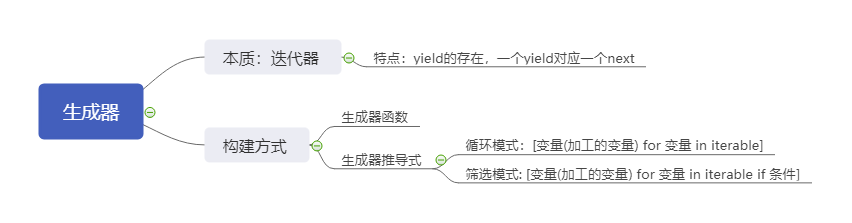
函数名的使用
之前刚接触函数的时候我们就已经了解到函数名的定义与普通变量几乎一致,实际上函数名就是一个变量,并同时具备变量的功能(可以赋值),但与普通变量不同的是,函数名后跟括号()后就能执行相关的函数,因此我们也将函数名视为特殊的变量。
函数的内存地址
我们尝试输出一个函数名,将会得到什么结果呢?
def func(): print("hello world ") print(func) #<function func at 0x0000026A56C7C2F0
从上述代码及其运行结果我们可看出函数名指向了这个函数的内存地址,换句话说:函数名()可以执行函数即是函数的内存地址()执行函数的又一表达形式。其意义相当于:
a=1 b=2 c=a+b print(c) #3
a+b并不是变量的相加减,而是这两个变量所指向的int对象的相加。
函数名可以赋值给其他变量
清除函数名代表的即为该函数的内存地址后,我们再来看一段代码:
def func(): print("凝宝爱火锅") print(func) # <function func at 0x0000016C42DFC2F0> f = func f() # 凝宝爱火锅 print(f) # <function func at 0x0000016C42DFC2F0>
通过赋值,变量f也指向了这个函数的内存地址,于是当使用f()时也可以执行这个函数。
函数名可以当做容器类的元素
既然函数名就是一个变量,那么它也可以是当做容器类类型的元素的:
def func1(): print("凝宝") def func2(): print("柳柳") def func3(): print("星仔") def func4(): print("静姐") def func5(): print("华仔") lis=[func1,func2,func3,func3,func4,func5] for i in lis: i()
运行结果如下图:

函数名可以当做函数的参数
既然变量可以作为参数存在,那么变量名也可以:
def func1(): print("func1...") def func2(f): print("func2...") f() func2(func1)

函数名可以作为函数的返回值
def func1(): print("func1") def func2(f): print("func2") return f ret=func2(func1) ret()

小结:函数名(别名:第一类对象)就是一个特殊的变量,除了具有变量的功能外,最主要的是后面加上括号后就能执行相应的函数。
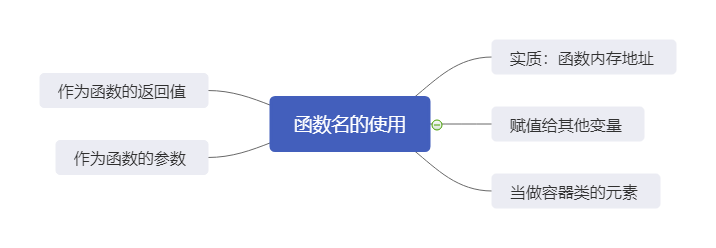
迭代器
在正式接触迭代器之前,我们首先来看看python中的for循环
for i in ['凝宝','柳柳','静姐','星仔','华仔']: print(i)
毫无意外,程序运行出了我们想要的结果:

我们尝试对一个数字来一次循环:
for i in 1234: print(i)
程序运行出现错误:
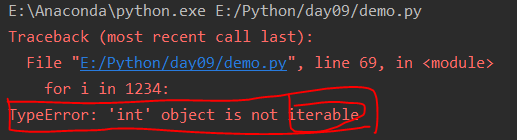
错误提示:int类型不是一个iterable的对象。
iteratable,指可迭代的、可重复的、迭代的。
由此,我们开始正式接触迭代:
迭代的概念
上述例子中提示之所以数字1234不能for循环,是因为它不可迭代,那么我们可以推测,如果“可迭代”,就应该可以for循环了。我们知道:字符串、列表、元祖、字典、集合都可以被for循环
说明它们都是可以被迭代的,怎么证明呢?
from collections.abc import Iterable l = [1, 2, 3, 4] t = (1, 2, 3, 4) d = {1: 2, 3: 4} s = {1, 2, 3, 4} print(isinstance(l, Iterable)) #True print(isinstance(t, Iterable)) #True print(isinstance(d, Iterable)) #True print(isinstance(s, Iterable)) #True
结合for循环取值的结果,通俗的说,迭代就是将某个数据集合内的数据“一个挨着一个的取出来”,这就叫做迭代。
可迭代对象
相对于迭代器而言,我们也许更加熟悉可迭代对象。从字面意思来说,我们先对其进行拆解:什么是对象?Python中一切皆对象,之前我们讲过的一个变量,一个列表,一个字符串,文件句柄,函数名等等都可称作一个对象,其实一个对象就是一个实例,就是一个实实在在的东西。那么什么叫迭代?其实我们在日常生活中经常遇到迭代这个词儿,更新迭代等等,迭代就是一个重复的过程,但是不能是单纯的重复(如果只是单纯的重复那么他与循环没有什么区别)每次重复都是基于上一次的结果而来。
到目前为止,我们接触的可迭代对象有str list tuple dic set range 文件句柄等,之所以int、bool不能称之为可迭代对象,是因为它们不符合标准或者规则。
在python中,但凡内部含有__iter__方法的对象,都是可迭代对象。
s1='凝宝' print(dir(s1)) #['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
可以看到,dir()返回了一个列表,这个列表中包含了该对象的以字符串的形式所有方法名。由此我们就可以判断python中的对象是不是可迭代对象了:
s1='凝宝' i=1 print('__iter__' in dir(i)) #False print('__iter__' in dir(s1)) #True
下面我们对可迭代对象做一个小结:
从字面意思来说:可迭代对象就是一个可以重复取值的实实在在的东西。
从专业角度来说:但凡内部含有__iter__方法的对象,都是可迭代对象。
可迭代对象可以通过判断该对象是否有’__iter__’方法来判断。
可迭代对象的优点:可以直观的查看里面的数据。
可迭代对象的缺点:
1. 占用内存。
2. 可迭代对象不能迭代取值(除去索引,key以外)。
那么这个缺点有人就提出质疑了,即使抛去索引,key以外,这些我可以通过for循环进行取值呀!对,他们都可以通过for循环进行取值,其实for循环在底层做了一个小小的转化,就是先将可迭代对象转化成迭代器,然后在进行取值的。
迭代器
定义
从字面意思来说迭代器,是一个可以迭代取值的工具,器:在这里当做工具比较合适。
从专业角度来说:迭代器是这样的对象:实现了无参数的__next__方法,返回序列中的下一个元素,如果没有元素了,那么抛出StopIteration异常.python中的迭代器还实现了__iter__方法,因此迭代器也可以迭代
简单的说:在python中,内部含有‘__iter__’方法并且含有‘__next__’方法的对象就是迭代器。
判断
有了定义我们就可以来判断哪些对象是不是迭代器或者可迭代对象了:
o1 = '柳柳' o2 = [1, 2, 3] o3 = (1, 2, 3) o4 = {'name': '凝宝','age': 18} o5 = {1, 2, 3} f = open('file',encoding='utf-8', mode='w') print('__iter__' in dir(o1)) # True print('__iter__' in dir(o2)) # True print('__iter__' in dir(o3)) # True print('__iter__' in dir(o4)) # True print('__iter__' in dir(o5)) # True print('__iter__' in dir(f)) # True print('__next__' in dir(o1)) # False print('__next__' in dir(o2)) # False print('__next__' in dir(o3)) # False print('__next__' in dir(o4)) # False print('__next__' in dir(o5)) # False print('__next__' in dir(f)) # True f.close()
通过以上代码可以验证,之前我们学过的这些对象,只有文件句柄是迭代器,剩下的那些数据类型都是可迭代对象。
转化
那么可迭代对象如何转化成迭代器呢?
l1=[1,2,3,4,5] obj=l1.__iter__() print(obj) #<list_iterator object at 0x0000021DF0786AC8>
迭代器取值
可迭代对象是不可以一直迭代取值的(除去用索引,切片以及Key),但是转化成迭代器就可以了,迭代器是利用__next__()进行取值:
l1 = [1, 2, 3,] obj = l1.__iter__() # 或者 iter(l1) ret = obj.__next__() print(ret) #1 ret = obj.__next__() print(ret) #2 ret = obj.__next__() print(ret) #3 ret = obj.__next__() # StopIteration print(ret) # 迭代器利用next取值:一个next取对应的一个值,如果迭代器里面的值取完了,还要next, # 那么就报StopIteration的错误。
小结:
从字面意思来说:迭代器就是可以迭代取值的工具。
从专业角度来说:在python中,内部含有'__Iter__'方法并且含有'__next__'方法的对象就是迭代器。
迭代器的优点:
节省内存:迭代器在内存中相当于只占一个数据的空间:因为每次取值都上一条数据会在内存释放,加载当前的此条数据。
惰性机制:next一次,取一个值,绝不过多取值。
有一个迭代器模式可以很好的解释上面这两条:迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式。
迭代器的缺点:
不能直观的查看里面的数据。
取值时不走回头路,只能一直向下取值。
可迭代对象与迭代器对比
可迭代对象:
是一个私有的方法比较多,操作灵活(比如列表,字典的增删改查,字符串的常用操作方法等),比较直观,但是占用内存,而且不能直接通过循环迭代取值的这么一个数据集。
应用:当你侧重于对于数据可以灵活处理,并且内存空间足够,将数据集设置为可迭代对象是明确的选择。
迭代器:
是一个非常节省内存,可以记录取值位置,可以直接通过循环+next方法取值,但是不直观,操作方法比较单一的数据集。
应用:当你的数据量过大,大到足以撑爆你的内存或者你以节省内存为首选因素时,将数据集设置为迭代器是一个不错的选择。

生成器
生成器初识
生成器的本质就是迭代器,在python社区中,大多数时候都把迭代器和生成器是做同一个概念。不是相同么?为什么还要创建生成器?生成器和迭代器也有不同,唯一的不同就是:迭代器都是Python给你提供的已经写好的工具或者通过数据转化得来的,(比如文件句柄,iter([1,2,3])。生成器是需要我们自己用python代码构建的工具。最大的区别也就如此了。
生成器的构建方式
在python中有三种方式来创建生成器:
1. 通过生成器函数
2. 通过生成器推导式
3. python内置函数或者模块提供(其实1,3两种本质上差不多,都是通过函数的形式生成,只不过1是自己写的生成器函数,3是python提供的生成器函数而已)
下面对这三种方式进行简单介绍:
生成器函数
我们先来定义一个简单的函数:
def func(): print(11) return 22 ret=func() #11 print(ret) #22
代码正常运行,现在我们将return换成yield,这样func就不是函数了,而是一个生成器函数。
同时,这样做会对代码的运行产生什么影响呢?
def func(): print(11) yield 22 ret=func() print(ret) #<generator object func at 0x000002C56D6D0A98>
运行结果产生差异,由于yield的存在,这个函数变成一个生成器函数,在执行时就不再是函数的执行了,而是获取这个生成器对象。那么生成器对象该如何取值呢?
之前我们说了,生成器的本质就是迭代器.迭代器如何取值,生成器就如何取值。所以我们可以直接执行next()来执行以下生成器:
def func(): print(11) yield 22 gener=func() ret=gener.__next__() print(ret) #11 22
同时生成器函数中也可以写多个yield
def func(): print("111") yield 222 print("333") yield 444 gener = func() ret = gener.__next__() print(ret) ret2 = gener.__next__() print(ret2) ret3 = gener.__next__() # 最后⼀个yield执⾏完毕. 再次__next__()程序报错 print(ret3)
当程序运行完最后一个yield,那么后面继续运行next()程序会报错,一个yield对应一个next,next超过yield数量,就会报错,与迭代器一样。
yield与return的区别:
return一般在函数中只设置一个,他的作用是终止函数,并且给函数的执行者返回值。
yield在生成器函数中可设置多个,他并不会终止函数,next会获取对应yield生成的元素。
生成器推导式
现有一个需求:用for循环向一个列表中添加1~10:
li=[] for i in range(10): li.append(i) print(li) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
现在我们用列表推导式实现一下:
ls=[i for i in range(10)] print(ls) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
可见,代码简便了很多
列表推导式分为两种模式:
1.循环模式:[变量(加工的变量) for 变量 in iterable]
2.筛选模式: [变量(加工的变量) for 变量 in iterable if 条件]
循环模式
# 将10以内的所有整数的平方写入列表 l1 = [i * i for i in range(1, 11)] print(l1) # 将50以内的所有偶数写入列表 l2 = [i for i in range(2, 51, 2)] print(l2)
筛选模式
#将列表中大于3的元素留下来 l1=[4,8,1,2,9,3] print([i for i in l1 if i>3]) #[4, 8, 9] #过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母 l = ['wusir', 'laonanhai', 'aa', 'b', 'taibai'] print([i.upper() for i in l if len(i) > 3]) #['WUSIR', 'LAONANHAI', 'TAIBAI'] #找到嵌套列表中名字含有两个‘e’的所有名字(有难度) names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] # 注意遍历顺序,这是实现的关键 print([name for lst in names for name in lst if name.count('e') >= 2]) #['Jefferson', 'Wesley', 'Steven', 'Jennifer']