1. nltk简介
http://www.nltk.org
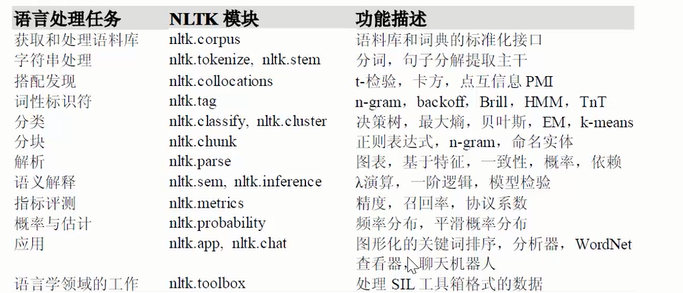
2. nltk能做什么?
2.1 搜索文本
- 单词搜索
- 相似词搜索
- 相似关键词识别
- 词汇分布图
- 生成文本
from nltk.book import * # 词语搜索 print('搜索词monstrous->') text1.concordance('monstrous') print('上下文相似词->') # 上下文相似词, 没有返回值 text2.similar('monstrous') # 共同上下文 print('monstrous, very共同上下文') text2.common_contexts(['monstrous', 'very']) # 词汇分布表 text4.dispersion_plot(['citizens', 'democracy', 'freedom', 'duties', 'America']) # 词数统计 len(text3) # 出现的不重复词语的词数 len(set(text3)) # 排序 sorted(set(text3)) # 重复词密度 from __future__ import division len(text3) / len(set(text3)) # 关键词密度 text3.count('smote') 100 * text4.count('a') / len(text4) # 平均词密度, 平均每个词出现的词数 def lexical_diversity(text): return len(text) / len(set(text)) lexical_diversity(text1)
2.2 计数词汇
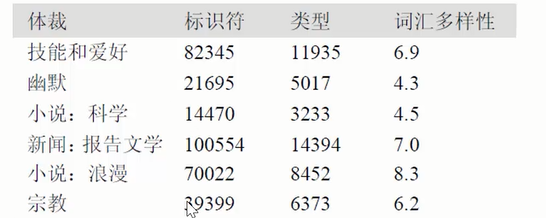
3. 词链表
print(sent1) # ['Call', 'me', 'Ishmael', '.'] print(sent1[1:3])
3.1 词频分布
nltk内置的统计类:FeDist
fdist = FreqDist(text1) print(fdist)

# 频率累计分布图 fdist.plot(50, cumulative=True)
频率累计分布图:

丢弃高频且没有意义的词,或者是抽取具有P特性(例如词的长度大于15)的词汇。
# 细粒度的选择词 V = set(text5) long_words = [w for w in V if len(w) >= 15] sorted(long_words) # 综合词的长度和词频,进行筛选 sorted([w for w in set(text5) if len(w) > 7 and fdist[w] > 7])

词语搭配:
from nltk.util import bigrams # 二元语法, trigrams 三元语法 list(bigrams(['more', 'is', 'said', 'than', 'done'])) # [('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
# 经常出现的双联次
text1.collocations()
词长分布,对作者的文章也是有影响的:
# 词长分布 fdist = FreqDist([len(w) for w in text1]) fdist.items() # dict_items([(1, 47933), (4, 42345), (2, 38513), (6, 17111), (8, 9966), (9, 6428), (11, 1873), (5, 26597), (7, 14399), (3, 50223), (10, 3528), (12, 1053), ( # 13, 567), (14, 177), (16, 22), (15, 70), (17, 12), (18, 1), (20, 1)])
4. 自然语言处理(NLP)
自然语言:自然的随着文化演化的语言,就是人们日常使用的语言。
自然语言处理:用计算机对自然语言进行操作。
自然语言研究的内容:
- 此意消岐
- 指代理解
- 自动生成语言
- 机器翻译
- 人机对话系统
- 文本含义识别
5. nltk语料库
end