摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在centos上可以执行。
关于环境的配置,网上很多,不再废话。
仅以此系列的博客记录学习过程中的点点滴滴。
##############################传说中的分割线#####################
学习了WordCount程序,也照着网上的某些文章,实现了一些简单的MapReduce程序,可是并没有很好的总结出来如何用hadoop 写 MapReduce 程序,太多的类和接口,用起来并不顺手。终于,回过头来再仔细品品hadoop的MapReduce工作机制,做一次整体的把握。
MapReduce工作执行涉及到四个实体:
1. Client:编写MapReduce程序,配置job,提交job。
2. JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行。
3. TaskTrack:执行Map任务和Reduce任务,与JobTracker保持通信
4. HDFS:保存作业数据、配置信息,输出结果。
MapReduce的工作阶段:
first: input split (输入数据文件切片)
second:Map (执行Map task)
thrid:combiner(在Map计算出中间文件前作一个简单的合并重复key值的操作)
fourth:shuffle(将Map的输出作为Reduce的输入的过程的阶段)
fifth:reduce(执行Reduce task)
MapReduce的工作过程:
简单的讲,首先Client准备好程序,配好job,向JobTracker提交job。JobTracker收到提交来的Job之后,会着手构建Job,其中包括分配JobID,检查输出目录,输入数据文件,输出目录必须不存在(原因是如果已经存在输出目录,MapReduce的输出结果就不知道该是overwrite还是append了),输入数据文件必须存在。如果通过检查,JobTracker会根据数据文件大小计算输入分片(Input Split ),64M一片,不够64M算一片,分片完成之后,JobTracker就会配置Job所需要的资源,分配完资源,JobTracker就会初始化作业,初始化工作就是将Job放入一个内部的队列,让配置好的JobTracker能调度这个Job,JobTracker会初始化这个Job,初始化就是创建一个正在运行的Job对象(封装任务、记录信息),以便JobTracker能够跟踪这个Job的状态和进程,初始化完成后,JobTracker会获取有多少个Input Split的信息,每个分片创建一个Map任务。创建完Map任务,接下来就是分配任务了,此时TaskTracker会运行一个循环,定期发送heartbeat给JobTracker,默认间隔时间为5秒,通过heartbeat,JobTracker可以监控和获取TaskTracker的状态与问题,TaskTracker也可以通过heartbeat的返回值获取JobTracker给它的指令。任务分配完成后就是执行任务了,JobTracker通过heartbeat实时监控TaskTracker的状态、计算进度,而TaskTracker也能监控自身的状态。当JobTracker获取到最后一个TaskTracker发给它任务执行成功的通知时,JobTracker会把整个Job状态置为成功,然后当Client检查Job状态(异步行为)时会得到Job完成的通知。
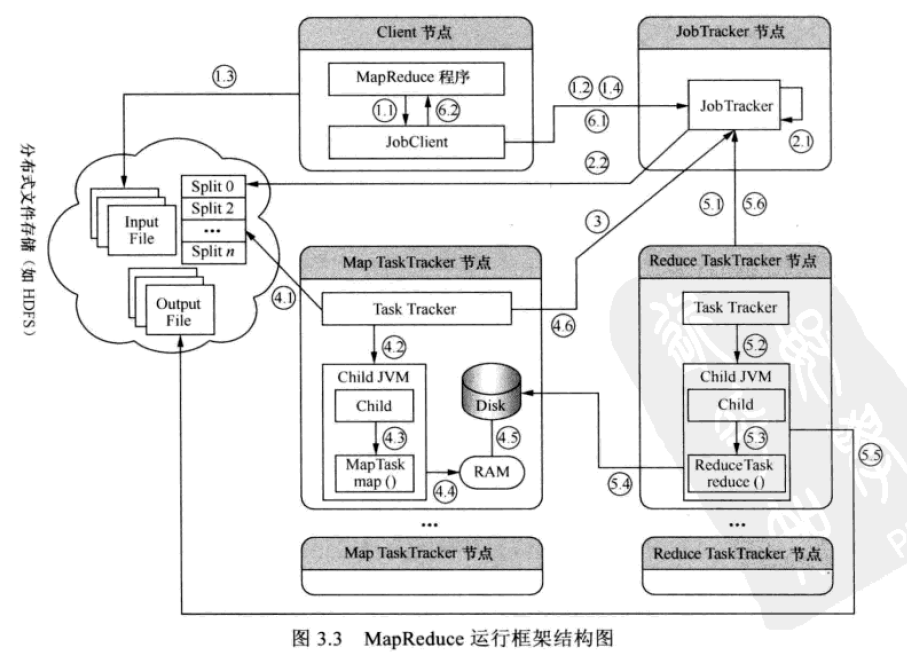
1.1:用户编写MapReduce程序创建新的Client
1.2:Client向JobTracker请求获取JobId,用于标识本次MapReduce作业
1.3:Client将运行作业所需的相关资源。包括Job的配置文件,input split数据,Mapper Reducer类的Jar文件存入HDFS
1.4:Client向JobTracker发出作业提交请求
2.1:JobTracker为作业进行初始化工作
2.2:JobTracker从HDFS中获取Client存放的input split数据信息
3:TaskTracker通过heartbeat向JobTracker询问有没有任务可做
4.1: Map TaskTracker将作业的Jar文件和作业的相关参数配置文件从分布式文件存储系统中取出,并复制到本地工作目录下
4.2:TaskTracker新建一个TaskRunner实例来运行此Map任务
4.3:TaskRunner将启动一个单独的JVM,并在其中启动MapTask执行用户指定的map()函数
4.4:MapTask计算获得的数据,定期存入缓存中
4.5:在缓存满了的情况下存入本地磁盘中
4.6:在任务执行时,MapTask定时与TaskTracker通信报告任务进度
5.1:JobTracker分配Reduce任务到Reduce TaskTracker节点中
5.2:同4.2
5.3:同4.3
5.4:ReduceTask从对应的Map TaskTracker节点中远程下载中间结果的数据文件
5.5:ReduceTask执行前向HDFS创建输出文件路径,执行时输出临时结果。
5.6:ReduceTask通过heartbeat向JobTracker通报任务进度,直到任务全部完成
6.1:Client异步轮询执行结果,获得执行完成通知
6.2:Client通知用户作业完成