函数回调
提前写出函数的调用,再去考虑函数体的实现
怎么样提前写出函数的调用:在另一个函数中写出函数的调用
再去考虑函数体的实现:根据实际的需求
def my_sleep(sec): import time current_time = time.time() while time.time() - current_time < sec: pass def download(fn=None): print('开始下载') my_sleep(1) data = '下载得到的信息' print('下载完成') if fn: # 如果外界提供了回调函数的实现体,再去调用,否则就只完成默认下载的功能 res = fn(data) # 下载成功的回调函数,具体完成什么事之后决定 if res: print('操作成功') return True print('操作失败') return False return data # 没有外界具体操作下载结果的功能代码,就将下载结果直接返回 # res = download() # print(res) def download_action(data): print('往文件中写') with open('1.txt', 'w', encoding='utf-8') as f: f.write(data) return True return False res = download(download_action) print(res) # 下载成功后的动作可以多样化 def download_action1(data): print(data) return True res = download(download_action1) print(res) # 补充: # 自定义sleep def my_sleep(sec): import time current_time = time.time() while time.time() - current_time < sec: pass print(000)
模块
模块:一系列功能的集合体
定义模块:创建一个py文件就是一个模块,该py文件名就是模块名
使用模块:在要使用该模块功能的文件中导入模块,通过import关键字导入模块名
要求:
1.了解什么是模块
2.为什么要使用模块
3.import导入模块:名称空间
4.起别名:原名与别名
5.from导入方式
6.*的知识点
7.查询顺序
8.自启文件与模块的区别
难点:循环导入
① 模块的四种存在方式:
1.使用python编写的.py文件(任何一个py文件都可以作为模块)
2.包:一堆py文件的集合体
3.使用C编写并链接到python解释器的内置模块
4.已被编译为共享库或DLL的C或C++扩展
② 优点:
1.从文件级别组织代码,是同特性功能的统一管理
2.可以使用系统或第三方模块(拿来主义),来提高开发效率
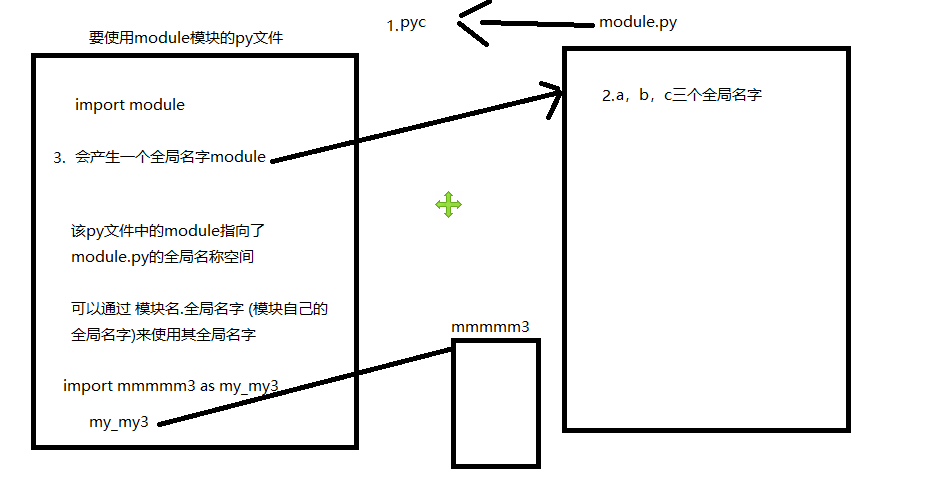
③ 导入模块:
import module
1.编译执行模块所对应的py文件,形成对应的pyc文件
2.产生该模块自己的全局名称空间
3.在使用该模块的全局名称空间中产生一个名字(导入的模块名)
④ 注意:
1.每一个文件都会产生自己的全局名称空间,且相互不影响
2.多次导入,只会编译执行模块一次,将其加载到内存,之后的都是直接对名字的引用
示例:module.py文件内容: # 每一个py文件都是一个模块,py文件名module就是模块名 a = 100 # print(a) def b(): print(a) # 局部中没有a,只能从全局或内置找 # 注:如果自身文件的全局中有,就找自身的,否则就找内置,不会找导入它的文件全局中的名字 def c(): global a a = 300 ---------------------------module.py 内容结束------------------------------- import module # 导入模块,会编译执行成一个pyc文件,该pyc文件就是该模块的执行文件 # print(module) # 再次导入,module该模块不会被执行了 import module import module import module import module
# 导入模块 import module aaaaa = module import module a = 888 module.b() module.c() print(aaaaa.a) print(a)
模块导入的过程:
起别名
通过as关键字可以给模块起别名: 模块名一旦起别名,原模块名就不能再使用
1.简化模块名字
2.统一功能
from 模板名 import 名字1 as 别名1, ..., 名字n as 别名n
# import mmmmmmmmmmmmmmmmmm3 as my_m3 print(my_m3.num) cmd = input('数据库选择 1:mysql | 2:oracle:') if cmd == '1': import mysql as db # mysql.excuse() else: import oracle as db # oracle.excuse() db.excuse()
在任何地方都可以导入模块 def fn(): global m3 import m3 # 就是普通的名字,只是该名字执行的是一个py文件(全局名称空间) print('>>>', m3.num) fn() print(m3.num)
不建议直接导入 *,因为可读性差,且极容易出现变量重名
模块中有 名字a
可以使用模块中的a
a = 20
模块中的a就被覆盖了,且在代码上还不能直接看出
import m3, m4 import m3 import m4 # 在import后的名字才会在该文件的名称空间中产生 # from m4 import a, b, _c # 指名道姓的可以导入_开头的名字 # 通过*导入: 可以将导入模块中的(除了以_开头的)名字一并导入 from m4 import * # 通常不建议导入*,当需要使用模块中绝大部分名字时,才考虑导入* print(a) a() # 两个py文件中的名字a都合理存在, # 但import后的名字a和a=20,在一个名称空间中,只会保留最后一次值 a = 20 # a() b() print(a) # _c() print(_c) # print(c)
# 一旦起别名,原名字就不能再用
from m5 import aaaaa as a, bbbbb as b, ccccc as c
print(a)
print(b)
print(c)
print("共有逻辑") if __name__ == '__main__': # 所有自执行的逻辑 print("m6: 我是自执行的") a = 10 # 产生的是全局的名字 else: # 所有模块的逻辑 print("m6: 我被导入执行的") print(a) # 会报错:走else就不可能走if,所以a压根没产生
模块的概念:一系列功能的集合体 为什么要使用模块:使用模块后的优点:1文件角度考虑代码,2拿来主义,提供开发效率 py中实现模块的方式:4种,重点:py文件 定义模块:新建一个py文件:文件名就是模块名,尽量采用全英文,可以结合数字与下划线 使用模块:可以不用起别名,但一旦起别名,原名字就不能再使用了 -- import 模块名 as 别名 -- from 模块名 import 名字 as 别名 自执行文件与模块区分:__name__