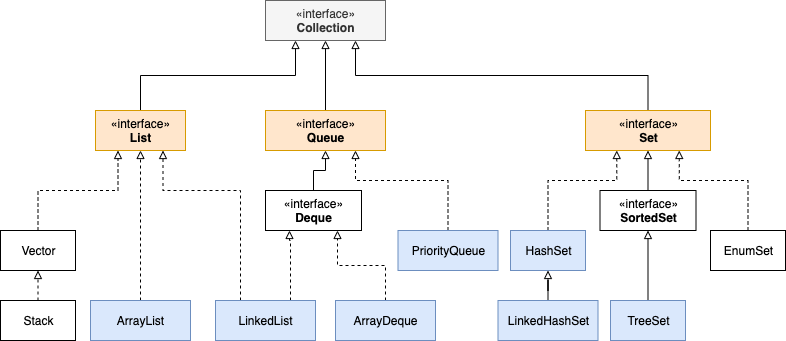
Java集合类主要由两个接口Collection和Map派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系
Java集合框架大致示意图(包含常用的集合类和大致的接口继承关系):
根接口Collection:
根接口Map:
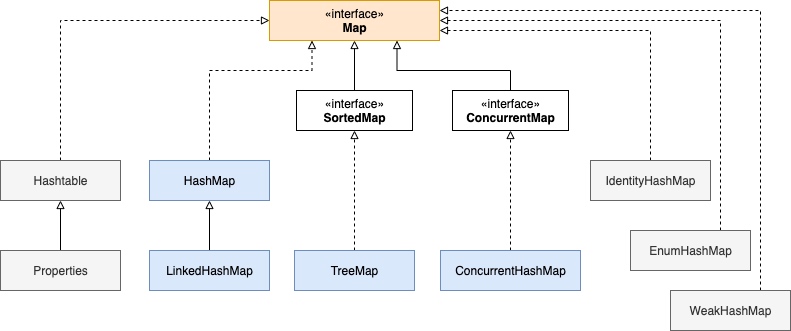
四种体系分别代表了如下内容:
List: 有序可重复集合Queue: 队列集合Set: 无序不可重复集合Map: 键值对集合
其中, 所有Collection接口的实现类均可以使用的方法有
contains(Object o) : 判断集合中是否存在指定元素
containsAll(Collection<?> c) : 判断集合中是否包含指定Collection的所有元素
isEmpty() : 判断集合是否为空
iterator() : 获取Collection对象的迭代器
size() : 获取集合中的元素个数
toArray() : 返回包含所有集合元素的Object数组
toArray(T[] a) : 返回指定类型的数组,如果a足够大,则使用该数组存储元素,并把多余的空间设置为null;否则返回一个新的同类型数组。例如可以使用下面的语句获得一个String类型数组:
String[] strs = collection.toArray(new String[0]);
List接口
基于List的集合允许元素的重复,同时提供了随机访问的方法,可以对集合中的任意元素进行操作。
ArrayList[1]
ArrayList简介
ArrayList 是一个数组队列,内部基于数组实现,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
由于ArrayList基于数组实现,那么它也有数组的一些性质,例如:
- 支持快速随机访问,即对元素的查、改可以在(O(1))时间完成
- 在数组中间的增删操作需要移动数组,时间效率不佳
- 需要占据连续的内存空间
和Vector不同,ArrayList中的操作不是线程安全的!所以,建议在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList。
ArrayList构造函数
ArrayList中提供了三种构造函数:
ArrayList(): 默认构造函数ArrayList(int initialCapacity): 传入一个初始的容量(默认值为10)ArrayList(Collection c): 使用指定的Collection构造ArrayList
ArrayList源码分析
1. 成员属性elementData和size
elementData是一个Object类型的数组,它就是ArrayList保存元素的方式。它的初始容量默认为10。当集合中的元素超出这个容量,便会进行扩容操作。需要扩容时,ArrayList会把数组容量扩大一半。
扩容操作也是ArrayList 的一个性能消耗比较大的地方,所以若我们可以提前预知数据的规模,应该通过ArrayList(int initialCapacity)构造方法,指定集合的大小,去构建ArrayList实例,以减少扩容次数,提高效率。
size就是动态数组的实际大小,即保存了多少个元素。
2. 常用操作
1. 增
- 先判断是否越界,是否需要扩容。
- 如果扩容, 就复制数组。
- 然后设置对应下标元素值。
值得注意的是:
- 如果需要扩容的话,默认扩容一半。如果扩容一半不够,就用目标的size作为扩容后的容量。
2. 删
- 删除操作会修改modCount,且可能涉及到数组的复制,相对低效。
- 批量删除中,涉及高效的保存两个集合公有元素的算法,可以留意一下。
3. 改
不会修改modCount,相对增删是高效的操作。
public E set(int index, E element) {
rangeCheck(index);//越界检查
E oldValue = elementData(index); //取出元素
elementData[index] = element;//覆盖元素
return oldValue;//返回元素
}
4. 查
数组本身支持快速随机访问,效率很高。
public E get(int index) {
rangeCheck(index);//越界检查
return elementData(index); //下标取数据
}
E elementData(int index) {
return (E) elementData[index];
}
3. 小结
- 扩容操作会导致数组复制,批量删除会导致 找出两个集合的交集,以及数组复制操作,因此,增、删都相对低效。 而 改、查都是很高效的操作。
- 与ArrayList相似的Vector的内部也是数组做的,区别在于Vector在API上都加了synchronized所以它是线程安全的,以及Vector扩容时,是翻倍size,而ArrayList是扩容50%。
LinkedList
LinkedList简介
除了List接口外,LinkedList还实现了Deque接口,提供了add/remove、offer/poll等方法,可以作为一个队列或双端队列来使用。
顾名思义,LinkedList是基于链表实现,这也使它具有链表的特点,即对结点的插入和删除效率更高,但随机访问性能较差。同时由于使用链表实现,不需要连续的内存空间,也不需要考虑扩容的问题。
和ArrayList一样,LinkedList也不是线程安全的。
LinkedList源码分析
1. 类的定义
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
从这段代码中我们可以清晰地看出 LinkedList 继承 AbstractSequentialList,实现 List、Deque、Cloneable、Serializable。其中 AbstractSequentialList 提供了 List 接口的骨干实现,从而最大限度地减少了实现受“连续访问”数据存储(如链接列表)支持的此接口所需的工作,从而以减少实现 List 接口的复杂度。Deque是一个线性 collection,支持在两端插入和移除元素,定义了双端队列的操作。
LinkedList类中有三个属性,分别为size、first、last
int size: 保存当前列表中的元素个数Node<E> first: 保存双向链表的第一个节点Node<E> last: 保存双向链表的最后一个节点
2. 提供的方法
作为List,LinkedList可以使用get(int index)获取指定位置的元素,使用add(E e)向尾部添加元素,使用remove(int index)来删除指定位置的元素。
LinkedList还可以作为双端队列使用。它实现了Deque接口,因此提供了队列和双端队列的操作方法。
由于LinkedList基于链表实现,它不能实现快速随机访问,而是需要用遍历链表的方式进行。获取指定位置的元素的实现方式如下:
// 获取index位置的结点
Node<E> node(int index) {
// assert isElementIndex(index);
// 前半部分的结点从头部开始遍历;后半部分的结点从尾部开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
LinkedList更多是用于队列或双端队列,这部分内容在Queue接口的总结中介绍。
Queue接口
在Queue接口下有三个常用的类,分别为LinkedList, ArrayDeque, PriorityQueue。
其中,Queue有一个子接口Deque,LinkedList和ArrayDeque都是基于该接口实现。
Queue和Deque接口的通用方法:
作为队列,常用的操作为从队列的一端入队、从另一端出队,以及查看下一个要出队的元素。
Queue中有两套操作的方法,都能实现相同的功能,但其中一套是遇到问题时(例如从空队列取元素或向满队列添加元素)抛出异常,另一套则是返回特殊值(false/null)
-
抛出异常型
add()方法向末尾添加元素,remove()从头部取出元素,element()查看头部元素。 -
返回特殊值型
offer()方法向末尾添加元素,poll()从头部取出元素,peek()查看头部元素。
双端队列Deque继承了Queue接口,因此它也能够进行上述操作,不过它提供了更为具体的方法,可以自由选择对头部还是对尾部操作。可以直接体现在方法名上。对于上述方法,直接在其后加上First/Last,例如:
addLast(),removeFirst(),offerLast(),pollFirst(),peekFirst(),getFirst()addFirst(),removeLast(),offerFirst(),pollLast(),peekLast(),getLast()
其中第一行对应了Queue中的方法,第二行则是Queue中无法实现的操作。除了getFirst()和getLast()替代了Queue中的element()外,其余的方法都是在原有方法上加后缀。
LinkedList
LinkedList实现了List和Deque两个接口,基于链表,允许插入null。关于List接口的部分已经介绍完毕,这里介绍它对Deque接口的实现。
LinkedList中关于添加和删除元素的操作都是基于linkFirst(), linkLast(), unlinkFirst(), unlinkLast()完成的。
linkFirst()的实现如下:
private void linkFirst(E e) {
final Node<E> f = first; // 获取头结点
final Node<E> newNode = new Node<>(null, e, f); // 根据元素值创建新结点
first = newNode; // 将新结点设为头结点
// 建立头结点和原头结点的连接
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
而linkLast()则是对尾结点进行操作,其余和上述实现相同。除此之外,还有一个linkBefore()方法,实现向链表的中间插入,它除了需要多建立一道连接外,与上述方法也类似。
从链表中删除结点的方法有unlinkFirst()和unlinkLast()以及unlink(),其中unlink()用于删除任意结点,其他两个用于删除首位结点。
例如,unlinkFirst()的实现如下:
// 这里的f是上一个调用函数传入的,并且一定为头结点。
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
其他两个方法的实现类似。
对于操作头结点的public方法,例如addFirst(), removeFirst(), offerFirst(), pollFirst(), remove()和poll()等,最终都会去调用linkFirst()和unlinkFirst()进行实际的结点操作,区别在于在操作前可以对集合状态以及输入参数的合法性进行检查。
反之那些对尾结点进行操作的方法,最终都会调用linkLast()和unlinkLast()进行实际的结点操作。
ArrayDeque
ArrayDeque是Deque的另一个实现类,这个类从JDK1.6开始引入,它和ArrayList类似,底层都基于数组实现。ArrayDeque把数组看作循环数组进行处理,以便能够更好地支持双端队列的特性,即从头部和尾部都能够方便地操作元素。
注意:
- ArrayDeque不支持插入null值
- ArrayDeque不是线程安全的
在实现队列和堆栈的时候,ArrayDeque的性能要优于LinkedList,非常重要的原因是LinkedList每插入一个元素都要使用new来创建一个结点,这会带来很大的开销;同时因为链表结构的内存地址不连续,很难命中缓存,这就导致了从主存读取的又一大的时间开销。因此如果只需要实现双端队列的功能,使用ArrayDeque通常可以获得更好的性能。
但需要注意的是,并不是所有情况下都适合使用ArrayDeque,例如当你必须在队列中保存null值时就需要使用LinkedList(尽管官方不推荐null值);另外由于ArrayDeque没有实现List接口,它也没有提供随机访问的方法,因此如果需要使用List的相关功能,ArrayDeque就无法提供。
ArrayDeqeu构造函数
ArrayDeque提供了三种构造函数,分别为默认构造、从已有Collection中构造,以及指定默认容量。下面主要介绍第三种。
在ArrayDeque源码中该构造函数实现如下:
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
// 创建一个数组用于存放元素
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
// 根据元素数量来确定初始的数组容量
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1); // 将高2位设置为1
initialCapacity |= (initialCapacity >>> 2); // 将高4位设置为1
initialCapacity |= (initialCapacity >>> 4); // 将高8位设置为1
initialCapacity |= (initialCapacity >>> 8); // 将高16位设置为1
initialCapacity |= (initialCapacity >>> 16); // 将高32位设置为1
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
我们重点关注private static int calculateSize(int numElements)这一方法。这个方法的作用是将数组的实际容量控制为大于且最接近指定值的2的整数次方。在位运算中,距离一个数最近的2的整数次幂就是比这个数高一位的比特为1,其余为0。
通过五次逻辑右移操作,可以确保把最高的1bit位和它的右边全部设置为1。然后再+1,就可以得到一个距离它最近的而且大于它的2的整数次幂了。
ArrayDeque属性和方法
在ArrayDeque中有用来存放集合元素的Object类的数组elements;头元素的下标head和尾元素的下标tail。
ArrayDeque的元素个数并不是用专门的成员变量来保存,而是使用如下方法计算返回:
public int size() {
return (tail - head) & (elements.length - 1);
}
由于数组的容量是比元素数大的2的整数次幂,那么elements.length - 1就是将最高位的右侧全部置1,其他位为0。这个与运算实际上相当于取模的操作。因为ArrayDeque作为循环数组,头元素是会向前增长过0,从而循环到到数组的末尾的,所以头结点的下标可能比尾结点更大。
1. 插入元素
ArrayDeque提供了双端队列提供的所有插入方法,实际起作用的方法有两个,分别是在头部插入的addFirst()和在尾部插入的addLast()。
addFirst()方法的源码如下:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
在头部插入,会先把head减1,并且取模,保证了下标可以循环。然后将元素放入数组的对应下标位置。
接下来判断首位结点是否相遇,如果相遇说明需要进行扩容,这时把容量扩充为原来的2倍。doubleCapacity()方法的实现如下:
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
扩容的过程大概分为以下步骤[2]:
- 检测tail是否等于head;
- 创建一个原数组容量2倍的新数组;
- 将原数组从head位置一分为二,分别拷贝到新数组中;比如数组容量16,head位置是7,则先将原数组下标从7开始,拷贝16-7个元素到新的下标从0开始,元素个数为16-7的数组中。然后将原数组下标从0开始到7的元素拷贝到新数组下标从(16-7)开始,元素个数是7的数组中。这么做的目的就是为了拷贝到新数组的时候保持元素原来的顺序。
- 重新确定头尾指针的位置。
向尾部插入的addLast()方法类似:
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
2. 删除元素
删除元素使用的方法为pollFirst()和pollLast(),分别为从头部和从尾部删除元素,在队列为空时返回null(这也是ArrayDeqeu不允许存放空值的原因之一)。其他删除方法直接调用这两个方法或在此基础上检查队列为空时抛出异常。
pollFirst()的实现如下:
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
获取元素的方式很简单,利用头部下标从数组中取出即可。同时将head+1并取模(循环数组),与插入恰好相反。而pollLast()与这个方法区别不大,就不再赘述。
小结
总体来说, ArrayDeque是实现栈和队列以及双端队列的首选,它不需要从中间删除结点,因此通过循环数组下标保存头尾结点的结构保障了它的高性能。它从首位读取元素的时间都是(O(1)),并且不需要创建新结点,而且由于数组内存空间连续的特点,连续的读取也会有较高的缓存命中率。
它的缺点是由于容量必须为2的幂次,也一定程度上降低了空间的利用率,在最坏的情况下,如果元素最大个数为(2^k),就要实际创建一个容量为(2^{k+1})的数组,浪费了一半的空间。
PriorityQueue
PriorityQueue,即优先级队列,继承自AbstractQueue,即可以实现Queue接口的所有方法。Java中的PriorityQueue是通过堆来实现的,可以通过构造方法传入比较器来决定如何判定优先级。默认为最小值堆,即队列首部的元素就是整个队列的最小值,如果有多个就取其中之一。
堆是一棵完全二叉树,而由于完全二叉树的性质决定了它可以使用顺序存储结构通过随机访问来高效实现,因此PriorityQueue的底层数据结构是数组,也有capacity,有扩容操作。
同样,PriorityQueue也不是线程安全的。
属性
private static final int DEFAULT_INITIAL_CAPACITY = 11; //默认的初始化容量
transient Object[] queue; //存放元素的数组,非私有方便嵌套类访问
private int size = 0; //元素个数
private final Comparator<? super E> comparator; // 比较器
transient int modCount = 0; // 用于实现 fast-fail 机制的
构造方法
PriorityQueue提供了多达7个构造方法,如下:
//默认无参构造器,采用初始化容量 11,无 comparator
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
//只传入指定的初始化容量,不传入 comparator
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
//只传入 comparator,采用默认容量 11
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
//传入用户指定的初始化容量和 comparator
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
//传入一个集合(非SortedSet/PriorityQueue或它的子类对象)
@SuppressWarnings("unchecked")
public PriorityQueue(Collection<? extends E> c) {
// 如果传入的集合可以被SortedSet实例化,就获取它的比较器
if (c instanceof SortedSet<?>) {
// 先进行类型转换
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
initElementsFromCollection(ss);
}
// 如果传入的集合可以被PriorityQueue示例化,那么也获取比较器
else if (c instanceof PriorityQueue<?>) {
PriorityQueue<? extends E> pq = (PriorityQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
initFromPriorityQueue(pq);
}
// 其他情况就没有比较器
else {
this.comparator = null;
initFromCollection(c);
}
}
//传入一个 PriorityQueue 类型的集合
@SuppressWarnings("unchecked")
public PriorityQueue(PriorityQueue<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initFromPriorityQueue(c);
}
//传入 SortedSet 类型的集合
@SuppressWarnings("unchecked")
public PriorityQueue(SortedSet<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initElementsFromCollection(c);
}
在上述构造方法中,使用了三种方法来从传入的集合中初始化PriorityQueue,分别是initElementsFromCollection(),initFromCollection()和initFromPriorityQueue()
// 从PriorityQueue中初始化,如果类型相同就直接从原队列中拿数据
private void initFromPriorityQueue(PriorityQueue<? extends E> c) {
if (c.getClass() == PriorityQueue.class) {
this.queue = c.toArray();
this.size = c.size();
} else {
initFromCollection(c);
}
}
// 从原来的集合中初始化,由于直接拿过来的元素不满足优先队列顺序,初始化之后需要建堆
private void initFromCollection(Collection<? extends E> c) {
initElementsFromCollection(c);
heapify(); //建堆
}
// 从集合中初始化元素的方法
private void initElementsFromCollection(Collection<? extends E> c) {
Object[] a = c.toArray(); //集合中的数组内容
// If c.toArray incorrectly doesn't return Object[], copy it.
if (a.getClass() != Object[].class)
a = Arrays.copyOf(a, a.length, Object[].class);
int len = a.length;
if (len == 1 || this.comparator != null)
for (int i = 0; i < len; i++)
if (a[i] == null) //检查是否有空元素
throw new NullPointerException();
this.queue = a;
this.size = a.length;
}
前面提到了堆是完全二叉树,可以使用数组实现。把堆的结点按照层次顺序存储到数组中,就可以通过计算下标的方式访问到它的父结点和左右子结点。对于下标为(i) 的结点:
- 父结点为:(i/2 (i ≠ 1)),若i = 1,则i是根节点。
- 左子结点:(2i (2i ≤ n)), 若不满足则无左子结点。
- 右子结点:(2i + 1 (2i + 1 ≤ n)),若不满足则无右子结点。
在PriorityQueue中,为了维持堆的特性,最重要的两个操作就是shiftUp和shiftDown。
首先我们来看shiftUp()相关方法:
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
//有比较器的时候用这个
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1; //找到当前节点 k 的父节点
Object e = queue[parent]; //取父节点
if (comparator.compare(x, (E) e) >= 0)
break;
// 如果父节点优先级小于它,就和它交换,并继续判断父节点是否需要上移,
// 直到它的优先级小于父结点或者到达了根结点
queue[k] = e;
k = parent;
}
queue[k] = x;
}
//没有比较器的时候用这个,与前面类似
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
再来看shiftDown()相关方法:
// 把下标为k的元素x下拉
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
// 有比较器的情况
@SuppressWarnings("unchecked")
private void siftDownUsingComparator(int k, E x) {
// 根据完全二叉树性质,size / 2就是第一个叶子结点的坐标。
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1; // 2k+1,即左子节点
Object c = queue[child];
int right = child + 1; // 取右子节点
//比较左右子结点找出优先级更高的一个
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
// 如果子结点有优先级高于当前结点的,就交换
queue[k] = c;
k = child;
} // 终止条件是k已经是叶节点或者k小于其所有子节点
queue[k] = x;
}
@SuppressWarnings("unchecked")
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
有了上述两个方法之后,我们再来看构造方法中的建堆操作heapify():
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
可以看出,建堆的过程就是从非叶子结点开始,自底向上地将每个结点执行一次下拉操作。这样就可以保证每次都把优先级高的结点交换到上层,直到优先级最高的被交换到堆顶。
堆的插入和删除
1. 插入结点(入队)
新结点的插入,具体的实现在offer()方法中:
public boolean offer(E e) {
if (e == null) //如果需要插入的数据为 null 抛异常
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length) // 如果队列满了就扩容
grow(i + 1);
size = i + 1;
if (i == 0) // 如果队列里尚且没有元素,
queue[0] = e; // 就插入到队列头部,也就是堆的根节点
else
siftUp(i, e); // 否则先插入尾部,然后通过shiftUp找到对应位置。
return true;
}
总的来说,新结点的插入总是在尾部进行,但是插入之后会通过shiftUp向上找到合适的位置。
2. 删除结点(出队)
优先队列的出队每次都是取出头结点,即索引为0的结点。
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0]; // 取出头结点
// 用队尾结点替代头结点
E x = (E) queue[s];
queue[s] = null;
// 下拉到合适位置
if (s != 0)
siftDown(0, x);
return result;
}
从具体的实现方式可以看出,删除头结点后需要找到一个新的头结点。而最方便的做法就是先将尾结点提到头结点,然后再依次执行shiftDown,就可以让每个结点都到对应的位置来。
3. 删除任意元素
在PriorityQueue中,还实现了一个remove(Object o)方法,可以删除堆中的指定元素。
public boolean remove(Object o) {
// 找到元素的下标
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
// 删除指定下标的元素
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size; // 获取队尾元素,并调整size
if (s == i) // 如果只有一个元素了,就直接置null
queue[i] = null;
else {
E moved = (E) queue[s]; // 用队尾元素替代被删除元素
queue[s] = null;
siftDown(i, moved); // shiftDown到合适位置
if (queue[i] == moved) {
siftUp(i, moved); // 如果没有被下拉,就尝试进行shiftUp
if (queue[i] != moved)
return moved;
}
}
return null;
}
删除堆中指定元素的步骤大致概括为:
- 找到要删除的元素的坐标
- 用队尾元素替换要被删除的元素
- 从删除位置开始执行shiftDown
- 如果shiftDown没有效果(即它不会比目前位置更低),就执行shiftUp
ArrayList部分参考自CSDN: https://blog.csdn.net/zxt0601/article/details/77281231 ↩︎
ArrayDeque部分内容参考自简书: https://www.jianshu.com/p/b29a516eb322 ↩︎