摘要
本论文提出了一个新的框架,MGNER,该框架是为了解决多粒度命名实体识别,该任务是指一个句子中的多个实体不会发生重叠或者完全被嵌套的情况。不同于传统的方法把NER视为序列标注任务并连续标注实体,MGNER在多粒度上检测并识别实体:它能够识别命名实体,而无需显式地假定不重叠或完全嵌套的结构。MGNER包含一个检测器,能够检查所有可能地单词切分,和一个分类器,能够进行实体类别划分。另外,在整个框架中,使用了环境信息和一个字注意力机制来提高NER性能。实验结果表明,在嵌套/非重叠的NER任务中,MGNER的F1值比目前最流行的baseline的高了4.4%。
1 引言
有效地从文本中识别有意义的实体在理解自然语言的语义中起了很重要的作用。这一过程即是命名实体识别(NER),是自然语言处理(NLP)的基础任务之一。一个典型的NER系统把话语作为输入,而输出为识别的实体,比如人名,地名和机构名。这类被提取出来的实体对于序列NLP任务有帮助,包括语义解析,问答,以及关系提取。然而,要能较为准确的识别不同的实体时间很有挑战的事。
过去的工作把NER作为序列标注问题。比如,Lample等人实现了在NER任务上可观的效果,使用的是RNN和CRF。然而,一个重要的问题是把NER作为序列标注问题,只能在单个的序列scan的文本中识别没有重叠的实体。但是不能识别嵌套的实体,这类实体倍嵌入到更长的实体中了,如下图所示:

由于自然语言的语义结构,嵌套实体很普遍:比如ACE-2004的测试集中,47%的实体和其他实体有重合,而42%的句子包含嵌套实体。在过去十年中,在提取嵌套命名实体问题上,有很多方法被提出来了。然而,这些模型是专门设计出来做嵌套实体任务的。通常相对于序列标注模型,这类模型通常在非重叠命名实体上表现不佳。
为了解决以上提到的问题,我们提出了新的神经网络框架,MGNER,用来做多粒度命名实体。这个模型既能处理嵌套NER,也能处理非重叠的NER问题。MGNER的想法非常自然直观,即是首先通过一个检测器检测出不同粒度的实体位置,然后通过分类器将这些实体分类到几种设定好的类别中。MGNER有五个部分:单词处理器,句子处理器,实体处理器,检测网络以及分类网络,每个模块都采用了广泛的神经网络设计。
总体来说,本文工作的贡献在于:
1 我们提出了新的神经网络模型,MGNER,用来做多粒度命名实体识别,这个模型旨在使用单个模型,有效的检测出嵌套和非重叠的实体。
2 MGNER高度模块化。每个模块都使用广泛的神经网络设计。更多的,MGNER能够轻松的扩展到许多其他相关的信息抽取任务,如分块和槽填充。
3 实验表明,MGNER能够实现在嵌套NER和非重叠NER上都比现有先进模型更加好的效果。
2 相关工作
现有的识别非重叠命名实体的方法通常是吧NER任务作为序列标注问题。不同的序列标注模型都实现了很好的效果,这些模型包括概率图模型如CRF,深度神经网络如RNN或者CNN。Hammerton是第一个使用LSTM做NER人物的。Collobert等人使用CNN-CRF结构,能够得到和统计模型相当的结果。大多数最近的工作都使用了LSTM-CRF框架。Huang使用手工提取的拼写特征。Ma and Hovy和Chiu和Nichols使用字符级CNN来展现乒协特征。Lample等人也使用了字符级LSTM来替代。更多的是,注意力机制也在NER应用了,作用是动态的决定能从单词级或字符级组件中使用多少信息。
外部资源也被用来更进一步提高NER性能。Peters等人在NER中增加了从双向语言模型预训练的语境embedding。Peters等人学习堆积在一个深度双向语言模型的内部隐含状态的线性组合,ELMo,来利用捕获了上下文依赖的高级状态和建模语义的更低一级状态。这些序列标注模型只能检测非重叠实体,而甭能检测嵌套实体。
对于嵌套实体识别,也有很多方法被提出来。Finkel和Manning提出了CRF级的选区解析器,能够将每个命名实体提作为解析树上的组件。Ju等人动态堆叠多个NER层,并基于内层实体提取外层实体。如果更短的实体被错误的识别,这类模型可能或发生错误堆积的问题。
另一种嵌套NER的方法是基于超图。Lu和Roth是第一次提出使用超图这个观点的,这种模型允许不同表示嵌套实体的节点相互连接。Muis和Lu使用多图表示,并提出了做嵌套实体检测的语言划分的概念。Lu and Roth和Muis and Lu以来手工特征来提取嵌套实体,并且面临结构模糊的问题。Wang和Lu提出了一个自然分割超图模型,使用神经网络获取不同的特征表示。 Katiyar and Cardie耶提出了基于超图的公式并以贪心算法使用LSTM学习结构。这些超图方法的一个问题是超图的虚假结构,因为他们枚举结点,类型和边界的组合来表示实体。换句话说,这些模型是专门设计来做嵌套实体的,而且不适合于非重叠的命名实体识别。
Xu等人提出了一个局部检测方法,依赖于Fixed-size Ordinally Forgetting Encoding (FOFE)方法来编码语句,和一个简单的前馈神经网络来拒绝或预测单个文本部分的实体标签。他们的模型是和我们提出的模型解决的同一个问题,但是不同的是我们把NER任务分成两个部分,检测实体位置,并且分实体类别。
3 提出的框架
本文提出做多粒度实体识别的MGNER框架的大致图如下:
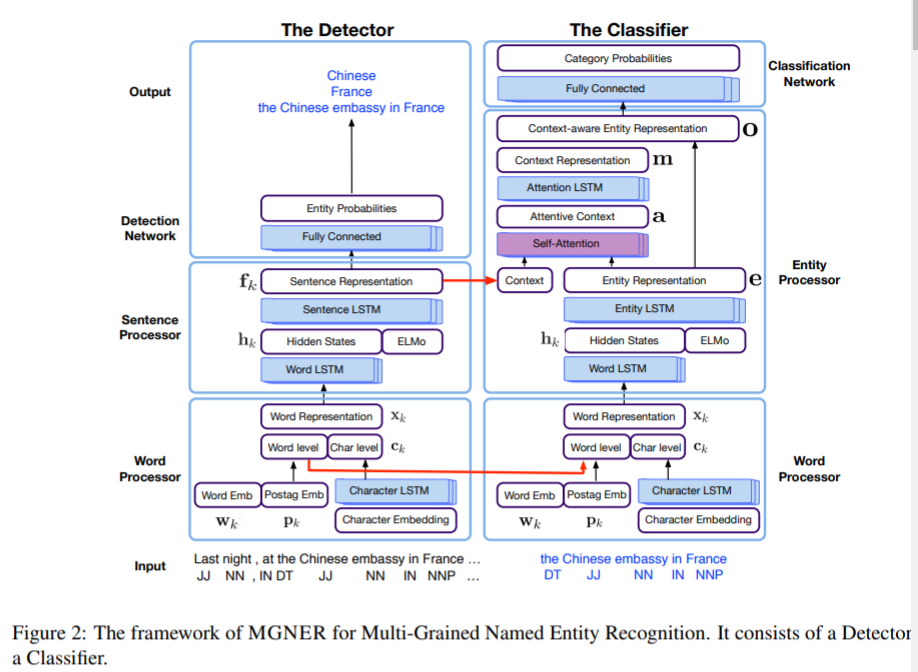
尤其,MGNER包括两个子网络:检测器和分类器。检测器检测所有可能的实体位置,而分类器旨在将检测出的实体分成预设的类别。检测器有三个模块:
1)提取单词级语义特征的单词处理器
2)学习上下文信息的句子处理器
3)决定一个单词分割是否是实体的检测网络
分类器包含:
1)和检测器中一样的单词处理器
2)获取实体特征的实体处理器
3)将实体分类成预设类别的分类网络
另外,实体处理器中使用了一个自注意力机制来帮助模型捕获和利用实体相关的上下文信息。
MGNER的每个模块都能被替换成其他的神经网络。比如,BERT能够用来作为单词处理器和一个capsule模型能够整合到分类网络中。
值得一提的是,为了提高MGNER的学习速度和效果,检测器和分类器会拥有一些共享的输入特征来训练。在检测器中训练的句子级语义特征会迁移到分类器中,供分类器使用上下文信息。我们在3.1部分呈现检测器的关键模块和属性,在3.2部分呈现分类器。
3.1 检测器
检测器的目的是检测每个语句中可能的实体位置。它将语句作为输入,并且输出一个备选实体集合。基本上,我们使用PEters等人提到的半监督神经网络来为这个过程建模。检测器的结构展现在图2的左部分。在检测器中,主要有三个模块:单词处理器,句子处理器,和检测模块。尤其是,为了生成语义上有意义的单词表示,我们加入了预训练单词embedding,POS标签信息,字符级单词信息。从单词处理器中获取的单词表示回合语言模型embedding ELMo拼接,并产生基于上下文的句子表示。每个可能地单词切分被放入检测网络 ,并被决定是否接受它作为实体。
3.2 分类器
分类器模块旨在将从检测器中获取到的备选实体分类成预设好的实体类别。对于嵌套NER任务,所有的可能实体都被保存并输入到分类器中。对于非重叠实体NER任务,我们使用非最大抑制(NMS)算法来处理重复,重叠的实体,并输出真实备选实体。NMS的想法简单但是有效:以最大概率挑选实体,删除冲突实体,并重复这一过程直到所有的实体都被处理完。最后,我们获得这些没有冲突的实体作为分类器的输入。
为了理解尸体的上下文信息,我们利用句子级上下文信息和自注意力机制来帮助模型聚焦于实体相关的上下文tokens。分类器的框架在图2的右部分。基本上,包括单词处理器,实体处理器和分类网络。