先给出答案:
需要结合具体使用的source、channel和sink来分析,具体结果可看本文最后一节。
Flume事务
一提到事务,我们首先就想到的是MySQL中的事务,事务就是将一批操作做成原子性的,即这一批要么都成功,要么都失败。
同样的道理,在flume中也有事务,那么Flume中的事务在哪个地方呢?在Flume中的批量操作又是指什么呢?
- Flume中的事务存在于哪个位置?
在Flume中一共有两个事务,一个是在Source到Channel之间,一个是Channel到Sink之间。在Source到Channel之间的叫put事务,在Channel到Sink之间的叫Take事务。
- 在Flume中两个事务的批量操作指的是什么?
从source到channel过程中,数据在flume中会被封装成Event对象,也就是一批event,把这批event放到一个事务中,把这个事务也就是这批event一次性的放入channel中。同理,Take事务的时候,也是把这一批event组成的事务统一拿出来到sink放到HDFS上。
接下来我们看下这两个事务具体是怎么实现的:
1、Flume的Put事务
事务肯定有的两个特性就是:成功了提交,失败了回滚。
我们先考虑Put事务的正常的情况,即任务成功情况。
如图所示:
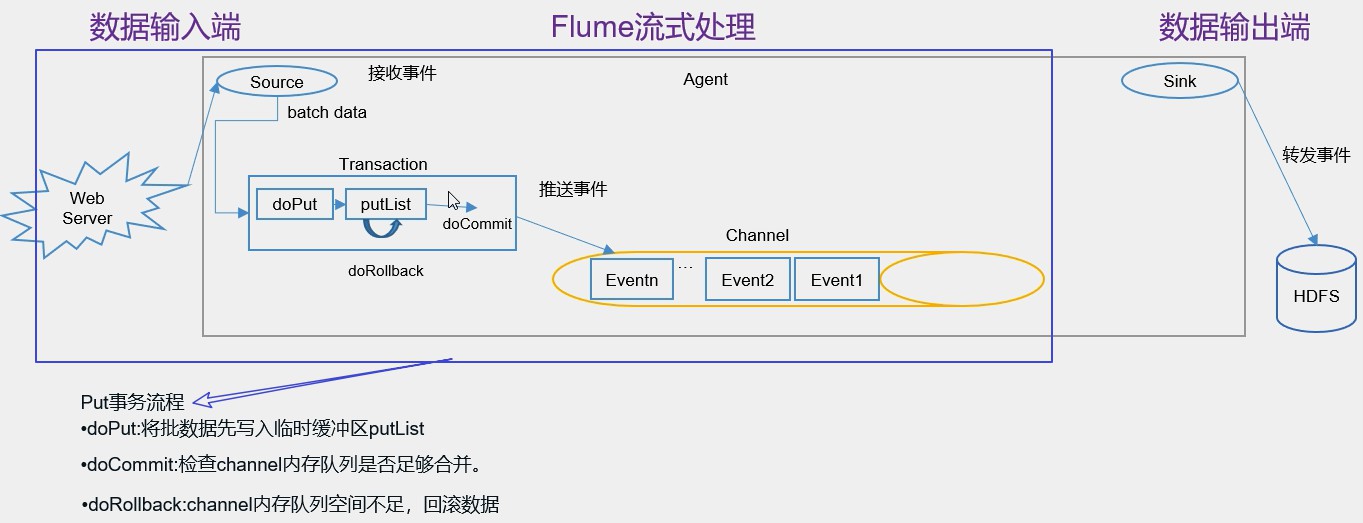
事务开始的时候会调用一个doPut方法,doPut方法将一批数据(多个event)batch data 放在putList中,而这批数据“批”的大小取决于配置的 batch size 的参数的值。而putList的大小取决于配置channel的参数transaction capacity的大小,这个参数的大小就体现在putList上了。(tips:channel的另一个参数capacity指的是channel的容量)。
现在这批数据顺利的放到putList之后,接下来可以调用doCommit方法,把putList中所有的event放到channel中,成功放完之后就清空putList。
以上是顺利的情况下,那如果事务进行的过程中出问题了怎么解决呢?
第一种问题:数据传输到channel过程出问题
在doCommit提交之后,事务在向channel放的过程中,事务容易出问题。比如:sink那边取数据慢,而source这边放数据速度快,就容易造成channel中的数据的积压,这个时候就会造成putList中的数据放不进去。那现在事务出问题了,如何解决呢?
通过调用doRollback方法,doRollback方法会进行两项操作:1、将putList清空; 2、抛出channelException异常。这个时候source就会捕捉到doRollback抛出的异常,然后source就会把刚才的一批数据重新采集一下,采集完之后重新走事务的流程。这就是事务的回滚。
(putList的数据在向channel发送之前先检查一下channel的容量能否放得下,如果放不下,就一个都不放。)
第二种问题:数据采集过程出问题
有这么种场景,source采集数据时候采用的是tailDir source,而我们因为某种原因将监控的目录文件删除,这个时候就会出现问题,同样地,出现问题的解决方式是调用doRollback方法来对事务进行回滚。
2、Flume的Take事务
Take事务和Put事务很相似。
同样地,我们先不考虑doRollback,先考虑顺利不出问题的情况下事务的完成。
如图所示:
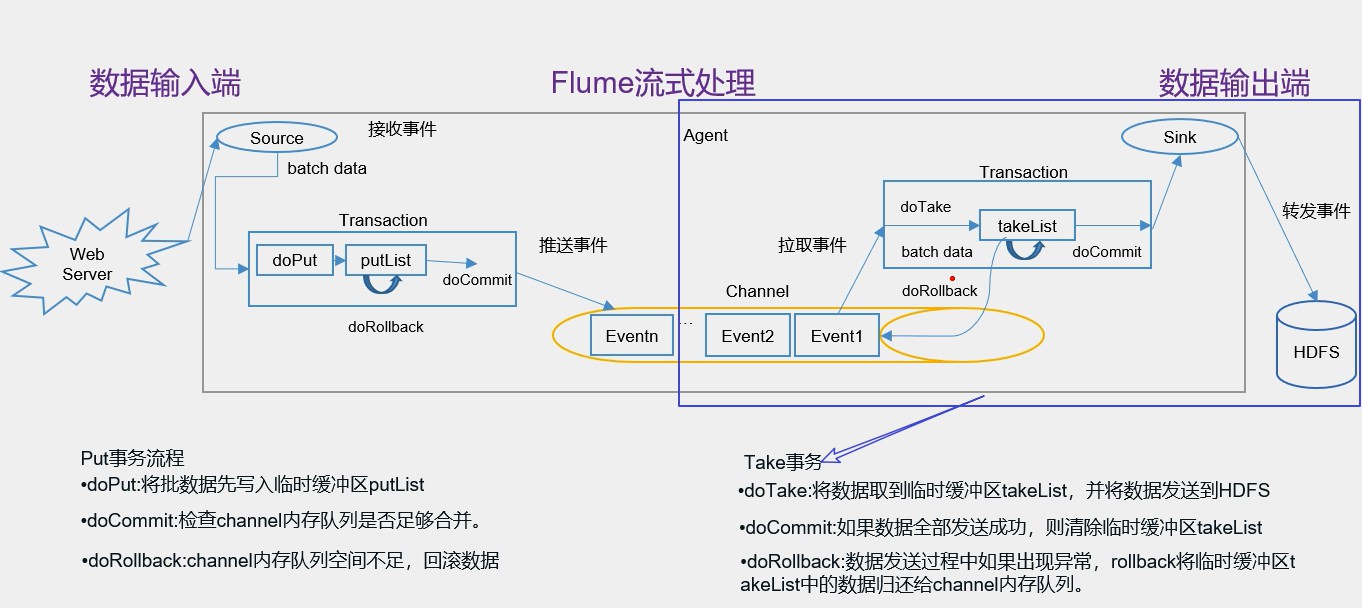
Take事务同样也有takeList,HDFS sink配置也有一个 batch size,这个参数决定sink从channel取数据的时候一次取多少个,所以这batch size 得小于takeList的大小,而takeList的大小取决于transaction capacity的大小,同样是channel 中的参数。
Take事务流程:事务开始后,doTake方法会将channel中的event剪切到takeList中,当然,后面接的是HDFS Sink的话,在把channel中的event剪切到takeList中的同时也往写入HDFS的IO缓冲流中放一份event(数据写入HDFS是先写入IO缓冲流然后flush到HDFS)。
当takeList中存放了batch size 数量的event之后,就会调用doCommit方法,doCommit方法会做两个操作:1、针对HDFS Sink,手动调用IO流的flush方法,将IO流缓冲区的数据写入到HDFS磁盘中;2、然后直接清空takeList中的数据。
以上是顺利的情况下,那如果事务进行的过程中出问题了怎么解决呢?
什么时候最容易出问题呢?——flush到HDFS的时候组容易出问题
如:flush到HDFS的时候,可能由于网络原因超时导致数据传输失败,这个时候同样地调用doRollback方法来进行回滚,回滚的时候,由于takeList中还有备份数据,所以将takeList中的数据原封不动地还给channel,这时候就完成了事务的回滚。
但是,如果flush到HDFS的时候,数据flush了一半之后出问题了,这意味着已经有一半的数据已经发送到HDFS上面了,现在出了问题,同样需要调用doRollback方法来进行回滚,回滚并没有“一半”之说,它只会把整个takeList中的数据返回给channel,然后继续进行数据的读写。这样开启下一个事务的时候就容易造成数据重复的问题。
所以,在某种程度上,flume对数据进行采集传输的时候,它有可能会造成数据的重复,但是其数据不丢失。
3、flume传输是否会丢失或重复数据?
这个问题需要分情况来看,需要结合具体使用的source、channel和sink来分析。
首先,分析source:
(1)exec source ,后面接 tail -f ,这个数据也是有可能丢的。
(2)TailDir source ,这个是不会丢数据的,它可以保证数据不丢失。
其次,分析sink:
(1)hdfs sink,数据有可能重复,但是不会丢失。
一般生产过程中,都是使用 **TailDir source **和 HDFS sink,所以数据会重复但是不会丢失。
最后,分析channel
要想数据不丢失的话,还是要用 File channel,而memory channel 在flume挂掉的时候还是有可能造成数据的丢失的。