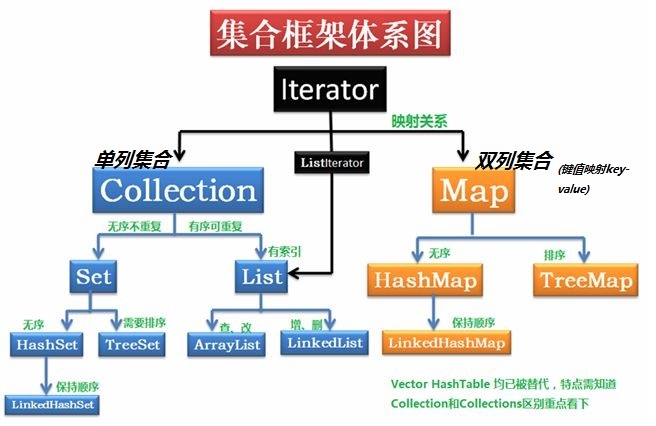
Collection接口:
1.单列集合类的根接口。
2.定义了可用于操作List、Set的方法——增删改查;
3.继承自Iterable<E>接口,该接口中提供了iterator() 方法:返回一个在一组 T 类型的元素上进行迭代的迭代器,使其具有使用foreach语句迭代的特权。
List接口:
1.元素可重复。
2.元素有序:元素的存入顺序和取出顺序一致。
3.所有元素是以一种线性方式进行存储,在程序中可以通过索引来访问集合中的指定元素。
4.所有的List中可以有null元素。
ArrayList集合:
1.ArrayList内部封装了一个长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组来存储这些元素(2倍数目增长),因此 可将ArrayList看作一个长度可变的数组。
2.ArrayList集合的底层是使用一个数组来保存元素,在增加或删除指定的元素时,会导致创建新的数组,效率较低,不适合做大量的增删操作。
3.ArrayList的数组结构允许通过索引的方式访问元素,因此使用ArrayList集合查找元素很便捷。
4.ArrayList是线程不安全的,当运行到多线程环境中时,需要自己管理线程同步的问题。
Vector集合:
1.Vector与ArrayList一样,也是通过数组实现的,当存入的元素超过数组长度时,会在内存中分配一个更大的数组来存储这些元素(1.5倍数目增长)。
2.Vector支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问 ArrayList慢。
LinkedList集合:
1.LinkedList内部维护了一个双向循环链表,链表中的每一个元素都使用引用的方式来记住前一个和后一个元素,从而将所有元素连接起来。
2.当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改引用的相关信息就可以实现了。这就是LinkedList 的优势。
Set接口:
1.不包含重复元素的集合,set中最多一个null元素。
2.因为Set集合无序,只能用Iterator实现遍历。
3.Set依赖于Map,Map的所有Key组合起来就是Set。
HashSet:
1.HashSet依赖于HashMap,它实际上是通过HashMap实现的。
2.元素无序且不保证集合的迭代顺序。
3.线程不安全,存取速度快,需要用以下语句来进行S同步转换:
Set s = Collections.synchronizedSet(new HashSet(...));
4.依赖元素的hashCode方法和equals方法保证元素唯一性。
TreeSet:
1.TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
2.可以对Set集合进行排序,通过compareTo或者compare方法进行排序。
3.线程不安全。
4.内部采用平衡的排序二叉树来存储元素
Map:
1.“键值”对映射的抽象接口。该映射不包括重复的键,一个键对应一个值。
2.Map集合的数据结构仅仅针对键有效,与值无关。
HashMap:
1.底层数据结构是哈希表。底层是用数组链表存储的,元素是Entry。
2.元素无序,没有任何明显的顺序来保存数据。
3.提供了最快的查找技术。
4.线程不安全。
5.允许null value和null key,最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。
Hashtable:
1.底层数据结构是哈希表。底层是用数组链表存储的,元素是Entry。
2.元素无序。
3.效率较慢。
4.线程安全。
5.key和value的值均不允许为null。
TreeMap:
1.底层数据结构是红黑树(是一种自平衡的二叉树)。
2.保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
3.TreeMap不允许key的值为null。
4.线程不安全。