python由于它动态解释性语言的特性,跑起代码来相比java、c++要慢很多,尤其在做科学计算的时候,十亿百亿级别的运算,让python的这种劣势更加凸显。
办法永远比困难多,numba就是解决python慢的一大利器,可以让python的运行速度提升上百倍!

什么是numba?
numba是一款可以将python函数编译为机器代码的JIT编译器,经过numba编译的python代码(仅限数组运算),其运行速度可以接近C或FORTRAN语言。
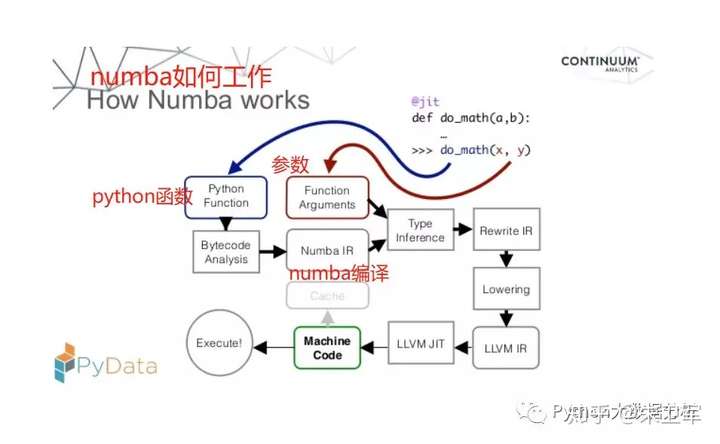
python之所以慢,是因为它是靠CPython编译的,numba的作用是给python换一种编译器。
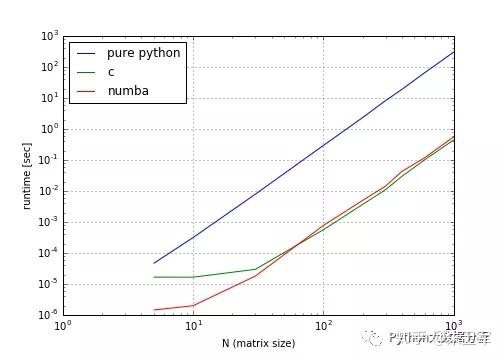
python、c、numba三种编译器速度对比
使用numba非常简单,只需要将numba装饰器应用到python函数中,无需改动原本的python代码,numba会自动完成剩余的工作。
import numpy as np
import numba
from numba import jit
@jit(nopython=True) # jit,numba装饰器中的一种
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i])
return a + trace
以上代码是一个python函数,用以计算numpy数组各个数值的双曲正切值,我们使用了numba装饰器,它将这个python函数编译为等效的机器代码,可以大大减少运行时间。
numba适合科学计算
numpy是为面向numpy数组的计算任务而设计的。
在面向数组的计算任务中,数据并行性对于像GPU这样的加速器是很自然的。Numba了解NumPy数组类型,并使用它们生成高效的编译代码,用于在GPU或多核CPU上执行。特殊装饰器还可以创建函数,像numpy函数那样在numpy数组上广播。
什么情况下使用numba呢?
- 使用numpy数组做大量科学计算时
- 使用for循环时
学习使用numba
第一步:导入numpy、numba及其编译器
import numpy as np import numba from numba import jit
第二步:传入numba装饰器jit,编写函数
# 传入jit,numba装饰器中的一种
@jit(nopython=True)
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播
nopython = True选项要求完全编译该函数(以便完全删除Python解释器调用),否则会引发异常。这些异常通常表示函数中需要修改的位置,以实现优于Python的性能。强烈建议您始终使用nopython = True。
# 因为函数要求传入的参数是nunpy数组 x = np.arange(100).reshape(10, 10) # 执行函数 go_fast(x)
第四步:经numba加速的函数执行时间
% timeit go_fast(x)
输出:3.63 µs ± 156 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
第五步:不经numba加速的函数执行时间
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播
x = np.arange(100).reshape(10, 10)
%timeit go_fast(x)
输出:136 µs ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
结论:
在numba加速下,代码执行时间为3.63微秒/循环。不经过numba加速,代码执行时间为136微秒/循环,两者相比,前者快了40倍。
numba让python飞起来
前面已经对比了numba使用前后,python代码速度提升了40倍,但这还不是最快的。
这次,我们不使用numpy数组,仅用for循环,看看nunba对for循环到底有多钟爱!
# 不使用numba的情况
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:408 µs ± 9.73 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# 使用numba的情况
@jit(nopython=True)
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:1.57 µs ± 53.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
使用numba前后分别是408微秒/循环、1.57微秒/循环,速度整整提升了200多倍!
结语
numba对python代码运行速度有巨大的提升,这极大的促进了大数据时代的python数据分析能力,对数据科学工作者来说,这真是一个lucky tool !
当然numba不会对numpy和for循环以外的python代码有很大帮助,你不要指望numba可以帮你加快从数据库取数,这点它真的做不到哈。
如果大家想要学习更多的python数据分析知识,请关注我的公众号:pydatas
回复:数据分析,可领取《利用python进行数据分析 第二版》电子书
