论文地址:https://arxiv.org/pdf/2004.14514
摘要
在实际应用中,可解释性依据在模型预测中占据着重要地位。在本文中,我们为结构化预测开发拥有可解释性的推理过程的模型。尤其,我们提出一个基于实例学习来学习span之间的相似度。在推理时,根据在训练集的相似span为每一个span分配一个类标签,由此很容易理解每个训练实例对预测的贡献度。通过在命名实体识别上的实验分析,我们说明我们的方法能够建立高可解释性且不会牺牲性能的模型。
1 引言
神经网络在结构化预测的性能提升上做出了贡献。但是模型预测的依据却很难为人们所理解。在实际运用中,可解释化依据在驱动人们决定和提高人机协作上起了关键性作用。由此,我们旨在简历高可解释性且不牺牲性能的模型。作为此类挑战的方法,我们聚焦于基于实例的学习。
基于实例的学习是一个学习实例之间相似度的机器学习方法。在推理时,最相似的训练实例的类标签被分配给新的实例。这个易懂的推理过程提供了以下问题的答案:训练集中的哪个点最接近测试点或者影响预测?这被归类为基于例子的解释。最近尽管它具有优良特性,但是却得到很少关注或者没有被充分探索。本文展现并调查了一个学习span表示的基于实例的方法。一个span是指包含一个或多个语言相关的单词的单元。为什么我们关注span而不是token呢?一个原因是关乎性能。最近的神经网络可以引入好的span特征表示并实现在结构化预测任务上的高性能,比如在NER、选区分析、语义标注以及共指问题。另一个原因和可解释性相关。上述任务需要识别由span组成的语言结构。所以,比起基于token的分类如BIO标记,直接为每个基于其表示的span分类更具可解释性,即从基于token的BIO标签预测中重构每个span标签。
我们的方法建造在同类标签的span都相互靠近的特征空间。在推理时,每个span都根据特征空间找其另据span来分配类标签。我们很容易理解为什们模型要通过找寻邻居来为span分配标签。通过NER的质和量的分析,我们说明我们基于实例的方法能够建造具有高可解释性和高性能的模型。总的来说,我们呢的主要贡献如下:
这是第一篇调查基于实例的span表示的工作。
通过在NER上的实例分析,我们说明我们基于实例的方法能够建造具有高可解释性且不牺牲性能的方法。
2 相关工作
神经网络模型具有很普遍的技术挑战:黑盒属性。模型预测下的依据很难为人类所理解。许多近期工作都试图观察基于分类器的网络模型。本文建造基于实例学习的可解释模型,而不是观察黑盒。
在如今的神经网络时代之前,基于实例学习也叫基于记忆学习被NLP任务广泛应用,如词性标注,依存分析,机器翻译等任务。在NER任务中,一些基于实例的模型也被提出。最近,尽管这个方向具有高可解释性,但是还没被探索。
不同于我们的工作, Wiseman and Stratos 采用基于实例的token表示学习。使用BIO标注方式,面临一个技术挑战:不一致的标签预测。比如,实体“World Health Organization”可以被标注为不一致的标签如“B-LOC I-ORG I-ORG”,而真实标签是“B-ORG I-ORG I-ORG”。为了解决这个问题,他们提出了层次技术提高连续token标签一致。不同于这类基于token的预测,我们采用基于span的预测,这自然能避开这类问题,因为每个span都被分配到同一标签。
NER一般可分为两种解决方式:(i)序列标注(ii)span分类。在第一个方法中,通过使用神经网络并输入到如CRF的分类器中来引入token特征的。这种方法很难处理嵌套实体。相反,本文所采用的span分类方法可以直接解决嵌套实体。
3 基于实例的span分类
3.1 NER作为span分类
NER可以作为多分类问题来解决,其中句子中每个可能的span都被分配到一个类方法。正如我们在Section 2中提到的,这种方法可以避开不连续的标签预测并能直接处理嵌套实体。由于这种相较于基于token分类的优点,span分类得到了很大的关注。
给定一个有T个单词的句子X=(w1,w2,...,wT),我们首先列举出可能的spanS(X),并给每个span分配类标签。我们将把每个span写成s=(a,b),其中a和b作为句子的word下标:1<=a<=b<=T。如下有个句子: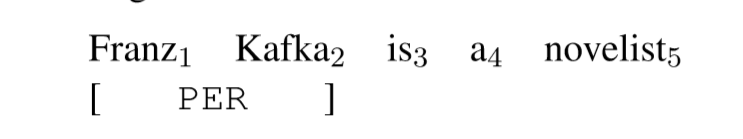
那么可能的spans即为![]() 。
。
Franz Kafka,s=(1,2),被分配人名类标签(y=PER)。注意其他的非实体span被分配到null标签(y=NULL)。比如,“a novelist”,s=(4,5),被分配NULL。在这个地方,NULL标签被分配给非实体span,这和BIO标签集中的O标签一样。
每个span s被分配标签y的概率可使用softmax函数建模:
通常,使用每个标签的权重向量Wy和span特征向量Hs来作为打分函数:![]()
而NULL标签的得分被设为一个常数,![]() ,这和逻辑回归相似。
,这和逻辑回归相似。
我们用来训练收敛的loss函数为负的log-likelihood: 
此处S(X,Y)是个span对的即和并且其正确的标签是y。我们把这类模型叫做使用标签权重向量,来做基于分类器的span模型的分类。
3.2 基于实例的span模型
我们基于实例的span模型根据span之间的相似度对每个span进行分类。在图一中,一个实体“Franz Kafka”以及训练集的span被映射到特征向量空间,并且标签分布根据他们之间的相似度进行计算。在这个推理的过程中,很容易理解每个训练实例对预测的贡献度有多大。这一属性允许我们通过特定的训练实例来解释预测,这被归类为基于例子的解释。
形式上,在邻居组件分析框架中,我们定义邻近span概率为每个span会在训练集中的备选span中选择其他span作为它的邻居:

这儿我们从训练集D中排除输入句子X以及它的真实标签Y,![]() ,并且把其他所有的span都作为候选者:
,并且把其他所有的span都作为候选者:![]() 。这个打分函数将返回两个span si和sj的相似度。然后我们计算si的标签为yi的概率:
。这个打分函数将返回两个span si和sj的相似度。然后我们计算si的标签为yi的概率: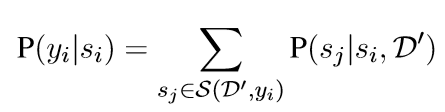
其中,![]() ,所以该等式表明我们把所有和si相同标签的邻居span的概率相加。loss函数是:
,所以该等式表明我们把所有和si相同标签的邻居span的概率相加。loss函数是:![]()
S(X,Y)是si对集合,它的真实标签是yi。推理时,我们根据最大边缘概率来预测标签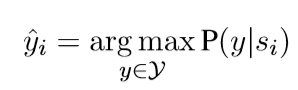
其中为每个标签集合计算概率![]() 。
。
高效邻居概率计算
等式一中邻居span概率![]() 取决于中各训练集
取决于中各训练集![]() ,计算成本太高。解决方法是使用随机采样来从训练集
,计算成本太高。解决方法是使用随机采样来从训练集![]() 检索K个句子
检索K个句子![]() 。训练时,从每个epoch的每个mini-batch中随机采样K个句子。这个简单的技术实现了训练时在时间和内存两方面的高效。在我们的实验重,使用单个GPU训练一个模型仅仅需要不超过一天的时间。
。训练时,从每个epoch的每个mini-batch中随机采样K个句子。这个简单的技术实现了训练时在时间和内存两方面的高效。在我们的实验重,使用单个GPU训练一个模型仅仅需要不超过一天的时间。
4 实验
4.1 实验步骤
数据 我们使用2种NER来评估span模型:(i)CoNLL-2003数据集的flat NER(ii)GENIA数据集的嵌套NER。我们遵从标准的训练-验证-测试划分模式。
基线 我们使用基于分类器的span模型作为基线。只是在根据基于实例还是根据基于分类器span模型的来决定是否使用softmax分类器,这方面有所不同。
编码及span表示 我们采用Ma and Hovy提出的编码结构,这种结构使用word embedding和字符级CNN来编码输入句子的每个token。这个编码后的token表示![]() 被输入到双向LSTM中来计算上下文向量
被输入到双向LSTM中来计算上下文向量![]() 和
和![]() 。之后,我们基于 LSTM-minus 为每个span生成
。之后,我们基于 LSTM-minus 为每个span生成![]() 。对于flat NER我们使用表示
。对于flat NER我们使用表示![]() 。对于嵌套NER,我们使用
。对于嵌套NER,我们使用![]() 。接着我们使用
。接着我们使用![]() 和权重矩阵W相乘得到
和权重矩阵W相乘得到
![]() 。对于在基于实例的span模型中的等式一中的打分函数,我们使用两个span表示的内积:
。对于在基于实例的span模型中的等式一中的打分函数,我们使用两个span表示的内积:![]() 。
。
模型配置 我们从每个mini-batch中随机检索K=50个训练句子进行模型训练。在测试时,我们根据cos相似度计算来选择K=50个最邻近的训练句子。对于词嵌入,我们使用GloVe的100维embedding和BERTembedding。
4.2 量化分析
我们随即跑了五次模型训练得到平均值。
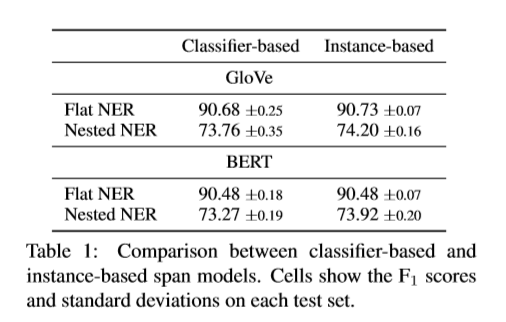
总体F1值 我们调查了是否我们基于实例的span模型能到达和基于分类器span模型相应的性能。表一展示了每个测试集上的F1值。同样的,基于实例的span模型和基于分类器的span模型结果相当。这表明我们基于实例的学习方法能够不牺牲性能构造NER模型。
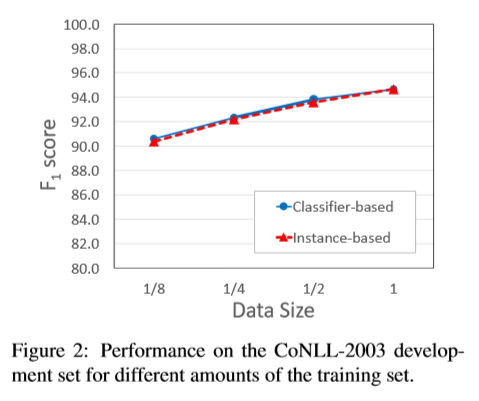
在训练数据规模的效率 图2展示了模型分别训练了所有、1/2、1/4、1/8的训练数据,得到的CoNLL-2003验证集的F1值。我们发现(i)随着训练数据的减少,两个模型的性能逐渐降低。(ii)两个模型的指标曲线相当。
4.3 质化分析
为了更好的理解模型的表现,我们具体使用GloVe来分析基于实例的模型。
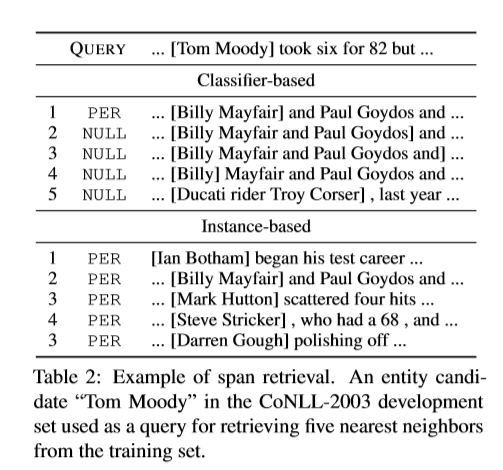
检索span的例子 我们方法学习到的span特征空间能够应用到不同的下游任务。尤其,它能用来作为span检索系统。表二展示了实体“Tom Moody”的5个最邻近的span。在基于分类器的span模型中,人名相关但没有实体的span被检索到。相反,在基于实例的span模型中,人名实体一直被检索到。这个趋势可以从许多其他例子中观察到,而且我们也确信我们的方法能在应用中建立更好的特征空间。
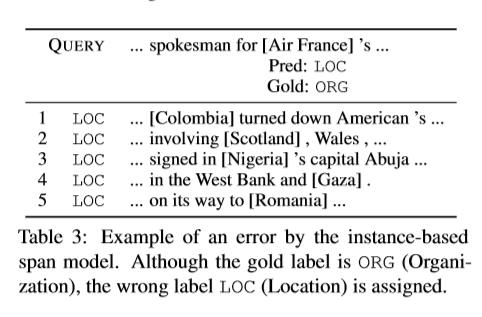
错误分析 基于实例的span模型倾向于错误的给包含地名或组织名的span打标签。比如,在表三中,“Air France”的真实标签是ORG,但是被错误的标为LOC。通过观察邻居,我们可以理解模型容易混淆国家或地区实体。这表示预测错误很容易分析,因为邻居是预测的依据。
4.4 讨论
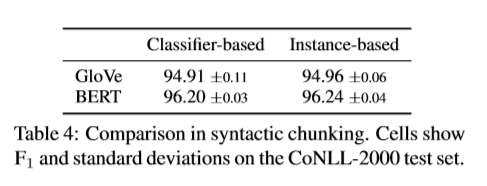
普适性 我们在NER上的研究发现能适应于其他任务吗?为了调查这个,我们做了在CoNLL-2000的句法组块的另一个实验。尽管根据短span分类,这个任务和NER很像,但是这个类标签是居于句法而不是语义。在表4中,和NER上的结果一样,基于实例的的span模型实现和基于分类器的是一样的F1结果。这表明我们在NER上的研究发现同样适用于其他短span分类任务。
未来的工作 一个未来的工作的兴趣线是将我们的方法扩展到span-to-span相关的分类中,比如SRL和共指。另一个潜在方向是应用和评估span特征到需要实体知识的下游任务,比如实体链接和问答。
5 结论
我们展示并调查了一个学习span之间相似度的基于实例的学习模型。通过NER实验,我们说明了用我们的方法的模型具有(i)和基于分类器的span模型相当的性能(ii)说明推理过程,从中非常容易理解每个训练实例对预测的贡献度。
论文中涉及的表和图: