中国银行作为权威的外汇数据提供方,获取中国银行提供的外汇数据可以有助于进行下一步的分析与预测。
在本次的项目中,使用Scrapy+Selenium+BeautifulSoup来获取中国银行的外汇数据并且保存到MySQL数据库中。
第一步:分析中国银行的网站
打开Chrome浏览器,搜索“中国银行”,进入到如下页面。
选择“中国银行外汇牌价”
点击进入,可以看到:
到这一步的时候并不是最终的获取数据的页面,需要进行选择“起始时间”、“结束时间”和“牌价选择”后进行跳转。
在这一页有一个坑,就是直接使用这页的源码是无法定位到“起始时间”、“结束时间”和“牌价选择”这几个选项的,网页的一些原理没有学过这块不太清楚。
因此需要随便选择一个跳转到可以获取数据的界面。
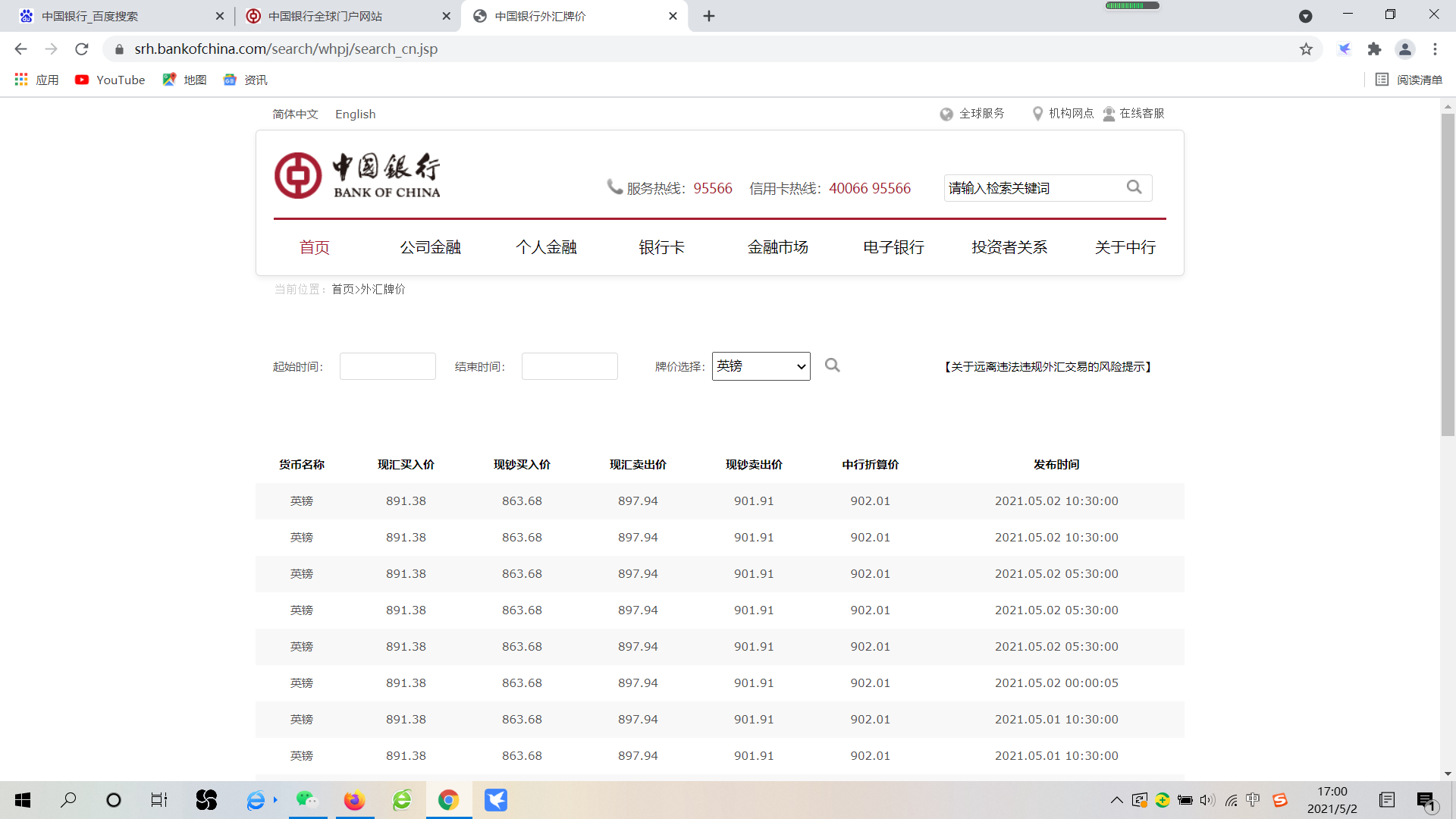
第二步:开始爬虫
对于Scrapy来说前面介绍过,下面直接展示项目。
在Scrapy工程里,许多文件是自动会创建的,这里的run.py是用来进行程序的运行。
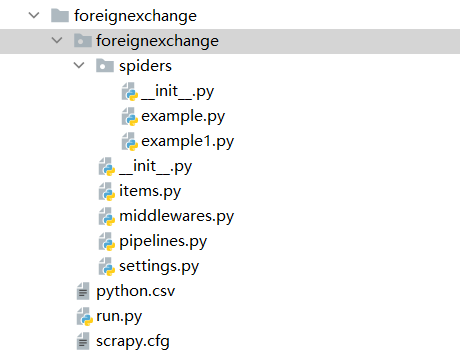
在本次项目中需要编辑的内容如下所示:

其中:
1)example.py是主要的程序部分
由于中国银行外汇数据的网页点击跳转下一页之后网址并没有变化,因此没有采用yield的方式来不停的切换网址,而是来获取在查询区间内有多少页数据,从而实现多页的爬取,上代码:
# -*- coding: utf-8 -*-
# 本次项目的目的是使用Scrapy框架来获取外汇市场数据
import scrapy
import re
import time
from selenium import webdriver
import selenium.webdriver.support.ui as ui
from selenium.webdriver.support.select import Select
from bs4 import BeautifulSoup
from ..items import ForeignexchangeItem
import pymysql
class ExampleSpider(scrapy.Spider):
name = 'example'
# 本次爬虫的场景较为简单不需要进行域名限制
# allowed_domains = ['example.com']
# 第一个url是Bank of China(中国银行)所公布的外汇牌价
start_urls = ['https://srh.bankofchina.com/search/whpj/search_cn.jsp']
def parse(self, response):
# 第一步:模拟登录对应的网站
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options = chrome_options)
boc_url = 'https://srh.bankofchina.com/search/whpj/search_cn.jsp'
browser.get(boc_url)
# 第二步:检查起始时间、结束时间和外汇类型的选择部分是否可以定位成功
# 检查起始时间
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[2]/div/input')
print('已定位到起始时间元素')
end = time.time()
print('定位到起始时间元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到起始时间元素!')
# 检查结束时间
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[4]/div/input')
print('已定位到结束时间元素')
end = time.time()
print('定位到结束时间元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到结束时间元素!')
# 检查外汇类型
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[6]')
print('已定位到外汇类型元素')
end = time.time()
print('定位到外汇类型元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到外汇类型元素!')
# 输入起始时间数据
print('请输入起始时间')
start_date = input()
# 输入结束时间数据
print('请输入结束时间!')
end_date = input()
# 输入外汇类型数据
print('请输入外汇类型数据!')
foreign_type = input()
# 输入检测函数
# 起始日期和结束日期的可选范围是20110101-至今,格式可以为YYYY,YYYYMM,YYYYMMDD,YYYY-MM,YYYY-MM-DD
# 外汇类型的选择范围是如下:
# 0 选择货币
# 1 英镑
# 2 港币
# 3 美元
# 4 瑞士法郎
# 5 德国马克
# 6 法国法郎
# 7 新加坡元
# 8 瑞典克朗
# 9 丹麦克朗
# 10 挪威克朗
# 11 日元
# 12 加拿大元
# 13 澳大利亚元
# 14 欧元
# 15 澳门元
# 16 菲律宾比索
# 17 泰国铢
# 18 新西兰元
# 19 韩元
# 20 卢布
# 21 林吉特
# 22 新台币
# 23 西班牙比塞塔
# 24 意大利里拉
# 25 荷兰盾
# 26 比利时法郎
# 27 芬兰马克
# 28 印度卢比
# 29 印尼卢比
# 30 巴西里亚尔
# 31 阿联酋迪拉姆
# 32 印度卢比
# 33 南非兰特
# 34 沙特里亚尔
# 35 土耳其里拉
def input_check(start_date, end_date, foreign_type):
# 对于起始日期进行检查
patter_date = re.compile(r'd{4}-*d{0,2}-*d{0,2}')
start_check = patter_date.findall(start_date)
if len(start_check) != 1:
print('起始日期输入格式错误!')
return
else:
start_data_auxiliary = start_check[0]
start_data_auxiliary = re.sub(r'-', '', start_data_auxiliary)
start_data_len = len(start_data_auxiliary)
# 年的情况
if start_data_len == 4:
if int(start_data_auxiliary) < 2011 or int(start_data_auxiliary) > int(
time.strftime('%Y-%m-%d').split('-')[0]):
print('起始日期输入数据错误!')
return
# 年月的情况
elif start_data_len == 6:
if int(start_data_auxiliary) < int(201101) or int(start_data_auxiliary) > int(
time.strftime('%Y-%m-%d').split('-')[0] + time.strftime('%Y-%m-%d').split('-')[1]):
print('起始日期输入数据错误!')
return
elif start_data_len == 8:
if int(start_data_auxiliary) < int(20110101) or int(start_data_auxiliary) > int(
re.sub(r'-', '', time.strftime('%Y-%m-%d'))):
print('起始日期输入数据错误!')
return
else:
print('起始日期输入数据错误!')
return
# 对于结束日期进行检查,同起始日期
patter_date = re.compile(r'd{4}-*d{0,2}-*d{0,2}')
end_check = patter_date.findall(end_date)
if len(end_check) != 1:
print('结束日期输入格式错误!')
return
else:
end_data_auxiliary = end_check[0]
end_data_auxiliary = re.sub(r'-', '', end_data_auxiliary)
end_data_len = len(end_data_auxiliary)
# 年的情况
if end_data_len == 4:
if int(end_data_auxiliary) < 2011 or int(end_data_auxiliary) > int(
time.strftime('%Y-%m-%d').split('-')[0]):
print('结束日期输入数据错误!')
return
# 年月的情况
elif end_data_len == 6:
if int(end_data_auxiliary) < int(201101) or int(end_data_auxiliary) > int(
time.strftime('%Y-%m-%d').split('-')[0] + time.strftime('%Y-%m-%d').split('-')[1]):
print('结束日期输入数据错误!')
return
elif end_data_len == 8:
if int(end_data_auxiliary) < int(20110101) or int(end_data_auxiliary) > int(
re.sub(r'-', '', time.strftime('%Y-%m-%d'))):
print('结束日期输入数据错误!')
return
else:
print('结束日期输入数据错误!')
return
# 对于外汇类型进行选择
# 依赖爬虫获取的结果
all_operation = browser.find_element_by_xpath('//*[@id="pjname"]')
all_operation = all_operation.text.split('
')
all_operation_auxiliary = [item.strip() for item in all_operation]
# 为了更好的操作可以在这里将所有的候选项做成一个字典或列表
all_operation_auxiliary_len = len(all_operation_auxiliary)
# all_operation_auxiliary存放了所有的可选项,因此在这里可以进行设置一个选择为数据外汇名称或者输入对应的序号
# 对于foreign_type进行类型判断
if foreign_type.isnumeric():
if int(foreign_type) not in range(1, all_operation_auxiliary_len - 1):
print('外汇类型指标输入错误!')
return
else:
if foreign_type.strip() not in all_operation_auxiliary:
print('外汇类型名称输入错误!')
return
print('输入数据符合要求!')
return start_date, end_date, foreign_type
# 检查输入数据是否合规
input_parameters = input_check(start_date, end_date, foreign_type)
# 在网页中设置起始时间
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[2]/div/input').clear()
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[2]/div/input').send_keys(
input_parameters[0])
# 在网页中设置结束时间
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[4]/div/input').clear()
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[4]/div/input').send_keys(
input_parameters[1])
# 在网页中设置外汇类型
# 判断输入为指标还是文本
if input_parameters[2].isnumeric():
# 指标形数据
S = Select(browser.find_element_by_name('pjname')).select_by_index(input_parameters[2])
else:
# 文本型数据
S = Select(browser.find_element_by_name('pjname')).select_by_visible_text(input_parameters[2])
# 参数选择完毕之后需要进行查询
# 检查查询按钮
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[7]')
print('已定位到查询按钮元素')
end = time.time()
print('定位到查询按钮元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到查询按钮元素!')
# 进行查询
browser.find_element_by_xpath('//*[@id="historysearchform"]/div/table/tbody/tr/td[7]').click()
# 查看在规定的时间范围内共找到了多少页的数据
# 检查查询页数部分
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="list_navigator"]/ol/li[1]')
print('已定位到查询页数部分元素')
end = time.time()
print('定位到查询页数部分元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到查询页数部分元素!')
page_num = re.compile(r'd+')
page_num = page_num.findall(browser.find_element_by_xpath('//*[@id="list_navigator"]/ol/li[1]').text)
print('共有 {} 页数据'.format(page_num[0]))
# 到这里已经得到了数据的第一页
# 这里需要查看这一页的网页源码来确定字段名和对应的数据
# 首先获取每个字段的名称
# ['货币名称', '现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '中行折算价', '发布时间']
currency_name = []
spot_purchase_price = []
cash_purchase_price = []
spot_selling_price = []
cash_selling_price = []
boc_discounted_price = []
release_time = []
# 定义一个item
item = ForeignexchangeItem()
# 这里需要使用一个循环来获得每页的数据
# 例如有25页,需要点击下一页24次
anchor = int(page_num[0])
while anchor > 0:
# 获取当页的数据
page_html = browser.page_source
# 使用BeautifulSoup来规范网页
soup = BeautifulSoup(page_html, 'html.parser')
div = soup.find('div', attrs={'class': 'BOC_main publish'})
table = div.find('table')
tr = table.find_all('tr')
# 这里需要用来查看当前页中有多少行数据
## 对于某一页有多少行而言,判断一页中有多少个货币名称即可,例如‘美元’和‘英镑’等
find_num_in_one_page = str(tr).split('
')
target_auxiliary = find_num_in_one_page[9]
num_in_one_page = find_num_in_one_page.count(target_auxiliary)
# 遍历这些数据行
for index_2 in range(1,num_in_one_page + 1):
td = tr[index_2].find_all('td')
patter_auxiliary = '<td>(.*?)</td>'
result = re.findall(patter_auxiliary, str(td))
# print(result)
currency_name.append(result[0])
spot_purchase_price.append(result[1])
cash_purchase_price.append(result[2])
spot_selling_price.append(result[3])
cash_selling_price.append(result[4])
boc_discounted_price.append(result[5])
release_time.append(result[6])
# item赋值
item['currency_name'] = result[0]
item['spot_purchase_price'] = result[1]
item['cash_purchase_price'] = result[2]
item['spot_selling_price'] = result[3]
item['cash_selling_price'] = result[4]
item['boc_discounted_price'] = result[5]
item['release_time'] = result[6]
yield item
# print(item)
# print(release_time)
anchor -= 1
# 检查跳转下一页部分
while True:
start = time.time()
try:
browser.find_element_by_xpath('//*[@id="list_navigator"]/ol/li[1]')
print('已定位到跳转下一页部分元素')
end = time.time()
print('定位到跳转下一页部分元素花费的时间 {} 秒'.format(end - start))
break
except:
print('还未定位到跳转下一页部分元素!')
browser.find_element_by_xpath('//*[@id="list_navigator"]/ol/li[10]/a').click()
# print(release_time[-1])
# print(item)
# def parse(self, response):
# # print(response.url)
# # print(response.status)
# # print(response.body.decode('utf-8'))
# # title = response.xpath('//ol[@class="grid_view"]//div[@class="hd"]/a/span[1]/text()').extract()
# # title = response.css('.hd > a > span:nth_child(1)::text').extract()
# abstract = response.xpath('//*[@class="ing"]/text()').extract()
# detail_pages = response.xpath('//div[@class="hd"]/a/@href').extract()
# for detail_page in detail_pages:
# # abstract_detail = abstract[ind]
# # yield scrapy.Request(url=detail_page,callback=self.parse_detail,meta={'abstract_detail':abstract_detail})
# yield scrapy.Request(url=detail_page,callback=self.parse_detail)
# next_page = response.xpath('//span[@class="next"]/a/@href').extract_first()
# base_url = 'https://movie.douban.com/top250'
# if next_page:
# yield scrapy.Request(url=base_url+next_page,callback=self.parse)
# def parse_detail(self,response):
# score = response.xpath('//*[@class="ll rating_num"]/text()').extract_first()
# # abstract_detail = response.meta['abstract_detail']
# # print(abstract_detail,score)
# print(score)
2)items.py用来传输数据,这里是需要进行数据库保存的数据的几个重要的字段。 ['货币名称', '现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '中行折算价', '发布时间']
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ForeignexchangeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency_name = scrapy.Field()
spot_purchase_price = scrapy.Field()
cash_purchase_price = scrapy.Field()
spot_selling_price = scrapy.Field()
cash_selling_price = scrapy.Field()
boc_discounted_price = scrapy.Field()
release_time = scrapy.Field()
3)pipelines.py用来和MySQL数据库进行连接和数据的插入与保存操作。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from typing import Any, Union
import pymysql
class ForeignexchangePipeline(object):
def open_spider(self,spider):
self.conn = pymysql.connect(
host='localhost',
port=3309,
user='root',
password='',
database='boc_foreign',
charset='utf8')
self.cursor = self.conn.cursor()
print('MySQL数据库连接成功!')
def process_item(self, item, spider):
sql = "INSERT INTO indian_rupee(`currency_name`,`spot_purchase_price`,`cash_purchase_price`,`spot_selling_price`,`cash_selling_price`,`boc_discounted_price`,`release_time`) VALUES ('%s','%s','%s','%s','%s','%s','%s')"
# print('SQL语句创建成功!')
self.cursor.execute(
sql % (
item['currency_name'],
item['spot_purchase_price'],
item['cash_purchase_price'],
item['spot_selling_price'],
item['cash_selling_price'],
item['boc_discounted_price'],
item['release_time'],
)
)
self.conn.commit()
# print('MySQL数据库数据插入成功!')
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
4)settings.py用来进行一些基础性的配置,相关的具体内容在程序的注释中有体现。
# -*- coding: utf-8 -*-
# Scrapy settings for foreignexchange project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'foreignexchange'
SPIDER_MODULES = ['foreignexchange.spiders']
NEWSPIDER_MODULE = 'foreignexchange.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 反爬虫,设置USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'
# Obey robots.txt rules
# 修改为Fasle
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'foreignexchange.middlewares.ForeignexchangeSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'foreignexchange.middlewares.ForeignexchangeDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'foreignexchange.pipelines.ForeignexchangePipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# FEED_FORMAT = 'CSV'
# FEED_URI = 'python.csv'
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
第三步:程序运行

按照程序的要求局限性输入合适的参数,就可以运行程序啦,在这之前需要和MySQL数据库进行连接,不然会报错。
第四步:在MySQL数据库中查看结果
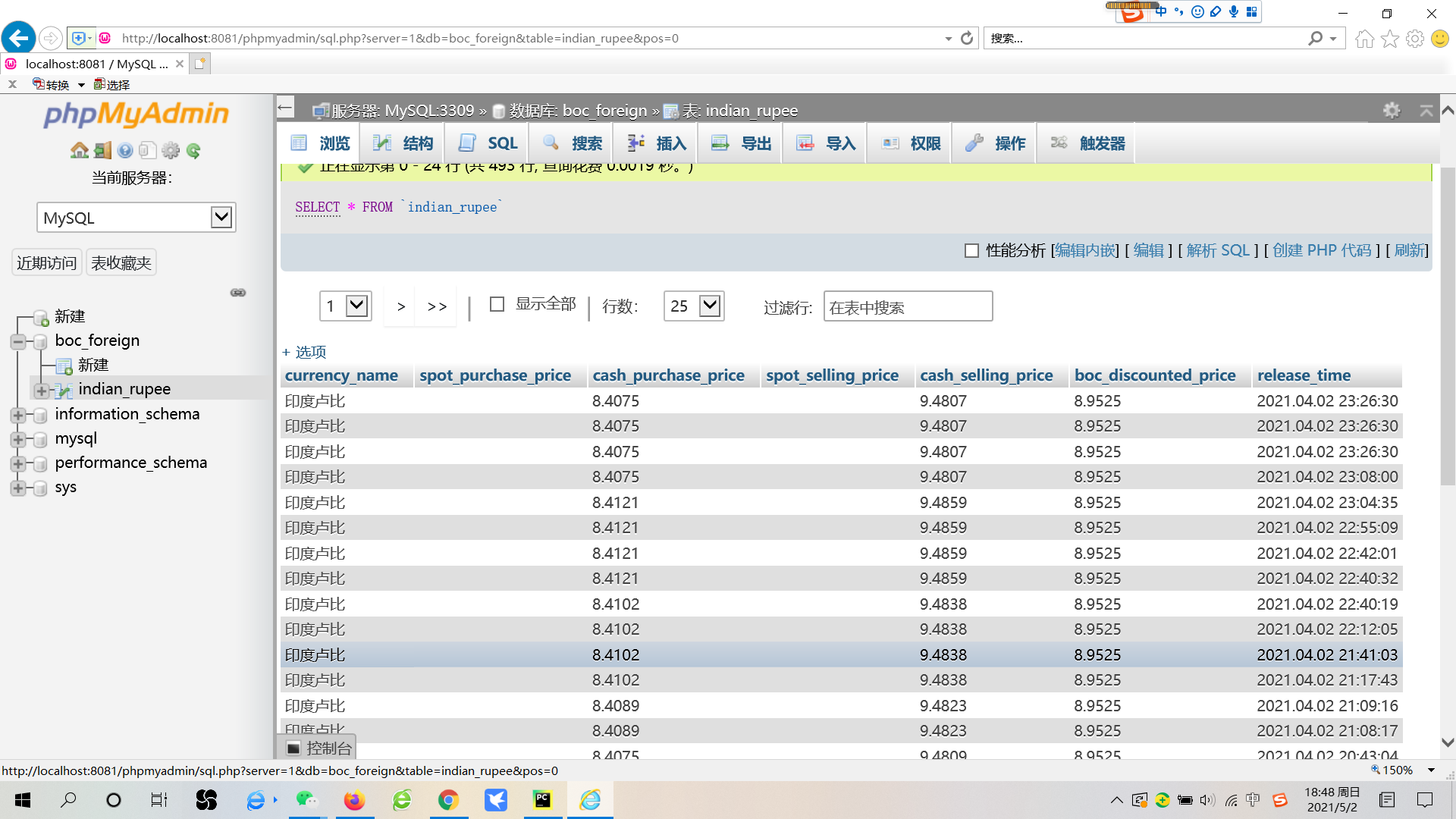
这样就可以看到相应的数据啦,有两列数据是缺失的,官方没有提供。