- 理论
- 进程只是一个资源单位,线程才是cpu上的执行单位
- 无需申请空间,创建开销小
- 共享和创建开销
- 多线程共享一个进程的地址空间
- 线程比进程更轻量级,线程比进程更容易创建可撤销
- I/O密集型,多线程,会加快程序执行的速度
- 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
- 线程操作
- 创建方式
- from threading import Thread
- t=Thread(target=func,args=('hello',)) ; t.start()
- 继承Thread类,实现run()方法
- 其他方法
- t.isAlive(): 返回线程是否活动的
- t.getName(): 返回线程名
- t.setName(): 设置线程名
- threading.currentThread(): 返回当前的线程变量
- threading.enumerate(): 返回一个包含正在运行的线程的list
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果
- 线程间关系
- 串行 join
- 主线程等待子线程结束
- 主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
- 守护线程
- t.daemon = True
- 无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
1.对主进程来说,运行完毕指的是主进程代码运行完毕
2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
- 串行 join
- 创建方式
- 线程同步
- Python的GIL
- 在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
- GIL本质就是一把互斥锁,保护不同的数据的安全,就应该加不同的锁。 将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全
- 在一个python的进程内,不仅有主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程
- 多个线程的target=work执行流程
- 多个线程先访问到解释器的代码,即拿到执行权限
- 所有数据都是共享的,代码作为一种数据也是被所有线程共享的
- 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行
- 将target的代码交给解释器的代码去执行
- 多个线程先访问到解释器的代码,即拿到执行权限
- 对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用
- IT(IO-Thread)多线程用于IO密集型,如socket,爬虫,web
- CP(Calculate-Process)多进程用于计算密集型,如金融分析
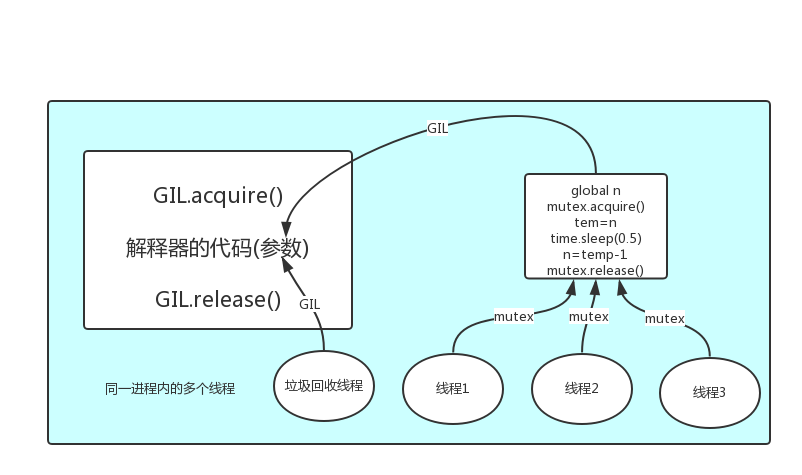
- 对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
- 递归锁 RLock
- 死锁: 两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象
- 在同一线程中多次请求同一资源,python提供了可重入锁RLock
- 内部维护着一个Lock和一个counter变量
- Counter记录了acquire的次数,从而使得资源可以被多次require
- 直到一个线程所有的acquire都被release,其他的线程才能获得资源
- 信号量 Semaphore
- 管理一个内置的计数器
- from threading import Thread,Semaphore
- 预置量 sm=Semaphore(5)
- 锁定 sm.acquire()
- 释放 sm.release()
- 会产生新的线程
- 事件 Event
- 通过判断某个线程的状态,本质是修改全局变量
- 由线程设置的信号标志,它允许线程等待某些事件的发生
- 初始情况下,Event对象中的信号标志被设置为假
- 有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真
- 一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程
- 如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
- 方法
- event.isSet():返回event的状态值
- event.wait(timeout=3):如果 event.isSet()==False将阻塞线程,超时时间timeout
- event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度
- event.clear():恢复event的状态值为False
- 定时器
- 指定n秒后执行某操作
- from threading import Timer
- t = Timer(3, hello)
- t.start()
- Python的GIL
- 线程池
- 线程queue
- 使用import queue,用法与进程Queue一样
- q=queue.Queue() 先进先出
- queue.LifoQueue(maxsize=0) 后进先出
- queue.PriorityQueue(maxsize=0) 存储数据时可设置优先级的队列
- q.put((20,'a'))
- 元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
- concurrent.futures
- 高度封装的异步调用接口
- 线程池 ThreadPoolExecutor
- max_workers :cpu_count*5
- 进程池 ProcessPoolExecutor
- max_workers :cpu_count
- 方法
- submit(fn, *args, **kwargs)
- map(func, *iterables, timeout=None, chunksize=1) 异步,须在shutdown之前
- 循环submit
- executor.map(task,range(1,12)) map取代了for+submit
- shutdown(wait=True)
- 相当于进程池的pool.close()+pool.join()操作
- wait=True,等待池内所有任务执行完毕回收完资源后才继续
- wait=False,立即返回,并不会等待池内的任务执行完毕
- result(timeout=None) 取得结果
- add_done_callback(fn) 回调函数
- p.submit(get_page,url).add_done_callback(parse_page)
- parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %os.getpid()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': executor=ThreadPoolExecutor(max_workers=3) # for i in range(11): # future=executor.submit(task,i) executor.map(task,range(1,12)) #map取代了for+submit
- 线程queue