前面讲到过如何获取新浪财经金融类新闻的方法,现在讲如何将这些数据存入到MySQL数据库。
在这里需要使用的是Wampserver64,
图标如下:

具体的安装过程就不说了,需要注意的是Apache和MySQL端口占用的问题,进行端口替换就可以了。
安装成功后的Wampserver为在托盘中的一个绿色的标,如果不是绿色的说明还没有完全启动。
进入到Wampserver里选择
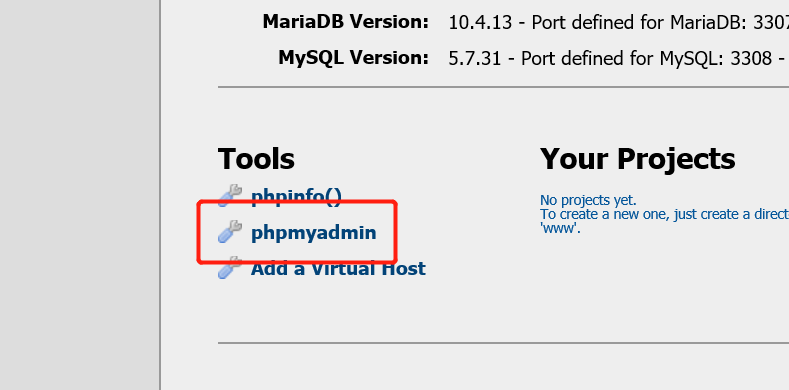
进入到MySQL

通过可视化界面来构建数据库和表,很方便(如果是一两个表的话,如果是大量的表还是直接用命令行来吧)
构建好本次实验使用的test1表,有5个字段。
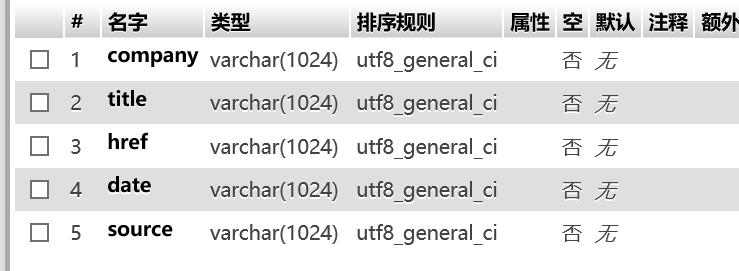
这里要注意“排序规则”要选成utf8_general_ci,这样才会正常的插入文本。
下面开始变成了,使用pymysql。
import requests
import re
import pymysql
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def find_information(company):
url = 'https://search.sina.com.cn/?q=' + company + '&range=all&c=news&sort=time&ie=utf-8'
res = requests.get(url, headers=headers, timeout=100).text
p_title = '<h2><a href=".*?" target="_blank">(.*?)</a>'
p_href = '<h2><a href="(.*?)" target="_blank">'
p_date = '<span class="fgray_time">(.*?)</span>'
p_source = '<span class="fgray_time">(.*?)</span>'
title = re.findall(p_title, res, re.S)
href = re.findall(p_href, res, re.S)
date = re.findall(p_date, res, re.S)
source = re.findall(p_source, res, re.S)
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('<.*?>', '', title[i])
date[i] = date[i].split(' ')[1]
source[i] = source[i].split(' ')[0]
if ('小时' in date[i]) or ('分钟' in date[i]):
date[i] = time.strftime("%Y-%m-%d")
else:
date[i] = date[i]
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
for i in range(len(title)):
db = pymysql.connect(host='localhost', port=3308, user='root', password='', database='pachong', charset='utf8')
cur = db.cursor()
sql = 'INSERT INTO test1(company,title,href,date,source) VALUES (%s,%s,%s,%s,%s)'
cur.execute(sql, (company, title[i], href[i], date[i], source[i]))
db.commit()
cur.close()
db.close()
companys = ['中国银行','工商银行', '建设银行', '农业银行', '交通银行', '邮储银行']
for i in companys:
try:
find_information(i)
print(i + '新浪财经新闻获取成功')
except:
print(i + '新浪财经新闻获取失败')
从MySQL中来看:
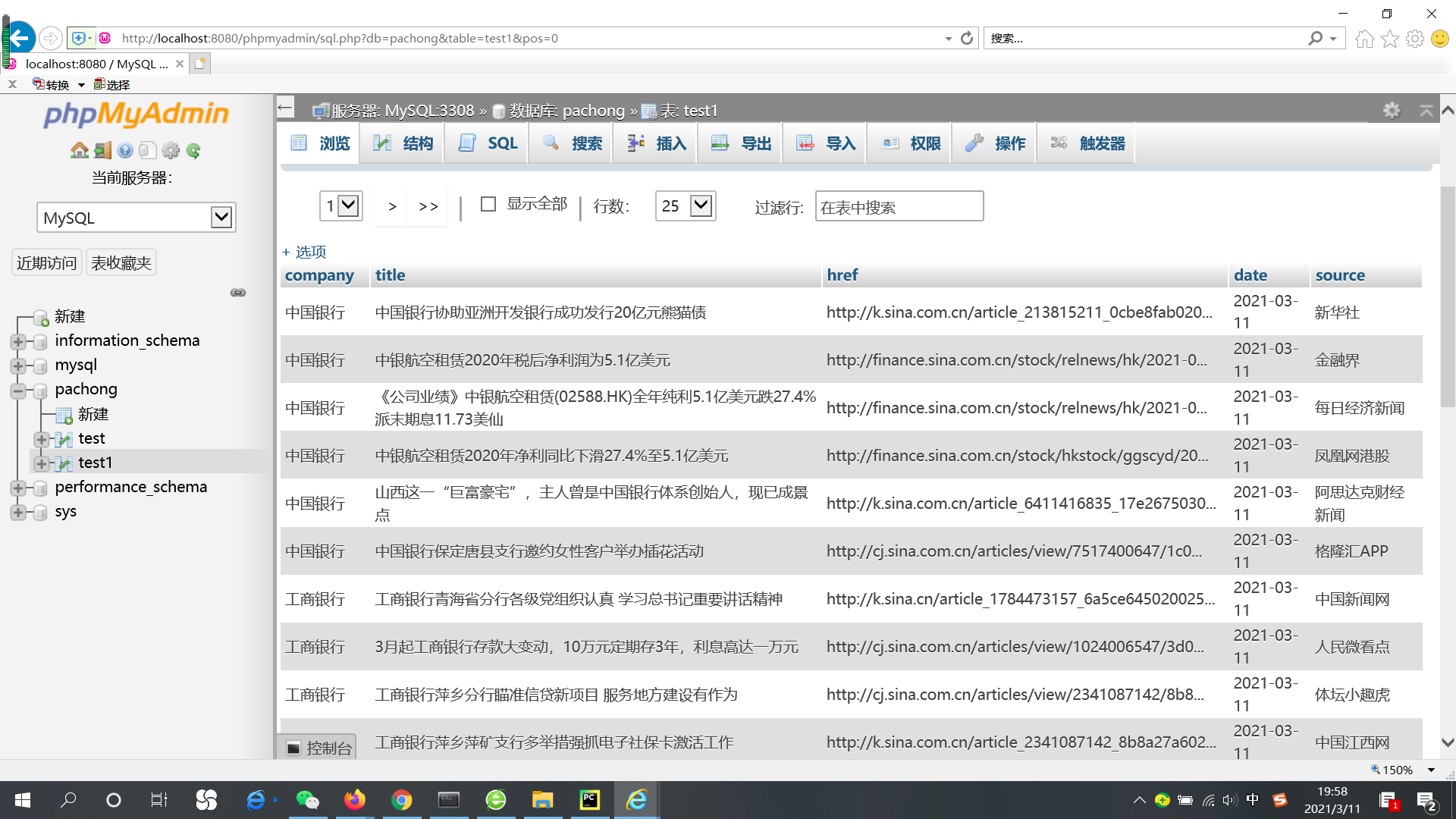
完成了。