attention和transformer
attention
- attention是什么?
- Attention出现的原因是什么?
基于循环神经网络(RNN)一类的seq2seq模型,在处理长文本时遇到了挑战,而对长文本中不同位置的信息进行attention有助于提升RNN的模型效果。
这个答案又衍生出下列问题:
3. seq2seq模型是什么?
seq2seq是一种常见的NLP模型结构,全称是:sequence to sequence,翻译为“序列到序列”。顾名思义:从一个文本序列得到一个新的文本序列。典型的任务有:机器翻译任务,文本摘要任务。
- seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。
- seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN
- 基于RNN的seq2seq模型如何处理文本/长文本序列?
- 假设序列输入是一个句子,这个句子可以由(n)个词表示:(sentence = {w_1, w_2,...,w_n})。
- RNN首先将句子中的每一个词映射成为一个向量得到一个向量序列:(X = {x_1, x_2,...,x_n}),每个单词映射得到的向量通常又叫做:word embedding。
- 解码器在每个时间步会得到 hidden state(隐藏层状态),而且需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。
- seq2seq模型处理长文本序列时遇到了什么问题?
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。
- 一方面单个向量很难包含所有文本序列的信息
- 另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
- 基于RNN的seq2seq模型如何结合attention来改善模型效果?
- attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
- attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
- 一个注意力模型与经典的seq2seq模型主要有2点不同:
- A. 首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态)
- B. 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。
transformer
1.transformer是什么?
一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构
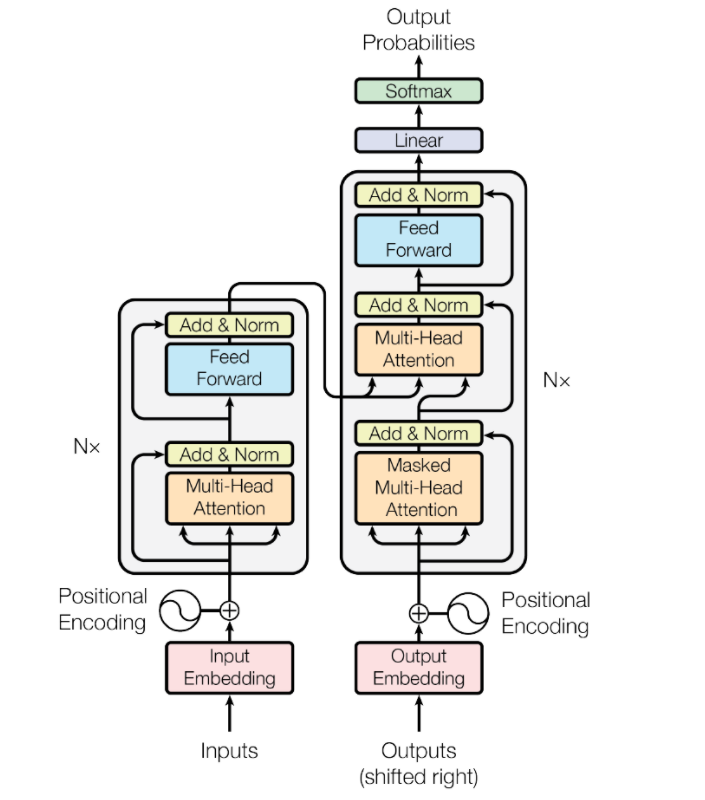
未完待续……