.println("name : "+ next.getSource().get("name")); System.out.println("studentNo : "+ next.getSource().get("studentNo")); System.out.println("male : "+ next.getSource().get("male")); System.out.println("birthday : "+ next.getSource().get("birthday")); System.out.println("classNo : "+ next.getSource().get("classNo")); System.out.println("address : "+ next.getSource().get("address")); System.out.println("==============================================="); } }
balabala搞定了!到POC了。运维大哥来接了,提了几个问题:
1、怎么又新加技术栈了?还一次性加两个,一个搜索引擎、一个数据同步工具。语法又难学,导条数据出来都麻烦。以前查下数据写个SQL 1分钟,现在10分钟都没写正确。balabala。。。
2、监控、管理平台;
3、高可用方案;
4、性能可以满足,比以前快多了,但是测出了几个bug。客户加了数据后,有时候要查询好几次才出来,以前版本没这个问题;偶尔会出现,相同的查询条件,数据回来的顺序不一样。
5、客户IT说ES存储的是数据,要有备份、恢复方案;
6、DBA说了,全文检索不是数据库,这活人家不接,出问题业务部门自己负责。
客户说上面的一连串有方案了才能上线。对应的方案如下:
- 没办法,这个只能好说歹说ES的快、流行、安装方便、备靠大厂、支持各种搜索模式和自定义权重等各种优点了。
- 性能监控没有特别好的方案,用原生的X-Pack(基础版免费),promethous或ES-HQ;
- ES默认高可用,虽然是最终一致性。
- 因为索引的过程比较慢,ES默认1秒钟索引1次,所以理论上存在可能的延时,如果保存成功后自动立刻刷新,那是很可能无法立刻查询到数据。如果改成1毫秒1次,那基本上查询就很慢了,所以完全实时技术是不太可能。至于两次查询数据顺序可能存在不一致,主要是因为ES采用BM25和TF-IDF组合算法,多分片时,每个分片的分数有所不同,进而导致结果可能存在顺序上的差异,特别关心的同学可以参见https://blog.csdn.net/molong1208/article/details/50623948。
终于该提供的都提供了,没提供的先缓缓,推着上线了。明明以前都是8点钟下班的,现在每个月总有那么几天要搞到12点,还被实施标记待解决。所以,ES也有一些缺点。

当然,ES并不是不好,我们很可能只有几个点确实需要使用全文检索的能力,但是从整个系统的角度来看,他又很小,解决了可以让用户明显感觉到,不解决又不至于是事故。此时一体化的解决方案就非常必要,它在不引入额外成本的情况下,恰到好处的解决痛点。对客户,开发,运维及实施都是共赢。
除去管理性,使用全文检索的直接出发点通常包括:1、模糊搜索能力;2、自定义词典和中文;3、查询和插入性能; 4、索引效率与延时。1、2、3通常是同时需要必备的条件,如果这三个条件达不到要求,通常改技术就没有可行性。
模糊搜索能力
模糊搜索能力通常包括:词库中的分词直接匹配、多个分词的逻辑操作符、精确词组(比如词典中只有“恒生”和“电子”时,要能够匹配“杭州恒生电子股份有限公司”,但是不能匹配“恒生集团电子股份有限公司”,也是无法添加词库时提高搜索精确性的措施)或必须隔几个位置、支持多个字段模糊匹配,支持同时包含模糊匹配和精确匹配,支持算数表达式,支持自定义权重,得分可见性,根据权重排序,匹配分词高亮。对于即席查询,应该支持N多维度字段精确搜索。
自定义词典和中文
为了使用方便,应该支持开箱即用的中文搜索。提供在内置词典基础上增加自定义词典的功能、以及联机增加词典的功能。
查询和插入性能
因为全文检索引擎通常在分词时通常踢掉了stopword和标点,所以搜索任何内容时,性能都应该大幅度高于like操作。对于即席查询,性能也应该大幅度提升。业务可能规定了TOP 20查询TPS 1万以上,延时100毫秒以内。
对插入而言,性能应能够满足业务要求,通常是实际TPS的2倍以上。在写期间,少量的读应该能保证响应时间不会大幅度下降。
索引效率和延时
因为词典经常会变化,所以重建的效率就很重要,尤其是对亿级、数百GB或TB级别的索引来说更是如此。
不同的场景对延时通常有不同的要求,真的要求实时的场景通常不会依赖全文检索,但延时通常有一定的要求,例如不超过1秒或100毫秒。
下面来看下LightDB的全文检索能力。
PG全文检索实践
PostgreSQL(后面简称PG)从 8.3开始内核自带全文检索,并在后续版本逐渐增强。因为PG是通用数据库,全文检索是其中一个特性,从内核的角度看,只是其中一种数据结构和算法,在SQL引擎角度,也只是一堆没特殊差别的操作符和函数调用。所以全文检索能够用在任何SQL语句中,包括关联、聚合、分析函数、各种条件和函数,存储过程都能用上等等,同时事务的ACID特性和高可用也都完全满足。在数据结构上,和ES一样,PG全文检索在内部也是通过倒排索引实现。不同的是,数据插入数据库提交之后,PG全文检索不需要额外的同步操作数据就立刻对外可见,同时其分词和索引过程是实现上解耦的(该特性因此带来了极低成本的高扩展性,后面会讲到)。如下:

这是第一个优势,如果当前就是用PG,意味着没有引入任何的额外管理成本和软硬件成本。
下面来看一下PG全文检索功能和性能方面的能力。
安装PG/lightdb以及中文插件的过程就不在本文阐述,读者可以参考https://github.com/hslightdb/zhparser或baidu文章。
模糊搜索能力
除了贪婪匹配和逆文档频率外,PG全文检索几乎支持任何搜索模式。这里我们讲解几个最常用的模式。
基于未分词字符串查询
这是使用最多的用法。
select docid,industryname,title,summary,publishdate,content from search_doc_new_ic t where tsvector_title @@ to_tsquery('testzhcfg','航电龙头') order by publishdate limit 10;
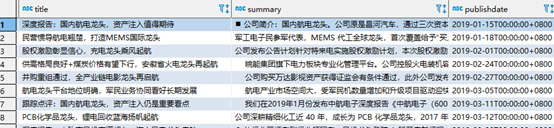
基于已分词条件查询
如果使用外部分词器,PG也支持直接基于分词搜索,不再进行二次处理。如下:
select docid,industryname,title,summary, publishdate,content from search_doc_new_ic t where tsvector_title @@ ('航电龙头'::tsquery);

此时可能查询不到记录,因为分词中没有”航电龙头”。可以通过to_tsquery查看当前PG实例中是如何分词的。
select to_tsquery('testzhcfg','航电龙头');

所以一般建议使用to_tsquery解析查询条件,不建议使用分词后的。
词组查询
需要词组查询的原因通常在于默认的分词查询匹配了过多不够精确的结果,例如查询包含”航电龙头”的资讯。
select docid,industryname,title,summary,publishdate,content
from search_doc_new_ic t
where tsvector_title @@ to_tsquery('航电龙头')
order by publishdate
limit 10;

明显很多查询不是我们希望的结果,不仅查询出包含“航电”的文档,也包含了”航”和”电”分开的。此时就要依赖词组查询特性,即多个词要连接在一起,如下:
select docid,industryname,title,summary,q,publishdate,content
from search_doc_new_ic t,phraseto_tsquery('testzhcfg','航电龙头') q
where tsvector_title @@ q;

虽然符合要求了,但是需要注意,因为GIN索引不包含位置分词的位置信息,所以会比较慢。应该仅在查询结果过多时提供额外的选项以更精确的搜索。后面提到的RUM索引提供了高性能的版本。
多字段模糊匹配
select docid,industryname,title,summary,publishdate,content
from search_doc_new_ic t
where (tsvector_content @@ to_tsquery('华泰 & 恒生 & 电子') or tsvector_title @@ to_tsquery('华泰 & 恒生 & 电子'))
order by publishdate
limit 10;
除非想明确区分开,比如前端提供了根据名称、摘要、正文搜索,否则应该仅在创建tsvector的时候,各个字段用||拼接即可。见权重一节。
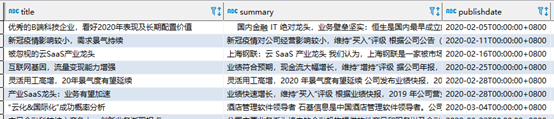
同时包含精确匹配和模糊匹配
select docid,industryname,title,summary,publishdate,content
from search_doc_new_ic t
where tsvector_content @@ to_tsquery('华泰 & 恒生 & 电子')
and publishdate > '2020-01-01'
order by publishdate
limit 10;
权重管理模式
就相关度而言,不同的应用有不同的需求,所以内置的仅供默认参考,这不仅应用于PG,也应用于ES。
setweight(vector tsvector, weight "char") returns tsvector
内置权重(weight)分为4个级别,A(1),B(0.4),C(0.2),D(0.1),setweight之后的tsvector用于在ts_rank的时候评分,不设置相当于D。
ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4
计算文档和查询分词的相关度,受到直接相关度(跟匹配数(或唯一数)、距离、某个统计学公式、词数量(或唯一数)等相关,见calc_rank_and,比较接近匹配数/分词数量*某个数学公式)、归一化、权重等因素的影响,实现在src/backend/utils/adt/tsrank.c,公式比较复杂。
如果weights没有提供,则使用vector上的权重,如果vector没有设置,则默认为D。
normalization控制归一化行为,默认是文档长度不相关(但是1或2更合适)。取值如下:
|
取值 |
算法 |
|
0(默认值) |
不归一化 |
|
1 |
分数除以lg文档长度 |
|
2 |
分数除以文档长度 |
|
4 |
分数除以分词间的平均谐波距离,仅ts_rank_cd支持 |
|
8 |
分数除以唯一分词数量 |
|
16 |
分数除以lg唯一分词数量 |
|
32 |
分数/(分数+1) |
select title,ts_rank(tsvector_title,q) rnk_no_w,ts_rank(array[0.1, 0.2, 0.4, 1.0],tsvector_title_weight,q) rnk_a_w,
ts_rank(array[0.1, 0.2, 0.4, 1.0],tsvector_title_weightd,q) rnk_d_w,
ts_rank(array[0.1, 0.2, 0.4, 1.0],tsvector_title_weight,q,1) rnk_a_w_f,
ts_rank(array[0.1, 0.2, 0.4, 1.0],tsvector_title_weight,q,2) rnk_a_w_l
from search_doc_new_ic t,to_tsquery('业绩 & 恒生') q
where tsvector_title @@ q
order by rnk_no_w desc
limit 10;

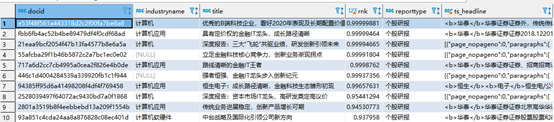
基于相关度排序
select docid,industryname,title,ts_rank(tsvector_content,q) rnk,reporttype,ts_headline('testzhcfg',content, q)
from search_doc_new_ic t,to_tsquery('华泰 & 恒生 & 电子') q
where tsvector_content @@ q
order by rnk desc
limit 10;
自定义相关度排序
在实际搜索中,通常除了相关度外,我们还会考虑流行度、内容的时效性、价格等,例如:
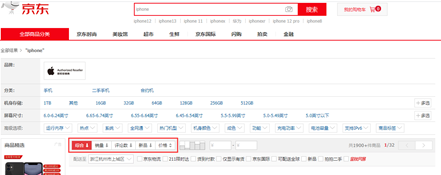
所以可能是:某因子优先,然后是相关度进行排序;某因子作为相关度的因子参与排序;标题、摘要、正文的权重分别是1,0.4,0.2。以及这些模式的自定义公式。
select docid,industryname,title,summary,publishdate,content
from search_doc_new_ic t
where tsvector_content @@ to_tsquery('华泰 & 恒生 & 电子')
order by (ts_rank(tsvector_title,q) * 10 + ts_rank(tsvector_summary,q) * 4 + ts_rank(tsvector_content,q)) desc
limit 10;
如果全文检索每个字段的权重固定,一般创建tsvector的时候即指定权重,如下:
alter table search_doc_new_ic add column tsvector_ft tsvector NULL GENERATED ALWAYS AS (setweight(to_tsvector(coalesce(title,'')), 'A') || setweight(to_tsvector(coalesce(summary,'')), 'B') ||
setweight(to_tsvector(coalesce(content,'')), 'C')) stored;
如果其它字段如日期要作为因子,只要加到order by子句即可,例如:
select … from …
order by case when publish_date >= publish_date - 7 then 1
when publish_date >= publish_date - 30 then 3 else 3 end,
ts_rank(tsvector_ft,q) desc;
RUM索引-比ES 7.x还快
除了GIN索引外,PG还支持RUM索引,存储上和ES更接近,相关度查询时性能比GIN索引快1倍(注:其缺点是索引大2倍,索引速度慢1/3)。
create index rum_search_doc_new_ic on search_doc_new_ic using rum(tsvector_content);
select docid,industryname,title,tsvector_content <=> q AS rnk,reporttype,ts_headline('testzhcfg',content, q)
from search_doc_new_ic t,to_tsquery('华泰 & 恒生 & 电子') q
where tsvector_content @@ q
order by rnk
limit 10;
<=>操作符计算tsvector和tsquery之间的距离,越近、匹配度越高,有点类似1/ts_rank。其算法比较接近normalization=16。

后面在研究RUM对权重的支持情况。
关于IDF
在ES中,计算分数时会考虑IDF因子、BM25,因为IDF大多数用户会关心,故在这里进行解析其重要性。tfidf主要弱化常见词,保留重要的词。若某个词在某个文档中是高频词,在整个语料中又是低频出现,那么这个词将具有高tfidf值,它对这篇文档来说,就是关键词,或主题词。其公式为:
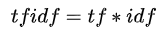 ,其中
,其中
D表示语料中所有的文档总数,d表示语料中出现某个词的文档数量,公式中的1是为了防止分母为0的情况,lg是以10为底的对数,具有类似于增强区分度的作用(拥挤的值尽可能散开,离群的值尽可能合拢)。
根据定义可知,IDF主要用于搜索多个分词的时候,搜索单个词比如“恒生电子”是没有意义的,因为它是被当做一体的,要么能搜索到、要么不能搜索到。如果“恒生电子”当做未处理的分词搜索,则只要任何包含“恒”、“生”、“电”、“子”是个字的文档都会被认为符合条件,跟本文开头搜索的“航电龙头”是一个道理,“航电”连在一起的概率比分开出现的概率要小很多,所以应该更加重要。此时它是有价值的。但是,如果我们压根不想搜索分开的结果,那么它就没有意义了,反过来它降低了搜索速度、搜索更加模糊。在分布式搜索引擎中,为了提升效率,IDF通常是分片级别的,这导致相同关键字在不同分片可能会IDF有所不同,进而造成混淆。IDF的另一种会产生排序差异的场景是包含逻辑或的搜索,比如搜索恒生电子或恒生,我们希望恒生电子的权重比恒生的要高,此时IDF就会产生价值,因为恒生电子、恒生指数、恒生银行都匹配。
因此IDF是否有价值,取决于业务场景是否需要。
高亮关键字
select docid,industryname,title ,reporttype,ts_headline('testzhcfg',content, to_tsquery('华泰 & 恒生 & 电子'))
from search_doc_new_ic t
where tsvector_content @@ to_tsquery('华泰 & 恒生 & 电子')
limit 10;
ts_headline的默认选项为:
StartSel=<b>, StopSel=</b>,
MaxWords=35, MinWords=15, ShortWord=3, HighlightAll=FALSE,
MaxFragments=0, FragmentDelimiter=" ... "

全文检索分词调试
所有全文检索相关的数据字典表以PG_ts_开头。
ts_debug
select * from PG_catalog.PG_ts_config;
SELECT * FROM ts_debug('zhcfg', '恒生电子股份有限公司研究院');
根据指定的解析器和字典,展现原文档的解析明细。
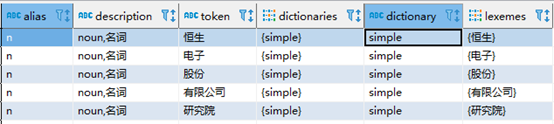
to_tsquery
将已经拆分的分词(可能规范化或没有规范化)解析为PG的tsquery(全文检索使用的匹配条件数据类型),如果直接xxx::tsquery 的话,则表示xxx已经规范化。
SELECT to_tsquery('zhcfg', 恒生电子 & 衡山电子 & Rats');
to_tsquery
---------------
'恒生电子' & '衡山电子' & 'rat'
to_tsvector
SELECT to_tsvector('english', 'a fat cat sat on a mat - it ate a fat rats');
to_tsvector
-----------------------------------------------------
'ate':9 'cat':3 'fat':2,11 'mat':7 'rat':12 'sat':4
将原始文档解析为规范化的分词及位置,PG分词的数据类型。如果直接xxx:: tsvector 的话,则表示xxx已经规范化,主要用于外部分词。
select 'The Fat Rats'::tsvector;
tsvector
--------------------
'Fat' 'Rats' 'The'
自定义词典和中文
PG最流行的中文分词插件zhparser,RDS、AnalyticDB中文全文搜索都采用zhparser,其支持自定义词库。如下:
1、准备自定义词典文件,如mydict.txt。包含内容:
恒生电子 1.0 1.0 @
黄金杠杆合约 1.0 1.0 @
ⅲ类账户 1.0 1.0 @
保存在$PGHOME/share/tsearch_data目录下。
2、在PG.conf配置文件中增加zhparser.extra_dicts = "mydict.txt" ,即可添加词素。
3、重启PG实例,即生效。这样就能搜索到恒生电子、ⅲ类账户及黄金杠杆合约了。除了离线自定义配置外,zhparser还支持在线添加和删除词素,它能够极大的提升易用性、降低交付时间,同时避免了停机时间。如下:
test=# SELECT * FROM ts_parse('zhparser', '保障房资金压力');
tokid | token
-------+-------
118 | 保障
110 | 房
110 | 资金
110 | 压力
test=# insert into zhparser.zhprs_custom_word values('资金压力');
test=# select sync_zhprs_custom_word();
sync_zhprs_custom_word
------------------------
(1 row)
test=# q --sync 后重新建立连接
[zjh@lightdb1 bin]$ ./ltsql -d postgres
postgres=# SELECT * FROM ts_parse('zhparser', '保障房资金压力');
tokid | token
-------+----------
118 | 保障
110 | 房
120 | 资金压力
通过结合select PG_terminate_backend(pid) from PG_stat_activity where backend_type=’client backend’;,能够无缝实现真正业务级别在线修改全文检索词库。但是,它只对新增的文档生效,现有索引仍然查询不到新的词素,需要进行重建。
注:LightDB 21.2版本内置zhparser插件。
即席查询
即席查询准确的说并不在全文检索的范畴,但是它有需要全文检索的技术手段。比如数据仓库中,我们需要根据任何维度进行top N查询、其中还包括名称。在Oracle中,有些用户会采用位图索引(bitmap)实现,位图索引的问题在于低并发、即使是查询,并发也很低。
默认情况下,GIN只支持数组、JSONB、tsvector。
create table wide_table(id bigserial primary key,val jsonb,c_name varchar(50),c_desc varchar(50),c_en_name varchar(100));
insert into wide_table_5000w select x,('{"d1":' || ceil(random()*(11-1)+0) || ',' ||'"d2":' || ceil(random()*(11-1)+0) || ',' ||'"d3":' || ceil(random()*(9-1)+0) || ',' ||'"d4":' || ceil(random()*(21-1)+0) || ',' ||'"d5":' || ceil(random()*(31-1)+0) || ',' ||'"d6":' || ceil(random()*(4-1)+0) || ',' ||'"d7":' || ceil(random()*(8-1)+0) || ',' ||'"d8":' || ceil(random()*(5-1)+0) || ',' ||'"d9":' || ceil(random()*(11-1)+0) || ',' ||'"d10":' || ceil(random()*(4-1)+0) || ',' ||'"d11":' || ceil(random()*(5-1)+0) || ',' ||'"d12":' || ceil(random()*(7-1)+0) || ',' ||'"d13":' || ceil(random()*(6-1)+0) || ',' ||'"d14":' || ceil(random()*(5-1)+0) || ',' ||'"d15":' || ceil(random()*(21-1)+0) || ',' ||'"d16":' || ceil(random()*(16-1)+0) || ',' ||'"d17":' || ceil(random()*(51-1)+0) || ',' ||'"d18":' || ceil(random()*(33-1)+0) || ',' ||'"d19":' || ceil(random()*(31-1)+0) || '}'::text)::jsonb,
substr(uuid_generate_v4()::text,1,cast(ceil(random()*(16-1)+0) as int)),
substr(uuid_generate_v4()::text,1,cast(ceil(random()*(32-1)+0) as int)),
substr(uuid_generate_v4()::text,1,cast(ceil(random()*(50-1)+0) as int)) from generate_series(1,50000000) x; --- 分布式12分钟,集中式25分钟
CREATE INDEX gin_idx_wide_table ON wide_table USING GIN (jsonb); -- 分布式2-3分钟,

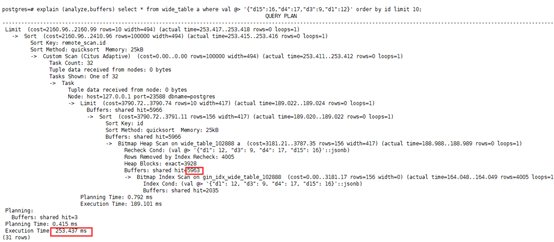

直接在JSONB类型上创建GIN索引的问题在于,GIN索引无法支持属性级别的IN,比如c1 in (1,2,3) and c2 in (x,y,z) and c3 not in (f1,f2),也不支持LIKE,>、<等操作。
create table wide_table(id bigserial primary key,c1 varchar(20),c2 varchar(20),c3 varchar(20),c4 varchar(20),c5 varchar(20),c6 varchar(20),c7 varchar(20),c8 varchar(20),c9 varchar(20),c10 varchar(20),c11 varchar(20),c12 varchar(20),c13 varchar(20),c14 varchar(20),c15 varchar(20),c16 varchar(20),c17 varchar(20),c18 varchar(20),c19 varchar(20),c20 varchar(50),val1 varchar(50),val2 varchar(100),gmt_create varchar(32));
postgres=# alter table wide_table add column my_hidden_tsvector tsvector generated always as ((c1 || ':1 ' || c2 || ':2 ' || c3 || ':3 ' || c4 || ':4 ' || c5 || ':5 ' || c6 || ':6 ' || c7 || ':7 ' || c8 || ':8 ' || c9 || ':9 ' || c10 || ':10 ' || c11 || ':11 ' || c12 || ':12 ' || c13 || ':13 ' || c14 || ':14 ' || c15 || ':15 ' || c16 || ':16 ' || c17 || ':17 ' || c18 || ':18 ' || c19 || ':19 ' || c20 || ':20' )::tsvector) stored;
ALTER TABLE
postgres=# create index idx_gin_wide_table_tsvector on wide_table using gin(my_hidden_tsvector);
CREATE INDEX
插入数据6.7亿行,640GB,取值范围来自于金融中文词语。
explain (analyze,buffers)
select /*+ Set(enable_bitmapscan on) Set(enable_seqscan off)*/*
from wide_table wt ,to_tsquery('国家专业银行 & (拓展期权 | 信用风险压力测试) & (格莱珉银行 | 法国bpce银行集团 | 法国农业信贷银行) & (中国农业发展银行 | lcf洛希尔集团)') q /*有或、与*/
where my_hidden_tsvector @@ q and not (my_hidden_tsvector @@ to_tsquery('创新型人寿保险 & 嘉禾人寿保险股份有限公司')) /* not in*/
-- and id > 40000000
-- and val2::integer > 10000 and val2::integer <100000000
-- and gmt_create::bigint > 20210928184409
order by id
limit 100;
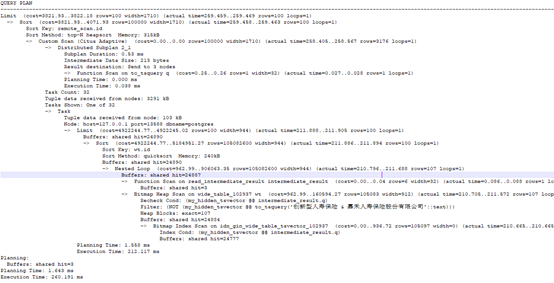
explain (analyze,buffers)
select *
from wide_table wt ,to_tsquery('国家专业银行 & (拓展期权 | 信用风险压力测试) & (格莱珉银行 | 法国bpce银行集团 | 法国农业信贷银行) & (中国农业发展银行 | lcf洛希尔集团)') q
where my_hidden_tsvector @@ q and not (my_hidden_tsvector @@ to_tsquery('创新型人寿保险 & 嘉禾人寿保险股份有限公司'))
-- and id > 40000000
-- and val2::integer > 10000 and val2::integer <100000000
-- and gmt_create::bigint > 20210928184409
order by id
limit 100 offset 1000

如果走全表扫描,性能将下降到91.9秒。
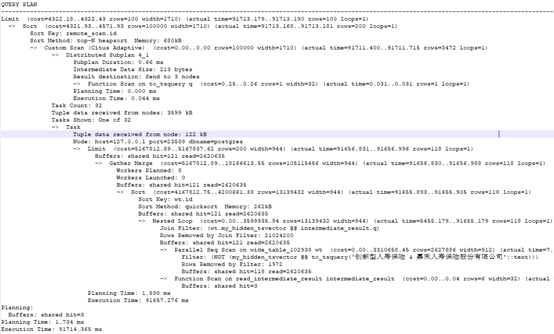
因此:
对于需要支持like比较的字段建立单独的GIN索引,总行数它不需要非常准确,比如每10分钟更新一次,如果查询中包含like,则先查找like字段上的GIN索引,如果符合条件超过1%或256,则二次recheck来过滤,不在主查询中通过GIN索引过滤,反之先查询出所有的清单,直接在GIN上过滤,避免二次check。
对于需要支持>、<判断的字段,先生成数据范围分布图。数据范围需要自定义输入。count一把。最好是distinct order by一把,知道数据的密度,可以四舍五入到1000或100,这样可以看到整体的分布。
查询和插入性能
在插入性能测试方面,PG可以用JDBC进行压测,ES可以使用REST Client客户端库压测。在32C/128GB、SSD的服务器上,并发50客户端、单记录26.6KB原始研报文档大小时,PG TPS在2100左右,ES只有1100左右,相差接近一半,CPU都达到了80%以上,无明显的I/O瓶颈。是不是哪里有问题?。限于篇幅,大家可以通过布道计划《LightDB全文检索—一种轻量级全文检索实现》获取原测试报告。
ES优化选项:无副本,5分片,索引刷新间隔30秒,事务日志1024MB、异步刷新、30秒同步间隔。
PG:全文检索列基于动态生成列的实时分析和索引。基于jieba-analysis的外部分词方案也是一样的TPS,此时PG的CPU为10%,java占80%以上。
虽然gin索引相比b树索引并发低很多,对于大文档而言,分词解析消耗了绝大部分的时间,以至于GIN索引更新还没机会达到瓶颈服务器负载就满了。所以大文本型全文检索插入的效率依赖于分词的效率、而非倒排索引(GIN)的效率。
索引效率和延时
就索引效率而言,这一部分主要指的是大批量数据导入后建立索引的性能,以及词库调整(如新增分词)之后重建索引的性能。前者通常是全量,后者es也是全量,PG默认也是全量。
通常我们词库增量更新较频繁,但是每次很少量。能搜索到ABC也一定能搜索到AB通常也能接受。增减分词仅影响索引大小。lightDB 21.3将包含一种增量技术,基于新增词素的增量索引更新。
外部分词--提升索引效率的神器
从插入和索引效率就引申出了搜索引擎支持外部分词很重要。为什么呢?因为分词非常消耗CPU,而数据库(当前Intel CPU基本只生产2路共112核心,华为鲲鹏也只生产4路共256核)达到瓶颈之后,扩容复杂、成本高。如果先在外部完成分词,然后将分词直接保存到全文检索库,通过采用k8s集合计算资源进行分布式处理,将极大的提高索引重建效率和实时插入的效率。需要注意的是,采用外部分词库时,必须确保使用的词典和搜索引擎使用的词典为同一份(示例代码可见https://www.cnblogs.com/zhjh256/p/15332948.html)。
除了提升索引效率外,外部分词还使得为不同分词定义不同的权重提供了实现途径。因为PG的tsvector结构对外开放增删改,所以对于一些专用术语,如A类账户我们可以设置权重为1,A类和账户的权重则为0.4,然后直接插入即可。如下所示:
create table my_cust_vect(v tsvector);
insert into my_cust_vect values('枣红:1A 大陆:2B'::tsvector);
select * from my_cust_vect;
v |
---------------+
'大陆':2B '枣红':1A|
这在封闭的分词器实现中几乎是不太可能的,因为它们通常仅支持字段级别的权重定义,例如标题权重为1,摘要为0.4,正文为0.1。
外部分词的最后一个重要用途是实现在线添加词库后索引的增量更新,通过计算新词素的向量,然后合并到现有向量,从而最小化建立增量向量和更新现有向量所需的资源。LightDB就采用这种方式实现增量索引。
RUM参考
PG RUM索引https://blog.csdn.net/dazuiba008/article/details/104653130
PG ADHoc(任意字段组合)查询 与 字典化 (rum索引加速) - 实践与方案1 - 菜鸟 某仿真系统 https://github.com/digoal/blog/blob/master/201802/20180228_01.md
PG 全文检索加速 快到没有朋友 - RUM索引接口(潘多拉魔盒) https://developer.aliyun.com/article/61833
PG ADHoc(任意字段组合)查询(rums索引加速) - 非字典化,普通、数组等组合字段生成新数组... https://blog.csdn.net/weixin_34220834/article/details/89697373