1列表,字典推导式?
# 字典推导式 d = {key:value for (key,value) in iterable } # 字典推导式格式 : {key:value for循环 if判断} dict1 = {“name”: “zhangsan”, “age”: 18} dict2 = {value: key for key, value in dict1.items()} print(dict2) # {'1': 'name', 18: 'age'} # 列表推导式 l= [x*y for x in range(1,5) if x>2 for y in range(1,4) if y < 3] # 3,4 1,2 x*y # [3, 6, 4, 8]
python可变对象和不可变对象?
-
不可对象: 数字类型, 字符串, 元组. 不允许改变变量的值,改变后会创建新的对象即指向新的内存空间
-
可变对象: 列表, 字典, 集合.允许变量的值发生改变且内存地址不变,不会创建新的对象,
python内置数据类型?
-
数字类型,字符串类型, 元组, 列表,字典,集合
python 中有多少种运算符?并简单说明.
-
算术运算符: + - * / 等
-
赋值运算符: = += -= /= 等
-
逻辑运算符: and or not
-
位运算符: & | ~ ^
-
身份运算符: is not is
-
关系运算符: > < == >= <=等
-
成员运算符: in not in
python 2 和python 3 的区别?
2python 中 单下划线 , 双下划线 ?
-
单下换线 _xx : 是一种约定, 表示私有变量, 但是外部也可以调用
-
单 双下换线: __xx : 表示真正的私有变量, 只有内部可以调用. 不过也有特殊的方法使外部也可以调用
-
双 双下划线: 表示系统变量.
3python自省 ?
-
自省就是面向对象的语言所写的程序在运行时, 就可以知道对象的类型.
a = [1,2,3] b = {'a':1,'b':2,'c':3} c = True print(type(a),type(b),type(c)) # <type 'list'> <type 'dict'> <type 'bool'>
4python作用域
-
范围从大到小: 内置作用域 --> 全局作用域 - -> 闭包作用域 --> 局部作用
-
查找顺序: 局部作用域 --> 闭包作用域 --> 全局作用域 --> 內置作用域
5new 和 int的区别?
-
new 实例创建之前调用,创建实例返回实例对象.是个静态方法. 必须有返回值.在 init 之前调用
-
int 实例对象创建之后调用, 初始化类的实例.是个实例方法
※ __new__和__init__的区别,说法正确的是? (ABCD)
A. __new__是一个静态方法,而__init__是一个实例方法
B. __new__方法会返回一个创建的实例,而__init__什么都不返回
C. 只有在__new__返回一个cls的实例时,后面的__init__才能被调用
D. 当创建一个新实例时调用__new__,初始化一个实例时用__init__
6lambda函数?, 有什么好处?
-
lambda函数比较轻便,即用即删, 也不用费神的去命名.
# 有参五默认值 f = lambda x,y: x*y f(6,7) #42 # 有参有默认值 f = lambda x=5, y=8: x*y f() #40 f(5,6) #30
7python 中的 is 和 == 的区别?
-
首先python 对象 有三个基本要素 1. id 即 内存地址 2. type 即 对象类型 3. value 值.
-
is 是判断 对象是否是同一对象 即 判断 id 是否相同
-
== 是判断对象是否相等, 即判断value值是否相等
8python 中 赋值, 浅拷贝, 深拷贝?
-
赋值: 不会创建新的对象, 是对原对象的引用.简单说就是给原对象起了个新名字.
-
浅拷贝: 会创建的新的对象, 两个对象不指向同一内存空间, 但是浅拷贝只是拷贝第一层, 对象里面的元素指向同一内存空间, 改变原对象里面的元素 拷贝的对象也会改变.
-
深拷贝: 会创建一个全新对象, 两个对象不指向同一内存空间, 即使 原对象 存在多层嵌套, 改变原对象,拷贝的对象也不会发生改变.
-
注意: 对于非容器没有拷贝一说(数字类型, 字符串等),如果元组变量只包括原子类型则没有深拷贝
import copy 一层的情况: # 浅拷贝 li1 = [1, 2, 3] li2 = li1.copy() li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] # 深拷贝 li1 = [1, 2, 3] li2 = copy.deepcopy(li1) li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] 多层的情况: import copy # 浅拷贝 li1 = [1, 2, 3, [4, 5], 6] li2 = li1.copy() li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5, 7], 6] # 深拷贝 li1 = [1, 2, 3, [4, 5], 6] li2 = copy.deepcopy(li1) li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5], 6]
9装饰器?
-
装饰器本质也是一个函数. 在不改变源代码的情况下, 给函数增加额外的功能.返回值也是个函数.
def wrapper(func): def innier(*args,**kwargs): '''被装饰函数前需要的添加的内容''' ret = func(*args,**kwargs) #被装饰的函数 '''被装饰函数后需要添加的内容''' return ret return inner
10闭包?
-
函数嵌套函数, 内函数必须引用外函数的临时变量, 外函数的返回值必须是内函数的引用.
11递归函数?
-
如果一个函数在内部 直接或者间接的调用自身
-
递归函数最大递归层数: 998
-
递归函数必须有一个终止条件
12python 中的 可迭代对象, 迭代器, 生成器 ?
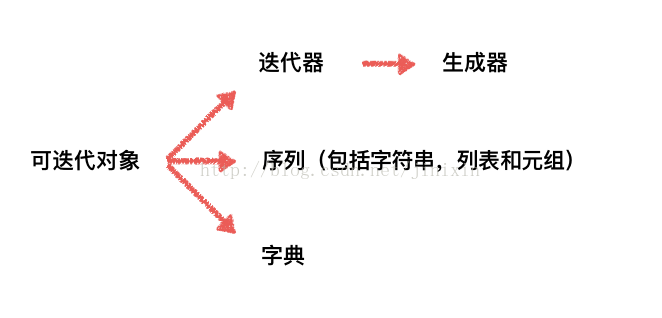
-
可迭代对象包括 迭代器, 序列(字符串, 列表, 元组), 字典. 生成器是一种特殊的迭代器
-
可迭代对象 一般能被for循环遍历的对象就是可迭代对象, 如果给一个确切的定义的话, 就是 只要它返回一个迭代器的 iter 方法,或者支持下标索引的 getitem方法 那么他就是可迭代对象.
-
如果一个对象拥有 iner 方法 那么它就是可迭代对象, 如果一个对象拥有iter, next方法 那么他就是一个迭代器
-
生成器 是一种特殊的迭代器 , 生成器自动实现了 iter next 方法, 不需要手动实现, 具有yield 关键字的都是生成器, yield 可以理解的为 return 不同的是 return 返回后 函数就会释放, 而生成器不会, 它会从yield 下一句开始执行, 直到遇到下一个yield
13python 进程, 线程, 协程 ?
-
简单说 有个运行的程序就一个进程, 进程是
-
线程一般使用的是 threading 模块,
14谈谈python GIL 锁 ?
-
GIL 锁, 全局解释器锁, 限制多线程同时执行,保证同一时间内只有一个线程在执行.
-
GIL锁是 解释器(CPython)中引入发一个概念, 如果不是用的cpython解释器就不存在这个问题
-
为了更好的利用多核处理器的性能, 就出现了多线程编程的方式,各个线程访问数据资源时会出现竞争状态,即数据可能会同时被多个线程占用,造成数据混乱的情况.这就是线程的不安全.因此就出现了 GIL全局解释器锁 来限制多线程同时执行, 保证同一时间只有一个线程在执行.
-
因为GIL全局解释器锁的存在, 就导致CPython解释器下的多线程实则是伪多线程. 解决 1. 进程 + 协程. 2. 更换解释器
15python的内存管理机制 ?
-
引用计数: 在python中, 每个对象都有指向该对象的引用总数即引用计数, 查看对象的引用计数: sys.getrefcount(), 当一个python对象被引用时其引用计数加一; 当引用计数等于 0 时 对象被删除.
-
垃圾回收
-
内存池机制: python 中分为大内存和小内存: 256k为界限
-
大内存使用malloc 进行分配
-
小内存使用内存池是进行分配
-
python的内存池金字塔:
-
第3层: 最上层, 用户对python对象的直接操作
-
第1层和第2层: 内存池, 有python 的 接口函数 PyMen_Malloc 实现, 若请求分配的内存在1 - 256字节之间就使用内存池进行分配, 调用malloc 函数分配内存, 但是每次只会分配 256 k 的内存. 不会调用free 函数释放内层. 将该内存块留在内存池中便下次使用
-
第 0 层: 大内存 . 若请求分配的内存大于 256 k , malloc函数分配, free函数释放内存
-
第 - 1 -2 层: 操作系统进行操作
-
-
16简述 解释型语言 和 编译型语言?
-
解释型语言: 解释型语言编写的程序不需要编译, 在执行的时候,专门有一个解释器能够将其翻译成机器语言,每个语句都是在执行时才被翻译. 解释型语句执行一次就会翻译一次.
-
编译型语言: 编译型语言写的程序执行之前, 需要一个专门的编译过程, 通过编译系统把原高级程序编译成机器语言文件, 编译只做一次, 运行时不需要编译.
17python解释器的种类 以及特点 ?
-
CPython : 是用C语言开发的, 所以叫CPython , 在命令行下运行python就是 CPython解释器, CPython 是使用的最广的python解释器
-
IPython : IPython 是基于CPython 之上的一个互交的解释器, IPython , 只是在交互方式上有所增加, 其他方面跟CPython 一样.
-
PyPy: 它 目标是速度, pypy 采用 JIT 技术, 对于python 代码进行动态编译, 所以在运行速度显著提高
-
JPython : JPython 是运行在java 平台上的python解释器, 可以直接把python代码编译成Java字节码执行
python 参数传递是值传递还是引用传递?
-
首先 python的参数传递有: 位置参数, 默认值参数, 可变参数, 关键字参数.
-
函数的传值到底是值传递还是引用传递,要分情况:
-
A 不可变参数用值传递: 像整数和字符串这样的不可变对象, 是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象
-
B 可变参数是引用传递: 比如列表, 字典这样的对象是通过引用传递,可变对象能在函数内部改变
网络部分
1cookie 和session 的区别?
2常见的端口号?
1 http 和https 区别?
2http常见状态码?
3UDP 和 CTP 的区别?
tcp/ip 协议族
4七成模型?
5csrf 攻击及防御?
url形式?
六大设计原则
数据库整理
mysql
基础部分:
面试部分:
1数据库优化?
2mysql 事务特性?
-
原子性:
-
隔离性:
-
一致性:
-
持久性:
3mysql 有哪些引擎, 有什么区别?
-
innodb:
-
支持事务
-
支持外键
-
支持行级锁
-
5.5.5以后默认索引是innodb, 5.6.4innodb 也支持全文索引
-
比较适合频繁修改,以及涉及安全性较高的 应用
-
innodb 不保存表单行数, select conunt(*) from 表 时 innodb 需要 扫描全表计算有多少行
-
-
myisam:
-
不支持事务
-
不支持外键
-
支持表级锁
-
5.5.5 以前是mysql的默认引擎,支持全文索引
-
比较适合繁查询,插入为主的应用.
-
myisam 保存表的行数, 比如 select conunt(*) from 表 时 只需要读取出保存的行数
-
4索引的类型?
-
唯一索引: 索引的列必须唯一, 允许为空值
-
主键索引: 特殊的唯一索引,不允许有空值
-
全文索引: myisam 特有的 针对大数据 但是生成全文索引 耗时耗空间
-
5.6.4 以前只有myisam 支持全文索引. 以后 innodb引擎也支持
-
-
普通索引: 最基本的索引 没有任何限制
-
复合索引: 多个字段同时建立索引
-
查看所有的的索引: show index from 表名/G
-
唯一索引
-
alter table 表 add unique(username); 创建唯一索引 没有名字
alter table 表 add unique un_naem(username); 创建有名字的唯一索引
-
-
主键索引
-
alter table 表名 add primary key(id) 创建主键索引
-
alter table 表名 modif id int(11) unsigned not null auto_increment 自增
-
-
全文索引
-
alter table 表名 add fulltext f_name(username); 创建全文本索引
-
alter table 表名 drop index f_name 删除全文索引
-
-
-