在具体谈及骚操作之前先捋一遍基本的统计特征函数
| 方法名 | 函数功能 | 所属库 |
| sum() | 计算数据样本的综合(按照列计算) | pandas |
| mean() | 计算数据样本的算术平均数 | pandas |
| var() | 计算样本的方差 | pandas |
| std() | 计算样本的标准差 | pandas |
| sample() | 计算样本的Spearman(Person)相关系数矩阵 | pandas |
| cov() | 计算样本的协方差矩阵 | pandas |
| skew | 样本值的偏度;偏度系数 | pandas |
| describe() | 给出样本的基本描述(比如均值、标准差等) | pandas |
| kurt() | 样本值的峰度;峰度系数 | pandas |
| median() | 样本值的中位数 | pandas |
| quantile() | 样本4分位数 |
import pandas as pd df = pd.read_csv(r"C:UserslenovoDesktopHR.csv") >>> satisfaction_level last_evaluation ... department salary 0 0.38 0.53 ... sales low 1 0.80 0.86 ... sales medium 2 0.11 0.88 ... sales medium 3 0.72 0.87 ... sales low 4 0.37 0.52 ... sales low 5 0.41 0.50 ... sales low 6 0.10 0.77 ... sales low 7 0.92 0.85 ... sales low 8 0.89 1.00 ... sales low 9 0.42 0.53 ... sales low 10 0.45 0.54 ... sales low 11 0.11 0.81 ... sales low 12 0.84 0.92 ... sales low 13 0.41 0.55 ... sales low 14 0.36 0.56 ... sales low
首先是df.mean()
satisfaction_level 0.612839 last_evaluation 67.373732 number_project 3.802693 average_monthly_hours 201.041728 time_spend_company 3.498067 Work_accident 0.144581 left 0.238235 promotion_last_5years 0.021264 dtype: float64
df["satisfaction_level"].mean()
0.6128393333333333
df.quantile(q=0.25)
satisfaction_level 0.44 last_evaluation 0.56 number_project 3.00 average_monthly_hours 156.00 time_spend_company 3.00 Work_accident 0.00 left 0.00 promotion_last_5years 0.00 Name: 0.25, dtype: float64
df["satisfaction_level"].skew() # 偏态系数 Out[9]: -0.47643761717258093
df["satisfaction_level"].kurt() # 峰态系数 Out[10]: -0.6706959323886252
df.sample(n=10) # 给df进行抽样10个 Out[11]: satisfaction_level last_evaluation ... department salary 12624 0.38 0.50 ... sales low 12343 0.41 0.56 ... technical medium 12214 0.40 0.53 ... IT low 3607 0.64 0.66 ... sales medium 11808 0.69 0.90 ... product_mng low 6604 0.19 0.85 ... technical low 6471 0.60 0.82 ... IT low 6447 0.52 0.51 ... technical high 535 0.37 0.56 ... sales medium 10989 0.17 0.55 ... RandD low
df.sample(frac=0.01) # 给df进行抽样率为0.01 Out[12]: satisfaction_level last_evaluation ... department salary 223 0.87 0.90 ... IT low 9683 0.56 0.83 ... IT medium 5586 0.81 0.99 ... sales medium 12269 0.38 0.86 ... technical medium 208 0.44 0.50 ... support low 1412 0.46 0.46 ... technical low 11713 0.63 0.98 ... management high 10660 0.83 0.74 ... support medium 1757 0.36 0.51 ... sales low 14994 0.40 0.57 ... support low 1238 0.66 1.00 ... sales medium
基本方法就先演示这几个
骚操作一:
shift方法:
首先通过df.shift?方法来了解一下
Examples -------- df = pd.DataFrame({'Col1': [10, 20, 15, 30, 45], 'Col2': [13, 23, 18, 33, 48], 'Col3': [17, 27, 22, 37, 52]}) df.shift(periods=3) Col1 Col2 Col3 0 NaN NaN NaN 1 NaN NaN NaN 2 NaN NaN NaN 3 10.0 13.0 17.0 4 20.0 23.0 27.0 df.shift(periods=1, axis='columns') Col1 Col2 Col3 0 NaN 10.0 13.0 1 NaN 20.0 23.0 2 NaN 15.0 18.0 3 NaN 30.0 33.0 4 NaN 45.0 48.0 df.shift(periods=3, fill_value=0) Col1 Col2 Col3 0 0 0 0 1 0 0 0 2 0 0 0 3 10 13 17 4 20 23 27 File: c:userslenovoappdata oamingpythonpython36site-packagespandascoreframe.py Type: method
可以知道periods参数是用来控制移动的距离;axis是用来控制列移动还是行移动,fill_value是用来控制因为移动数据产生的NAN用什么来进行填充

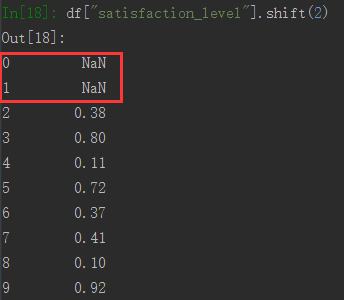 可以看到数据是集体向下移动的
可以看到数据是集体向下移动的
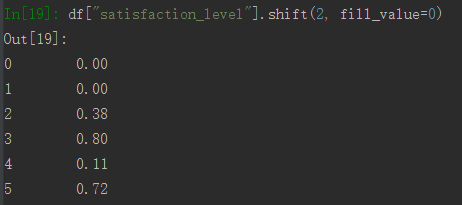 加上fill_value参数就会变成0了
加上fill_value参数就会变成0了
如果需要用到隔行相减的情况就派上用场了
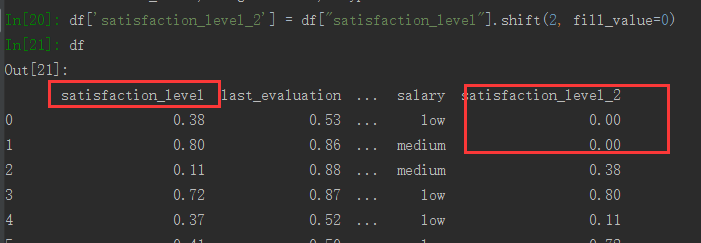
除了shift还有累计计算(cum)和滚动计算(pd.rolling)
| 方法名 | 函数功能 | 所属库 |
| cumsum() | 依次给出前1,2,3……n个数的和 | pandas |
| cumprod() | 依次给出前1,2,3……n个数的积 | pandas |
| cummax() | 依次给出前1,2,3……n个数的最大 | pandas |
| cummin() | 依次给出前1,2,3……n个数的最小 | pandas |
| 方法名 | 函数功能 | 所属库 |
| rolling_sum() | 计算数据样本的总和(按列计算) | Pandas |
| rolling_mean() | 数据样本的算术平均数 | Pandas |
| rolling_var() | 计算数据样本的方差 | Pandas |
| rolling_std() | 计算数据样本的标准差 | Pandas |
| rolling_corr() | 计算数据样本的Spearman(Pearson)相关系数矩阵 | Pandas |
| rolling_cov() | 计算数据样本的协方差矩阵 | Pandas |
| rolling_skew() | 样本值的偏度 | Pandas |
| rolling_kurt() | 样本值得峰度 | Pandas |
其中,cum系列函数是作为DataFrame或者是Series对象的方法而出现的,因此命令格式为D.cumsum(),但是rolling系列是pandas的函数,并不是DataFrame或者Series对象的方法,因此他们的使用格式为pd.rolling_mean(D,k),意思为每K列计算一次平均值,滚动计算。