lightgbm是继xgboost之后的又一大杀器,它训练速度快,且精度高,下面就其主要创新点做介绍,本文主要参考自>>>
一.单边梯度采样算法
GOSS(Gradient-based One-Side Sampling)是一种样本采样方法,它基于梯度的绝对值对样本进行采样,主要包含如下几个步骤:
(1)对梯度的绝对值进行降序排序,选择前(a*100\%)个样本;
(2)从剩下的小梯度数据中随机选择(b*100\%)个样本,为了不破坏原始数据的分布特性,对这(b*100\%)个样本权重扩大(frac{1-a}{b})倍(代价敏感学习)
(3)将这((a+b)*100\%)个样本用作为下一颗树的训练
算法流程如下:

二.互斥特征捆绑算法
EFB(Exclusive Feature Bundling)可以粗略的理解为one-hot的逆过程,我们可以将这个过程拆解为两步:
(1)第一步,需要寻找那些特征进行捆绑,理想情况下所选择的几个特征,每行只有一个非0值,但现实数据可能没有那么离线,lgb用了一种允许一定误差的图着色算法求解:

(2)第二步,便是合并这些特征,如果直接合并其实是有问题的,比如下面第一张图片,因为第一列特征的取值1和第二列特征的取值1其实具有不同含义,所以lgb的做法是对每一列加上一个bias,这个bias为前面所有特征列的max取值之和,如下面第二张图例所示:
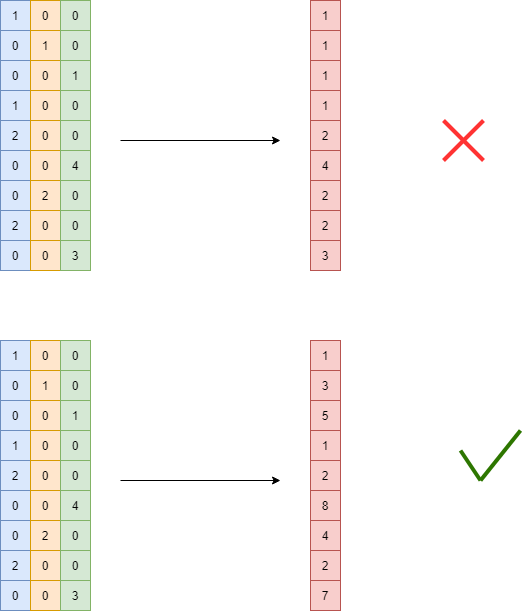
算法流程如下,但有一点需要注意是,计算特征的切分点是在各自的range内计算的,如上图,虽然合并后为一列特征,但需要分别在[1,2],[3,4],[5,8]这三个区间内分别计算一个切分点

三.类别特征优化
类别特征,特别是高基类别特征的处理一直很棘手,比如日期,id等特征,如果按照常规方法对其作one-hot展开,在训练决策树时会切分出很多不平衡的结点来(比如左节点样本数远大于右节点),这本质是一种one-vs-rest的切分方法,收益很低,决策树还容易过拟合,而lgb提出了使用many-vs-many的方法对类别特征进行划分,这样既能平衡左右节点的训练样本量,又能一定程度上避免过拟合,示例如下(图中决策判断条件如果为True则走左分支,否则走右边):
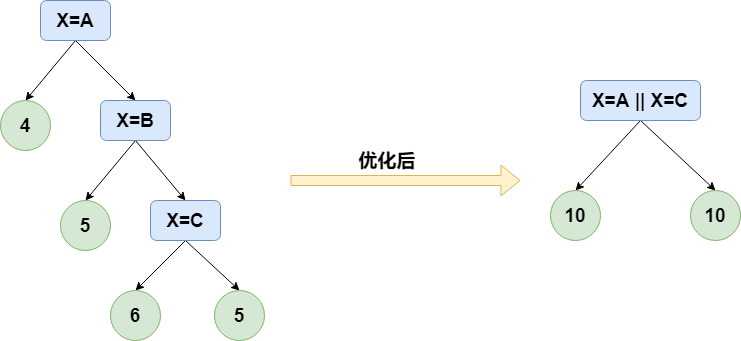
当然,如果暴力搜索时间复杂度会有些高,假如某类别特征有(k)种取值的可能,那么共有如下的(2^{k-1}-1)种搜索结果,时间复杂度为(O(2^k)):
lgb基于《On Grouping For Maximum Homogeneity》实现了时间复杂度为(O(klogk))的求法