文本查重
GitHub地址 GitHub
1.计算模块接口的设计与实现过程
- 模块
def readtxt(filename):
#逐行读取文件,并根据标点符号进行分段,最后用jieba对文本进行分词处理
def compare(orig_txt, test_txt):
#采用余弦相似度算法计算两个文本的相似程度
def write_ans(degree, ans_path):
#将文本的相似度格式化并输出到指定文件
- 实现过程
1.对文本分词后计算词频形成两个文本的位置向量。
2.用一下公式计算两个位置向量的余弦值,余弦值越小说明两个文本的相似度越高。
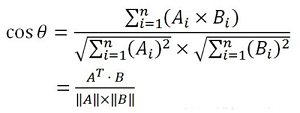
2.计算模块接口部分的性能测试
使用的性能分析工具为Python自带的cProfile工具
文本处理的性能分析:
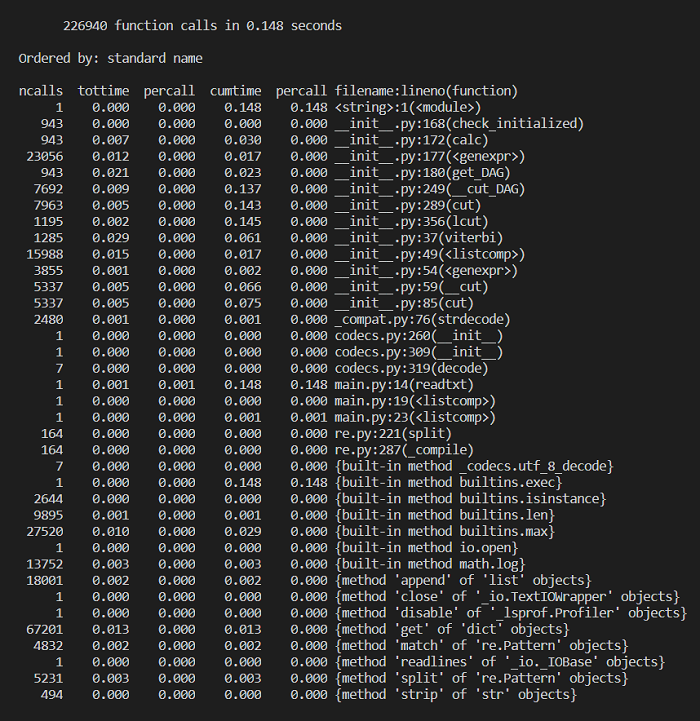
余弦相似度计算的性能分析:
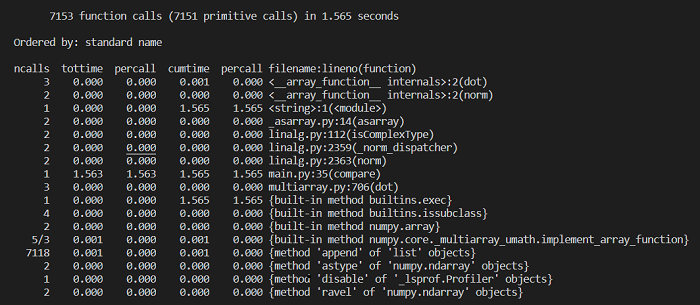
余弦相似度的运行占了总时间的64%,若是要进行优化,应该对这部分进行进一步优化。
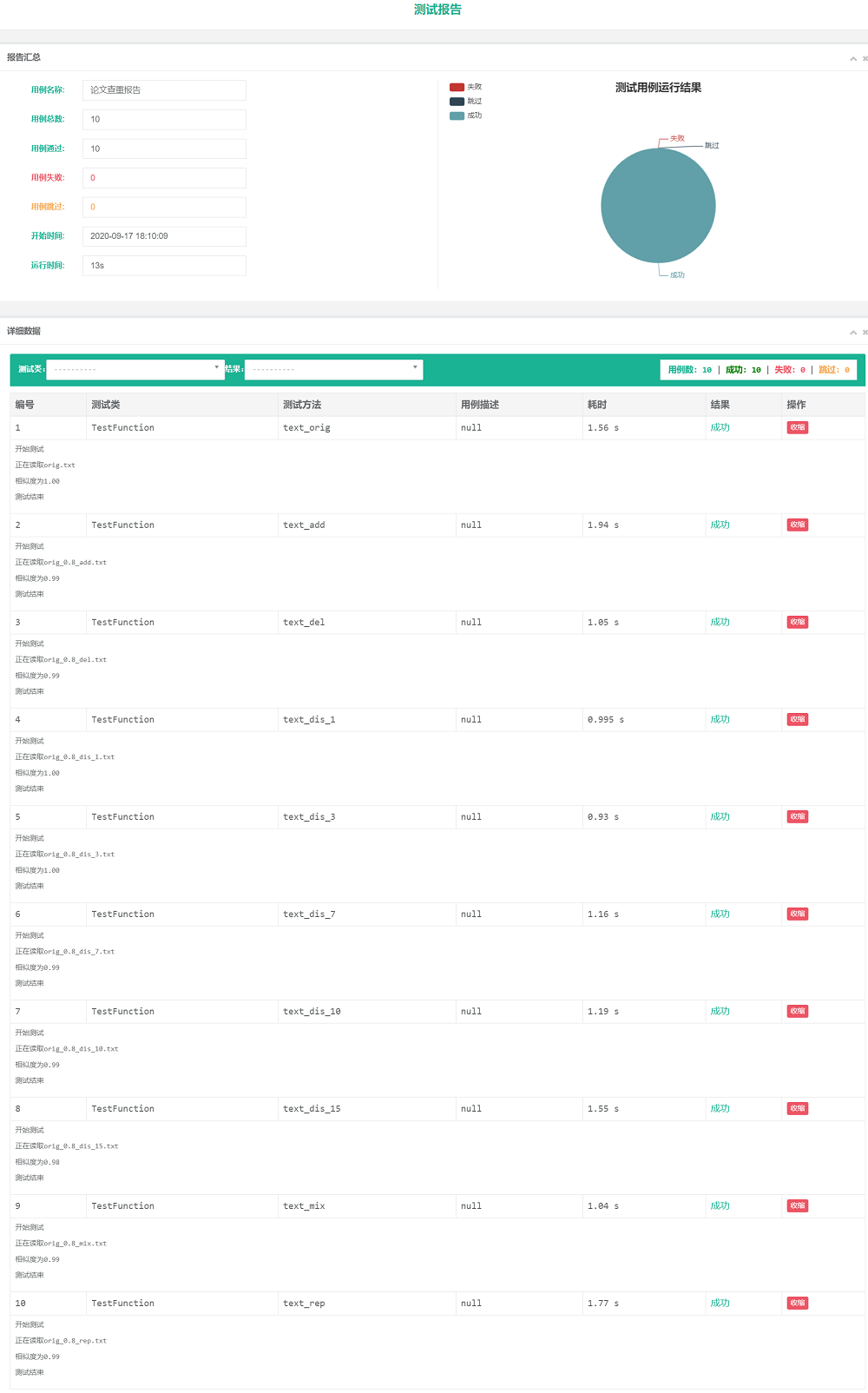
3.计算模块部分单元测试展示
- 单元测试使用了BeautifulReport,测试样例为群里的10个,结果如下:
- 单元测试代码
import unittest
from BeautifulReport import BeautifulReport
import main
class TestFunction(unittest.TestCase):
@classmethod
def setUp(self):
print("开始测试")
@classmethod
def tearDown(self):
print("测试结束")
def text_orig(self):
print("正在读取orig.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig.txt'))
print('相似度为%.2f' % degree)
def text_add(self):
print("正在读取orig_0.8_add.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_add.txt'))
print('相似度为%.2f' % degree)
def text_del(self):
print("正在读取orig_0.8_del.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_del.txt'))
print('相似度为%.2f' % degree)
def text_dis_1(self):
print("正在读取orig_0.8_dis_1.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_dis_1.txt'))
print('相似度为%.2f' % degree)
def text_dis_3(self):
print("正在读取orig_0.8_dis_3.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_dis_3.txt'))
print('相似度为%.2f' % degree)
def text_dis_7(self):
print("正在读取orig_0.8_dis_7.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_dis_7.txt'))
print('相似度为%.2f' % degree)
def text_dis_10(self):
print("正在读取orig_0.8_dis_10.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_dis_10.txt'))
print('相似度为%.2f' % degree)
def text_dis_15(self):
print("正在读取orig_0.8_dis_15.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_dis_15.txt'))
print('相似度为%.2f' % degree)
def text_mix(self):
print("正在读取orig_0.8_mix.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_mix.txt'))
print('相似度为%.2f' % degree)
def text_rep(self):
print("正在读取orig_0.8_rep.txt")
degree = main.compare(main.readtxt(r'sim_0.8orig.txt'), main.readtxt(r'sim_0.8orig_0.8_rep.txt'))
print('相似度为%.2f' % degree)
if __name__ == '__main__':
suite = unittest.TestSuite()
tests = [
TestFunction('text_orig'),
TestFunction('text_add'),
TestFunction('text_del'),
TestFunction('text_dis_1'),
TestFunction('text_dis_3'),
TestFunction('text_dis_7'),
TestFunction('text_dis_10'),
TestFunction('text_dis_15'),
TestFunction('text_mix'),
TestFunction('text_rep')
]
suite.addTests(tests)
BeautifulReport(suite).report(filename='TestReport.html',
description='论文查重报告',
log_path='.')
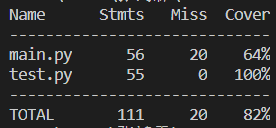
- 单元测试代码覆盖率
4.计算模块部分异常处理
- 设计了一种异常情况即:输入的文本为空
class BlankTxtError(Exception):
def __init__(self):
print("文本为空")
ans_file = open(sys.argv[3], 'w', encoding='UTF-8')
ans_file.write("相似度为0.00%%")
ans_file.close()
5.总结
- 说实话我的编程基础仅仅限于大一大二的课程所学,因此想借助这次软工实践的机会深入学习Python,
不过题目出来后感觉无从下手,在百度了一段时间后决定先快速的学习一下Python再去做作业,在花了
大约2天的时间快速的学习了一下后,开始着手研究题目的实现。在参考了大量的网上资料以及已经提交
了的同学的博客,慢慢的完成了此次作业。 - 此次作业我收获了很多:
1.巩固了我匆忙学习的Python基础
2.学会了安装Python第三方库并且使用它们
3.学会了性能分析工具cProfile和单元测试工具BeautifulReport的使用
4.学会了写单元测试程序
5.学会了Git的使用方法
6.PSP表格
| P2P | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 300 | 280 |
| Analysis | 需求分析(包括学习新技术) | 300 | 400 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 10 |
| Design | 具体设计 | 60 | 30 |
| Coding | 具体编码 | 150 | 200 |
| Code Review | 代码复审 | 150 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 150 | 120 |
| Reporting | 报告 | 30 | 30 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 30 |
| 合计 | 1450 | 1310 |