锁
我们知道mysql中支持很多个存储引擎,在不同的存储引擎下所能支持的锁是不同的,我们通过MyISAM和InnoDB来进行一下对比。
表级锁定(table-level)
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大打折扣。
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
行级锁定
行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
乐观锁和悲观锁
乐观锁,顾名思义,对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,"乐观"的认为加锁一定会成功的,在最后一步更新数据的时候在进行加锁,乐观锁的实现方式一般为每一条数据加一个版本号,具体流程是这样的:
1)、创建一张表时添加一个version字段,表示是版本号,如下:
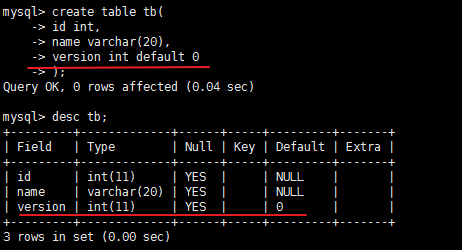
2)、修改数据的时候首先把这条数据的版本号查出来,update时判断这个版本号是否和数据库里的一致,如果一致则表明这条数据没有被其他用户修改,若不一致则表明这条数据在操作期间被其他客户修改过,此时需要在代码中抛异常或者回滚等。伪代码如下:
update tb set name='yyy' and version=version+1 where id=1 and version=version;
1. SELECT name AS old_name, version AS old_version FROM tb where ...;
2. 根据获取的数据进行业务操作,得到new_dname和new_version
3. UPDATE SET name = new_name, version = new_version WHERE version = old_version
if (updated row > 0) {
// 乐观锁获取成功,操作完成
} else {
// 乐观锁获取失败,回滚并重试
}
update其实在不在事物中都无所谓,在内部是这样的:update是单线程的,及如果一个线程对一条数据进行 update操作,会获得锁,其他线程如果要对同一条数据操作会阻塞,直到这个线程update成功后释放锁。
悲观锁,正如其名字一样,悲观锁对数据加锁持有一种悲观的态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
首先我们需要set autocommit=0,即不允许自动提交
用法:select * from tablename where id = 1 for update;
申请前提:没有线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞。
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
假设有一张商品表 shop,它包含 id,商品名称,库存量三个字段,表结构如下:
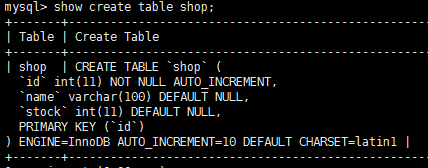
插入如下数据:
并发导致数据一致性的问题:
如果有A、B两个用户需要购买id=1的商品,AB都查询商品数量是1000,A购买后修改商品的数量为999,B购买后修改数量为999。
用乐观锁的解决方案:
每次获取商品时,不对该商品加锁。在更新数据的时候需要比较程序中的库存量与数据库中的库存量是否相等,如果相等则进行更新,反之程序重新获取库存量,再次进行比较,直到两个库存量的数值相等才进行数据更新。伪代码如下:
//不加锁
select id,name,stock where id=1;
//业务处理
begin;
update shop set stock=stock-1 where id=1 and stock=stock;
commit;
悲观锁方案:
每次获取商品时,对该商品加排他锁。也就是在用户A获取获取 id=1 的商品信息时对该行记录加锁,期间其他用户阻塞等待访问该记录。悲观锁适合写入频繁的场景。代码如下:
begin;
select id,name,stock as old_stock from shop where id=1 for update;
update shop set stock=stock-1 where id=1 and stock=old_stock;
commit;
我们可以看到,首先通过begin开启一个事物,在获得shop信息和修改数据的整个过程中都对数据加锁,保证了数据的一致性。