每次写完程序,按下Ctrl+F5,结束。我们从来不关心过程,正确了到还好,如果错误了我们便不知从那下手,这也是许多刚写程序的人经常苦恼的事。然而大神都是很快锁定错误范围,逐个排查。接下来给大家分享一些程序运行背后机理。
我们编写的C语言程序是源程序,计算机不能直接识别和执行高级语言所写的指令,必须用编译器把C源程序翻译成二进制形式的目标程序,然后再将目标程序与系统的函数库以及其他目标程序连接起来,形成可执行程序。
举个例子:
1 #include <stdio.h> 2 int main() 3 { 4 printf("hello world ! "); 5 return 0; 6 }
史上最简单的程序,没有之一。就从这个简单的程序入手。
事实上,上述过程可以分解为4 个步骤,分别是预处理、编译、汇编和链接,如图所示。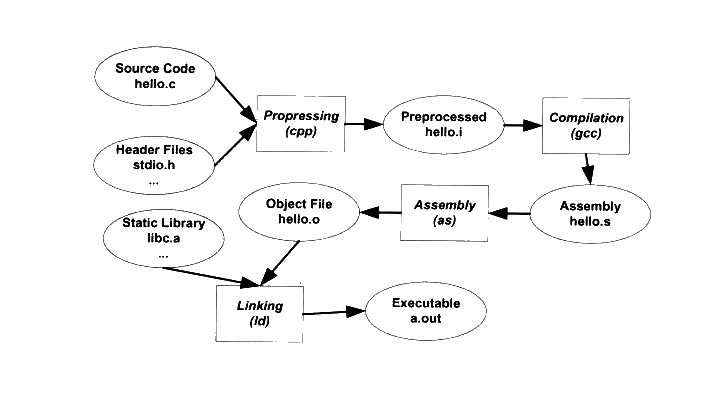
一、预处理:
首先是源代码文件hello.c 和相关的头文件,如stdio.h 等被预编译器CPP 预编译成- 一个.i 文件。对于C++程序来说,它的源代码文件的扩展名可能是.CPP 或.cxx,头文件的扩展名可能是.hpp,而预编译后的文件扩展名是ii。第一步预编译的过程相当于如下命令(-E 表示只进行预编译)
linux上调试代码 :
gcc -E hello.c -o hello.i
预编译过程主要处理那些源代码文件中的以“#”开始的预编译指令。比如“#include”.#define”等,主要处理规则如下:
1、将所有的“#define”删除,并且展开所有的宏定义。
2、处理 所有 条件预编 译指令,比如“#if”、“#ifdef"、“#elif”、"#else”、"#endif”。
3、处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件。
4、删除所有的主释“1/”和“/* */”。
5、添加行号和文件名标识,比如#2“hello.c" 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号。
6、保留所有的#pragma编译器指令,因为编译器须要使用它们。
经过预编译后的.i 文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到.i 文件中。所以当我们无法判断宏定义是否正确或头文件包含是否正确时,可以查看预编译后的文件来确定问题。
经过该步骤编译之后的文件较大包含头文件,等其他代码,此处不方便粘贴出来,大家自行调试查看。
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生产相应的汇编代码文件,这个过程往往是我们所说的整个程序构建的核心部分,也是最复杂这涉及编译原理等一些内容,的部分之一。我们将在下一节简单介绍编译的具体几个步骤,由于它不是本书介绍的核心内容,所以也仅仅是介绍而已。上面的编译过程相当于如下命令:$gcc -S hello.i -o hello.s
1 .file "hello.c" 2 .section .rodata 3 .LC0: 4 .string "hello world !" 5 .text 6 .globl main 7 .type main, @function 8 main: 9 pushl %ebp 10 movl %esp, %ebp 11 andl $-16, %esp 12 subl $16, %esp 13 movl $.LC0, (%esp) 14 call puts 15 movl $0, %eax 16 leave 17 ret 18 .size main, .-main 19 .ident "GCC: (GNU) 4.4.7 20120313 (Red Hat 4.4.7-4)" 20 .section .note.GNU-stack,"",@progbits
两种方法都可以得到汇编输出文件 hello.s, 对于C 语言的代码来说,这个预编译和编译的程序是cc1,f是对于C++来说, 对于C++来说,有对应的程序叫做cc1plus。
hello.s, 对于C 语言的代码来说,这个预编译和编译的程序是cc1,f是对于C++来说, 对于C++来说,有对应的程序叫做cc1plus。
所以实际上gcc 这个命令只是这些后台程序的包装,它会根据不同的参数要求去调用预编译编译程序CC1、汇编器as、链接器ld。
三、汇编:
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器米讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了,“汇编”这个名字也来源于此。上面的汇编过程我们可以调用汇编器as 来完成:as hello.s -o he11o.o
或者使用gcc 命令从C源代码文件开始,经过预编译、编译和汇编直接输出目标文件(ObjectFile):
gcc-c hello.c-o hello.o
四、链接:
链接通常是一个让人比较费解的过程,为什么汇编器不直接输出可执行文件而是输出一个目标文件呢? 链接过程到底包含了什么内容? 为什么要链接? 这恐怕是很多读者心中的疑惑。正是因为这些疑惑总是挥之不去,所以我们特意用这一章的篇幅来分析链接,具体地说分析静态链接的章节。下面让我们来看看怎么样调用ld 才可以产生一个能够正常运行的Hel loWorld 程序:
ld-static /u8r/lib/crt1.o /usr/1ib/crti.o /u8r/1ib/gcc/i486-1inux-gnu/4.1.3/crtbeginT.o -L/u8r/lib/gcc/i486-1iux-gnu/4.1.3-L/u8r/1ib-L/11b hello.o--start-group -1gcc-1gcc_eh-lc--end-group /u8r/1ib/gcc/1486-11nux-gnu/4.1.3/crtend.o /usr/1ib/crtn.o
如果把所有的路径都省略掉,那么上面的命令就是:
ld -static crt1.o crti.o crtbeginT.o hello.o -start -group -lgcc -lgcc_eh -lc-end-group crtend.o crtn.o
可以看到,我们需要将一大堆文件链接起来才可以得到“a.out”,即最终的可执行文件。最终机器运行的是 .o文件。当我们明白这些过程我们才能更好地理解一个程序那些地方会出错。
五、执行程序的执行也分很多阶段
阶段一:由操作系统将程序载入到内存中,同时那些不是存储在堆栈中的尚未初始化的变量将在此时得到初值
阶段二:一个处理日常事物的小型的启动程序和可执行程序连接在一起,接着便开始调用main函数
阶段三:代码开始执行
程序将使用一个运行时堆栈,该堆栈的 作用是存储函数的“局部变量”和“返回地址”;
程序同时也可以使用静态内存,存储在静态 内存中的变量在程序的执行过程中将一直保存它的值。
阶段四:程序的最后一个阶段就是程序的终止,当然终止也分为”正常终止“和”非正常终止“,正常终止就是main函数返回,非正常终止可能由多种情况引起。