一,JDBC
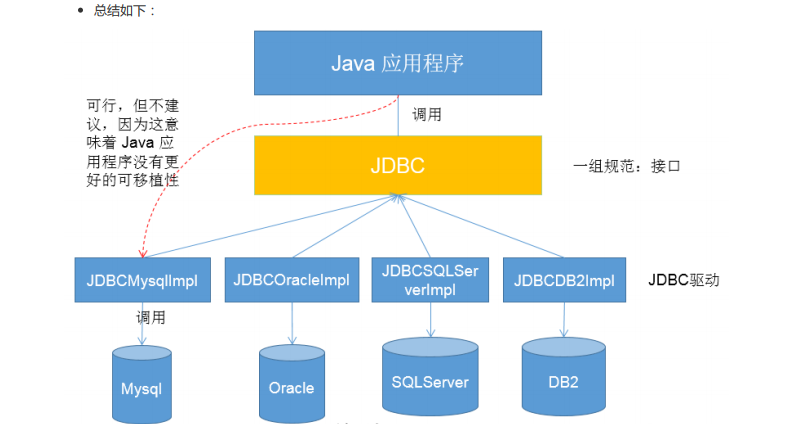

二,连接数据库代码:


@Test public void testConnection1() { try { //1.提供java.sql.Driver接口实现类的对象 Driver driver = null; driver = new com.mysql.jdbc.Driver(); //2.提供url,指明具体操作的数据 String url = "jdbc:mysql://localhost:3306/test"; //3.提供Properties的对象,指明用户名和密码 Properties info = new Properties(); info.setProperty("user", "root"); info.setProperty("password", "abc123"); //4.调用driver的connect(),获取连接 Connection conn = driver.connect(url, info); System.out.println(conn); } catch (SQLException e) { e.printStackTrace(); } }
过于原始,并不推荐,一共有五种方式,具体可以去尚硅谷jdbc课程资料里查看,这里直接到最终版。
@Test public void testConnection5() throws Exception { //1.加载配置文件 InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties"); Properties pros = new Properties(); pros.load(is); //2.读取配置信息 String user = pros.getProperty("user"); String password = pros.getProperty("password"); String url = pros.getProperty("url"); String driverClass = pros.getProperty("driverClass"); //3.加载驱动 Class.forName(driverClass); //4.获取连接 Connection conn = DriverManager.getConnection(url,user,password); System.out.println(conn); }
其中,配置文件声明在工程的src目录下:【jdbc.properties】
user=root password=abc123 url=jdbc:mysql://localhost:3306/test driverClass=com.mysql.jdbc.Driver
使用配置文件的好处:
①实现了代码和数据的分离,如果需要修改配置信息,直接在配置文件中修改,不需要深入代码
三,
//通用的增、删、改操作(体现一:增、删、改 ; 体现二:针对于不同的表) public void update(String sql,Object ... args){ Connection conn = null; PreparedStatement ps = null; try { //1.获取数据库的连接 conn = JDBCUtils.getConnection(); //2.获取PreparedStatement的实例 (或:预编译sql语句) ps = conn.prepareStatement(sql); //3.填充占位符 for(int i = 0;i < args.length;i++){ ps.setObject(i + 1, args[i]); } //4.执行sql语句 ps.execute(); } catch (Exception e) { e.printStackTrace(); }finally{ //5.关闭资源 JDBCUtils.closeResource(conn, ps); } }
// 通用的针对于不同表的查询:返回一个对象 (version 1.0) public <T> T getInstance(Class<T> clazz, String sql, Object... args) { Connection conn = null; PreparedStatement ps = null; ResultSet rs = null; try { // 1.获取数据库连接 conn = JDBCUtils.getConnection(); // 2.预编译sql语句,得到PreparedStatement对象 ps = conn.prepareStatement(sql); // 3.填充占位符 for (int i = 0; i < args.length; i++) { ps.setObject(i + 1, args[i]); } // 4.执行executeQuery(),得到结果集:ResultSet rs = ps.executeQuery(); // 5.得到结果集的元数据:ResultSetMetaData ResultSetMetaData rsmd = rs.getMetaData(); // 6.1通过ResultSetMetaData得到columnCount,columnLabel;通过ResultSet得到列值 int columnCount = rsmd.getColumnCount(); if (rs.next()) { T t = clazz.newInstance(); for (int i = 0; i < columnCount; i++) {// 遍历每一个列 // 获取列值 Object columnVal = rs.getObject(i + 1); // 获取列的别名:列的别名,使用类的属性名充当 String columnLabel = rsmd.getColumnLabel(i + 1); // 6.2使用反射,给对象的相应属性赋值 Field field = clazz.getDeclaredField(columnLabel); field.setAccessible(true); field.set(t, columnVal); } return t; } } catch (Exception e) { e.printStackTrace(); } finally { // 7.关闭资源 JDBCUtils.closeResource(conn, ps, rs); } return null; }
public void testJDBCTransaction() { Connection conn = null; try { // 1.获取数据库连接 conn = JDBCUtils.getConnection(); // 2.开启事务 conn.setAutoCommit(false); // 3.进行数据库操作 String sql1 = "update user_table set balance = balance - 100 where user = ?"; update(conn, sql1, "AA"); // 模拟网络异常 //System.out.println(10 / 0); String sql2 = "update user_table set balance = balance + 100 where user = ?"; update(conn, sql2, "BB"); // 4.若没有异常,则提交事务 conn.commit(); } catch (Exception e) { e.printStackTrace(); // 5.若有异常,则回滚事务 try { conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } } finally { try { //6.恢复每次DML操作的自动提交功能 conn.setAutoCommit(true); } catch (SQLException e) { e.printStackTrace(); } //7.关闭连接 JDBCUtils.closeResource(conn, null, null); } }
其中,对数据库操作的方法为:
//使用事务以后的通用的增删改操作(version 2.0) public void update(Connection conn ,String sql, Object... args) { PreparedStatement ps = null; try { // 1.获取PreparedStatement的实例 (或:预编译sql语句) ps = conn.prepareStatement(sql); // 2.填充占位符 for (int i = 0; i < args.length; i++) { ps.setObject(i + 1, args[i]); } // 3.执行sql语句 ps.execute(); } catch (Exception e) { e.printStackTrace(); } finally { // 4.关闭资源 JDBCUtils.closeResource(null, ps); } }


package com.atguigu.bookstore.dao; import java.lang.reflect.ParameterizedType; import java.lang.reflect.Type; import java.sql.Connection; import java.sql.SQLException; import java.util.List; import org.apache.commons.dbutils.QueryRunner; import org.apache.commons.dbutils.handlers.BeanHandler; import org.apache.commons.dbutils.handlers.BeanListHandler; import org.apache.commons.dbutils.handlers.ScalarHandler; /** * 定义一个用来被继承的对数据库进行基本操作的Dao * * @author HanYanBing * * @param <T> */ public abstract class BaseDao<T> { private QueryRunner queryRunner = new QueryRunner(); // 定义一个变量来接收泛型的类型 private Class<T> type; // 获取T的Class对象,获取泛型的类型,泛型是在被子类继承时才确定 public BaseDao() { // 获取子类的类型 Class clazz = this.getClass(); // 获取父类的类型 // getGenericSuperclass()用来获取当前类的父类的类型 // ParameterizedType表示的是带泛型的类型 ParameterizedType parameterizedType = (ParameterizedType) clazz.getGenericSuperclass(); // 获取具体的泛型类型 getActualTypeArguments获取具体的泛型的类型 // 这个方法会返回一个Type的数组 Type[] types = parameterizedType.getActualTypeArguments(); // 获取具体的泛型的类型· this.type = (Class<T>) types[0]; } /** * 通用的增删改操作 * * @param sql * @param params * @return */ public int update(Connection conn,String sql, Object... params) { int count = 0; try { count = queryRunner.update(conn, sql, params); } catch (SQLException e) { e.printStackTrace(); } return count; } /** * 获取一个对象 * * @param sql * @param params * @return */ public T getBean(Connection conn,String sql, Object... params) { T t = null; try { t = queryRunner.query(conn, sql, new BeanHandler<T>(type), params); } catch (SQLException e) { e.printStackTrace(); } return t; } /** * 获取所有对象 * * @param sql * @param params * @return */ public List<T> getBeanList(Connection conn,String sql, Object... params) { List<T> list = null; try { list = queryRunner.query(conn, sql, new BeanListHandler<T>(type), params); } catch (SQLException e) { e.printStackTrace(); } return list; } /** * 获取一个但一值得方法,专门用来执行像 select count(*)...这样的sql语句 * * @param sql * @param params * @return */ public Object getValue(Connection conn,String sql, Object... params) { Object count = null; try { // 调用queryRunner的query方法获取一个单一的值 count = queryRunner.query(conn, sql, new ScalarHandler<>(), params); } catch (SQLException e) { e.printStackTrace(); } return count; } }
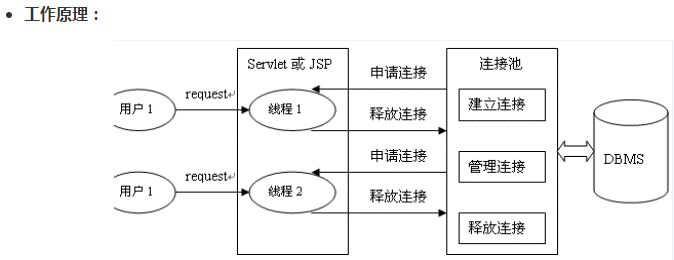
- JDBC 的数据库连接池使用 javax.sql.DataSource 来表示,DataSource 只是一个接口,该接口通常由服务器(Weblogic, WebSphere, Tomcat)提供实现,也有一些开源组织提供实现:
-
-
DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度。
-
特别注意:
-
数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。
-
-
package com.atguigu.druid; import java.sql.Connection; import java.util.Properties; import javax.sql.DataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; public class TestDruid { public static void main(String[] args) throws Exception { Properties pro = new Properties(); pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties")); DataSource ds = DruidDataSourceFactory.createDataSource(pro); Connection conn = ds.getConnection(); System.out.println(conn); } }
其中,src下的配置文件为:【druid.properties】
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true username=root password=123456 driverClassName=com.mysql.jdbc.Driver initialSize=10 //初始连接数
maxActive=20 //最大了解数 maxWait=1000 //最大等待时间,单位毫秒 filters=wall //属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
//资料里有更多
9.1 Apache-DBUtils简介
-
commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化jdbc编码的工作量,同时也不会影响程序的性能。
-
API介绍:
-
org.apache.commons.dbutils.QueryRunner
-
org.apache.commons.dbutils.ResultSetHandler
-
-

9.2 主要API的使用
-
DbUtils :提供如关闭连接、装载JDBC驱动程序等常规工作的工具类,里面的所有方法都是静态的。主要方法如下:
-
public static void close(…) throws java.sql.SQLException: DbUtils类提供了三个重载的关闭方法。这些方法检查所提供的参数是不是NULL,如果不是的话,它们就关闭Connection、Statement和ResultSet。
-
public static void closeQuietly(…): 这一类方法不仅能在Connection、Statement和ResultSet为NULL情况下避免关闭,还能隐藏一些在程序中抛出的SQLEeception。
-
public static void commitAndClose(Connection conn)throws SQLException: 用来提交连接的事务,然后关闭连接
-
public static void commitAndCloseQuietly(Connection conn): 用来提交连接,然后关闭连接,并且在关闭连接时不抛出SQL异常。
-
public static void rollback(Connection conn)throws SQLException:允许conn为null,因为方法内部做了判断
-
public static void rollbackAndClose(Connection conn)throws SQLException
-
rollbackAndCloseQuietly(Connection)
-
public static boolean loadDriver(java.lang.String driverClassName):这一方装载并注册JDBC驱动程序,如果成功就返回true。使用该方法,你不需要捕捉这个异常ClassNotFoundException。
-
9.2.2 QueryRunner类
-
该类简单化了SQL查询,它与ResultSetHandler组合在一起使用可以完成大部分的数据库操作,能够大大减少编码量。
-
QueryRunner类提供了两个构造器:
-
默认的构造器
-
需要一个 javax.sql.DataSource 来作参数的构造器
-
-
QueryRunner类的主要方法:
-
更新
-
public int update(Connection conn, String sql, Object... params) throws SQLException:用来执行一个更新(插入、更新或删除)操作。
-
......
-
-
插入
-
public <T> T insert(Connection conn,String sql,ResultSetHandler<T> rsh, Object... params) throws SQLException:只支持INSERT语句,其中 rsh - The handler used to create the result object from the ResultSet of auto-generated keys. 返回值: An object generated by the handler.即自动生成的键值
-
....
-
-
批处理
-
public int[] batch(Connection conn,String sql,Object params)throws SQLException: INSERT, UPDATE, or DELETE语句
-
public <T> T insertBatch(Connection conn,String sql,ResultSetHandler<T> rsh,Object params)throws SQLException:只支持INSERT语句
-
.....
-
-
查询
-
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException:执行一个查询操作,在这个查询中,对象数组中的每个元素值被用来作为查询语句的置换参数。该方法会自行处理 PreparedStatement 和 ResultSet 的创建和关闭。
-
-
// 测试添加 @Test public void testInsert() throws Exception { QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = "insert into customers(name,email,birth)values(?,?,?)"; int count = runner.update(conn, sql, "何成飞", "he@qq.com", "1992-09-08"); System.out.println("添加了" + count + "条记录"); JDBCUtils.closeResource(conn, null); }
9.2.3 ResultSetHandler接口及实现类
-
该接口用于处理 java.sql.ResultSet,将数据按要求转换为另一种形式。
-
ResultSetHandler 接口提供了一个单独的方法:Object handle (java.sql.ResultSet .rs)。
-
接口的主要实现类:
-
ArrayHandler:把结果集中的第一行数据转成对象数组。
-
ArrayListHandler:把结果集中的每一行数据都转成一个数组,再存放到List中。
-
BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。就是说该实现类return一个JavaBean类型
-
BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。就是说该实现类return一个list里面放着JavaBean。
-
ColumnListHandler:将结果集中某一列的数据存放到List中。
-
KeyedHandler(name):将结果集中的每一行数据都封装到一个Map里,再把这些map再存到一个map里,其key为指定的key。
-
MapHandler:将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
-
MapListHandler:将结果集中的每一行数据都封装到一个Map里,然后再存放到List
-
ScalarHandler:
-
/* * 测试查询:查询一条记录 * * 使用ResultSetHandler的实现类:BeanHandler */ @Test public void testQueryInstance() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = "select id,name,email,birth from customers where id = ?"; // BeanHandler<Customer> handler = new BeanHandler<>(Customer.class); Customer customer = runner.query(conn, sql, handler, 23); System.out.println(customer); JDBCUtils.closeResource(conn, null); }
/* * 测试查询:查询多条记录构成的集合 * * 使用ResultSetHandler的实现类:BeanListHandler */ @Test public void testQueryList() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = "select id,name,email,birth from customers where id < ?"; // BeanListHandler<Customer> handler = new BeanListHandler<>(Customer.class); List<Customer> list = runner.query(conn, sql, handler, 23); list.forEach(System.out::println); JDBCUtils.closeResource(conn, null); }
/* * 自定义ResultSetHandler的实现类 */ @Test public void testQueryInstance1() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = "select id,name,email,birth from customers where id = ?"; ResultSetHandler<Customer> handler = new ResultSetHandler<Customer>() { @Override public Customer handle(ResultSet rs) throws SQLException { System.out.println("handle"); // return new Customer(1,"Tom","tom@126.com",new Date(123323432L)); if(rs.next()){ int id = rs.getInt("id"); String name = rs.getString("name"); String email = rs.getString("email"); Date birth = rs.getDate("birth"); return new Customer(id, name, email, birth); } return null; } }; Customer customer = runner.query(conn, sql, handler, 23); System.out.println(customer); JDBCUtils.closeResource(conn, null); }
/* * 如何查询类似于最大的,最小的,平均的,总和,个数相关的数据, * 使用ScalarHandler * */ @Test public void testQueryValue() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); //测试一: // String sql = "select count(*) from customers where id < ?"; // ScalarHandler handler = new ScalarHandler(); // long count = (long) runner.query(conn, sql, handler, 20); // System.out.println(count); //测试二: String sql = "select max(birth) from customers"; ScalarHandler handler = new ScalarHandler(); Date birth = (Date) runner.query(conn, sql, handler); System.out.println(birth); JDBCUtils.closeResource(conn, null); }
总结 @Test public void testUpdateWithTx() { Connection conn = null; try { //1.获取连接的操作( //① 手写的连接:JDBCUtils.getConnection(); //② 使用数据库连接池:C3P0;DBCP;Druid //2.对数据表进行一系列CRUD操作 //① 使用PreparedStatement实现通用的增删改、查询操作(version 1.0 version 2.0) //version2.0的增删改public void update(Connection conn,String sql,Object ... args){} //version2.0的查询 public <T> T getInstance(Connection conn,Class<T> clazz,String sql,Object ... args){} //② 使用dbutils提供的jar包中提供的QueryRunner类 //提交数据 conn.commit(); } catch (Exception e) { e.printStackTrace(); try { //回滚数据 conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } }finally{ //3.关闭连接等操作 //① JDBCUtils.closeResource(); //② 使用dbutils提供的jar包中提供的DbUtils类提供了关闭的相关操作 } }
-----------------------------------以下内容为自己的总结,可以多看看,多敲代码-----------------------------------
数据库以mysql为例,首先导入mysql的jdbc的jar包。
连接池以Druid为例,首先导入druid的jar包。
crud(增删改查)以Apache-DBUtils为例,首先导入commons-dbutils.jar包。
 自己写get,set什么的。
自己写get,set什么的。
package com.atguigu.common; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.*; import java.util.Properties; /** * Created by Zhuxiang on 2020/4/28. */ public class JDBCUtils { //德鲁伊连接池连接数据库 public static Connection getDruidSourceFactory(){ try { Properties pro = new Properties(); InputStream ia = JDBCUtils.class.getClassLoader().getResourceAsStream("com/atguigu/common/druid.properties"); pro.load(ia); DataSource ds = DruidDataSourceFactory.createDataSource(pro); Connection connection = ds.getConnection(); System.out.println(connection); return connection; } catch (Exception e) { e.printStackTrace(); } return null; } //jdbc普通连接数据库 public static Connection getConnection(){ try { Properties pro = new Properties(); InputStream is = JDBCUtils.class.getClassLoader().getResourceAsStream("com/atguigu/common/jdbc.properties"); pro.load(is); Class.forName(pro.getProperty("driver")); Connection conn = DriverManager.getConnection(pro.getProperty("url"), pro.getProperty("user"), pro.getProperty("password")); System.out.println(conn); return conn; } catch (Exception e) { e.printStackTrace(); } return null; } //关闭资源(增删改) public static void closeResource(Connection conn,Statement ps){ try { if(ps != null) ps.close(); } catch (SQLException e) { e.printStackTrace(); } try { if(conn != null) conn.close(); } catch (SQLException e) { e.printStackTrace(); } } //关闭资源(查) public static void closeResource(Connection conn,Statement ps,ResultSet rs) { try { if (ps != null) ps.close(); } catch (SQLException e) { e.printStackTrace(); } try { if (conn != null) conn.close(); } catch (SQLException e) { e.printStackTrace(); } try { if (rs != null) rs.close(); } catch (SQLException e) { e.printStackTrace(); } } }
properties文件写法不再赘述(上面的笔记里有)

package com.atguigu.dao; import com.atguigu.common.JDBCUtils; import org.apache.commons.dbutils.QueryRunner; import org.apache.commons.dbutils.handlers.BeanHandler; import java.lang.reflect.Field; import java.sql.*; /** * Created by Zhuxiang on 2020/4/29. * 初级版通用方法,与上面的basedao的主要区别在于,上面使用了反射,并把basedao变成泛型类, * 当impl实现类去继承basedao时,basedao里的代码块或者构造器被调用,直接 * 可以通过反射获得实现类父类的泛型(也就是被继承的父类basedao自己的类型)。 * 这样可以使一些方法不再需要传递class类,简化了代码。 * 可以更好地与第三方jar包,如dbutils交互,进一步简化代码。 */ public abstract class BaseDao00 { //导入的第三方包dbutils里的,可以简化增删改查。 private QueryRunner qr=new QueryRunner(); //自己写的getbean (初级版通用方法)还需要传递class,没有最简化代码, public <T>T getBean00(Connection conn, String sql,Class<T> aclass, Object...params){ PreparedStatement ps = null; ResultSet rs = null; ResultSetMetaData md = null; try { ps = conn.prepareStatement(sql); for (int i = 0; i < params.length; i++) { ps.setObject(i+1,params[i]); } rs = ps.executeQuery(); md = rs.getMetaData(); if(rs.next()){ T t = aclass.newInstance(); for(int i=0;i<md.getColumnCount();i++){ Object columnval = rs.getObject(i + 1); String columnLabel = md.getColumnLabel(i+1); Field field = aclass.getDeclaredField(columnLabel); field.setAccessible(true); field.set(t,columnval); } return t; } } catch (Exception e) { e.printStackTrace(); } finally { JDBCUtils.closeResource(null,ps,rs); } return null; } //通过第三方包dbutils写的getbean,效果和上面一样的。 public <T>T getBeanDbutils(Connection conn, String sql,Class<T> aclass,Object...params ){ try { T query = qr.query(conn, sql, new BeanHandler<T>(aclass), params); return query; } catch (SQLException e) { e.printStackTrace(); } return null; } }
package com.atguigu.dao; import com.atguigu.common.JDBCUtils; import org.apache.commons.dbutils.QueryRunner; import org.apache.commons.dbutils.handlers.BeanHandler; import java.lang.reflect.Field; import java.lang.reflect.ParameterizedType; import java.lang.reflect.Type; import java.sql.*; /** * Created by Zhuxiang on 2020/4/28. * 这是最终版,使用了反射,并把basedao变成泛型类,当impl实现类去继承basedao时, * basedao里的代码块或者构造器被调用,直接可以通过反射获得 * 实现类父类的泛型(也就是basedao自己的泛型)。这样可以 * 使一些方法不再需要传递class类,简化了代码。 * 可以更好地与第三方jar包,如dbutils交互,进一步简化代码。 */ public abstract class BaseDao<T>{ //导入的第三方包dbutils里的,可以简化增删改查。 private QueryRunner qr=new QueryRunner(); //定义一个变量来接收泛型的类型 private Class<T> type; // 构造器与下面的代码块同效果 // public BaseDao() { // } { //虽然可以放在impl实现类里,但是这样做每个impl实现类都需要写,重复代码太多。 //所谓获取子类,其实就是impl实现类。毕竟this指的就是impl实现类。 //获取子类的类型 Class<? extends BaseDao> aClass = this.getClass(); //getGenericSuperclass()获取父类的类型 //ParameterizedType表示的是带泛型的类型 ParameterizedType parameterizedType =(ParameterizedType) aClass.getGenericSuperclass(); //getActualTypeArguments()获得具体的泛型 Type[] types = parameterizedType.getActualTypeArguments(); this.type=(Class<T>)types[0]; } //自己写的最终版getbean通用方法 public T getBean(Connection conn, String sql, Object...params){ PreparedStatement ps = null; ResultSet rs = null; ResultSetMetaData md = null; try { ps = conn.prepareStatement(sql); for (int i = 0; i < params.length; i++) { ps.setObject(i+1,params[i]); } rs = ps.executeQuery(); md = rs.getMetaData(); if(rs.next()){ T t = type.newInstance(); for(int i=0;i<md.getColumnCount();i++){ Object columnval = rs.getObject(i + 1); String columnLabel = md.getColumnLabel(i+1); Field field = type.getDeclaredField(columnLabel); field.setAccessible(true); field.set(t,columnval); } return t; } } catch (Exception e) { e.printStackTrace(); } finally { JDBCUtils.closeResource(null,ps,rs); } return null; } //通过第三方包dbutils写的getbean,效果和上面一样的。 public T getBeanDbutils(Connection conn, String sql,Object...params ){ try { T query = qr.query(conn, sql, new BeanHandler<T>(type), params); return query; } catch (SQLException e) { e.printStackTrace(); } return null; } }
package com.atguigu.dao.impl; import com.atguigu.beans.Admin; import com.atguigu.common.JDBCUtils; import com.atguigu.dao.AdminDao; import com.atguigu.dao.BaseDao; import org.apache.commons.dbutils.DbUtils; import org.junit.Test; import java.sql.Connection; /** * Created by Zhuxiang on 2020/4/28. */ public class AdminDaoImpl extends BaseDao<Admin> implements AdminDao { @Test public void getAdminbean() { Connection conn = JDBCUtils.getConnection(); String sql = "select * from admin"; // 在这里写代码用dbutils倒是省事,但是不去写basedao的话会造成太多的重复代码。 // QueryRunner qr = new QueryRunner(); // BeanListHandler blh = new BeanListHandler<>(Admin.class); // Object query =qr.query(conn, sql, blh); // System.out.println(query.toString()); Admin admin = getBeanDbutils(conn, sql); System.out.println(admin.toString()); //第三方包dbutils里的utils DbUtils.closeQuietly(conn); } }