存入HDFS的文件会按块(block)划分,默认每块128MB。默认1个block还有2个备份。备份增加了数据的可靠性和提高计算效率(数据本地化)。
HDFS部署可选择不支持HA,也可选择支持HA。
NameNode内存中有metadata,metadata里主要记录的信息包括:file location,ownership,permissions,block's name and location。
metadata持久化在fsimage文件中,每次NameNode启动时加载到内存。Block location的信息并不存在fsimage中,而是启动后,dataNode定时发给NameNode.
对metadata进行的操作不仅保留在内存中,同时也会写到edit log文件中。当NameNode关闭后,内存中的metadata会消失,下次启动时,会动过edit log一条条还原所有的修改,这个过程导致NameNode启动非常的慢,后来增加了SecondaryNameNode,NameNode会定期的把fsimage和edit log传给Secondary NameNode. Secondary NameNode合并fsimage和log成为新的fsimg并传回NameNode,这样下次启动的时候,就可以只读fsimage了,大大减少启NameNode启动时间。每次SecondaryNameNode对fsimage的update叫做一次checkpoint。
SecondaryNameNode并不是NameNode的failover Node,只是它的“小秘书”。
SecondaryNameNode只在非HA的模式下存在,应该安装在与NameNode不同的机器上,SecondaryNameNode同样需要NameNode一样多的内存。
HDFS的HA是为了解决NameNode的单点问题。两个NameNode一个active,一个standby。standby负责checkpoint.
DataNode控制block的访问权限并保持与NameNode的通信。
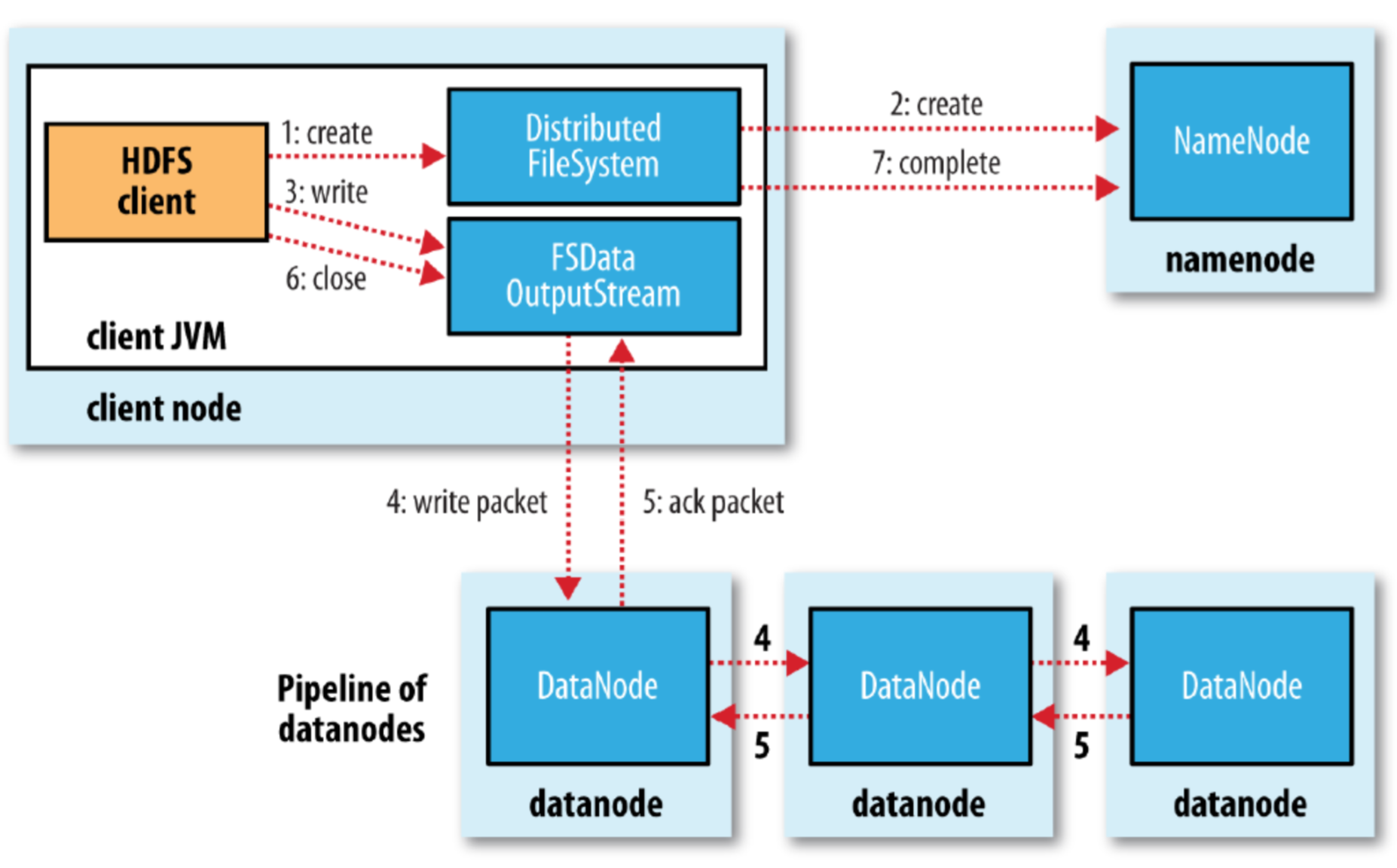
1.client connect to NameNode。
2.NameNode在metadata中为要写入的文件建立一条记录并返回可以写入的blockname和dataNode lists给client。
3.client connect 第一个DataNode,send data。
4.第一个DataNode接收到data后connect第二个DataNode,send data.
5.第二个DataNode又connect第三个dataNode,send data。
6.请求写入结果,并返回给client
7.client向NameNode发送写入完成信息。
在写入的过程中,如果第一个DataNode的pipeline断掉了,会有一个新的pipline建立起来,向第二个dataNode继续写。NameNode会继续找新的dataNode进行备份。
在block被写入时,client会对每一个block计算checksum同时发给dataNode,从而保持数据的完整性。
HDFS读数据流程:

1.client connect to NameNode。
2.Namenode返回要读出的数据所存放的datanode list(list中datanode的排序安照离client又近到远)和开头的几个block的名字。
3.client链接datanode读取数据,如果第一个datanode失去链接,则client去链接list中下一个datanode。
读取的过程中同样执行checksum。
Hadoop是机架感知的,在配好机架信息的前提下,hdfs的备份会存放在不同的机架。
DataNode每隔三秒向NameNode发送一次heartbeat,表示自己是health的。如果一段时间内NameNode没有收到某DataNode发送的heartbeat,则可认定这个DataNode lost,NameNode会把改dataNode上存储的blocks再在系统里进行一次备份,保证每个block的3备份。
Data never travels via a Namedata.
NameNode运行时,所有的metadata都在内存中,默认的NameNode堆大小为1G。1G的内存可以hold住1million的hdfs block。