【常用分词器】
- SimpleAnalyzer
- StopAnalyzer
- WhitespaceAnalyzer
- StandardAnalyze
【TokenStream】
she is a student ==〉TokenStream
TokenStream有2个实现类。Tokenizer、TokenFilter
1) Tokenizer
将数据进行分割形成一定的语汇(所谓语汇是指一个一个独立的词语。)。最终结果将形成TokenStream。

2) TokenFilter
按照规则对语汇进行过滤。如:StopFilter可以对停用词进行过滤。
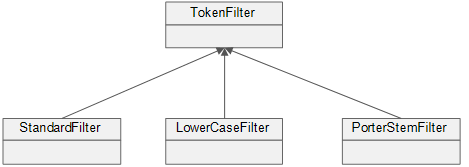
3) 执行过程

【存储方式】

【应用TokenStream】
1 /** 2 * 使用TokenStream进行分词 3 * @param str 4 * @param analyzer 5 */ 6 public static void displayTokenStream(String str, Analyzer analyzer){ 7 try { 8 //通过Analayer获取TokenStream 9 //toenStream("域名称或文件名",输入流对象) 10 TokenStream stream = analyzer.tokenStream("content", new StringReader(str)); 11 12 //向流中添加一个属性 13 //容器,存储每次分词所对应的语汇内容 14 CharTermAttribute charAttr = stream.addAttribute(CharTermAttribute.class); 15 16 //通过循环语句读取语汇的内容 17 while(stream.incrementToken()){ 18 System.out.print("[" + charAttr + "] "); 19 } 20 System.out.println(); 21 } catch (IOException e) { 22 e.printStackTrace(); 23 } 24 }
1 private Version version = Version.LUCENE_35; 2 3 /** 4 * 测试TokenStream(英文内容) 5 */ 6 @Test 7 public void test01(){ 8 String str = "I'm come from Hanlin,I love Hanlin"; 9 System.out.println("str = " + str); 10 System.out.println("===================================="); 11 12 //创建Analyzer对象 13 Analyzer a1 = new SimpleAnalyzer(version); 14 Analyzer a2 = new StopAnalyzer(version); 15 Analyzer a3 = new WhitespaceAnalyzer(version); 16 Analyzer a4 = new StandardAnalyzer(version); 17 18 //测试TokenStream 19 AnalyzerUtil.displayTokenStream(str, a1); 20 AnalyzerUtil.displayTokenStream(str, a2); 21 AnalyzerUtil.displayTokenStream(str, a3); 22 AnalyzerUtil.displayTokenStream(str, a4); 23 }
1 /** 2 * 测试TokenStream(中文内容) 3 */ 4 @Test 5 public void test02(){ 6 String str = "我来自翰林,我爱翰林"; 7 System.out.println("str = " + str); 8 System.out.println("===================================="); 9 10 //创建Analyzer对象 11 Analyzer a1 = new SimpleAnalyzer(version); 12 Analyzer a2 = new StopAnalyzer(version); 13 Analyzer a3 = new WhitespaceAnalyzer(version); 14 Analyzer a4 = new StandardAnalyzer(version); 15 16 //测试TokenStream 17 AnalyzerUtil.displayTokenStream(str, a1); 18 AnalyzerUtil.displayTokenStream(str, a2); 19 AnalyzerUtil.displayTokenStream(str, a3); 20 AnalyzerUtil.displayTokenStream(str, a4); 21 }
TokenStream可以读取到分词内容.
【Attribute】
1 /** 2 * 显示语汇的基本属性 3 * @param str 4 * @param anlyzer 5 */ 6 public static void displayAttributes(String str, Analyzer anlyzer){ 7 try { 8 //获取TokenStream对象 9 TokenStream stream = anlyzer.tokenStream("content", new StringReader(str)); 10 11 //PositionIncrementAttribute :存储了语汇之间的位置增量 12 //添加PositionIncrementAttribute属性 13 PositionIncrementAttribute positionAttr = stream.addAttribute(PositionIncrementAttribute.class); 14 15 //添加CharTermAttrbute 16 CharTermAttribute charAttr = stream.addAttribute(CharTermAttribute.class); 17 //OffsetAttribute:获取语汇的偏移数据 18 OffsetAttribute offsetAttr = stream.addAttribute(OffsetAttribute.class); 19 20 //语汇的分词方式类型(了解) 21 TypeAttribute typeAttr = stream.addAttribute(TypeAttribute.class); 22 23 //遍历每一个语汇 24 while(stream.incrementToken()){ 25 System.out.print(positionAttr.getPositionIncrement() + "、"); 26 System.out.print("[" + charAttr + " : " + offsetAttr.startOffset() + "~" + offsetAttr.endOffset()+ "(" + typeAttr.type()+ ")] " ); 27 } 28 System.out.println(); 29 30 } catch (IOException e) { 31 e.printStackTrace(); 32 } 33 }
1 /** 2 * 测试属性的应用 3 */ 4 @Test 5 public void test03(){ 6 String str = "I'm come from Hanlin,I love Hanlin"; 7 System.out.println("str = " + str); 8 System.out.println("===================================="); 9 10 //创建Analyzer对象 11 Analyzer a1 = new SimpleAnalyzer(version); 12 Analyzer a2 = new StopAnalyzer(version); 13 Analyzer a3 = new WhitespaceAnalyzer(version); 14 Analyzer a4 = new StandardAnalyzer(version); 15 16 //测试TokenStream 17 AnalyzerUtil.displayAttributes(str, a1); 18 AnalyzerUtil.displayAttributes(str, a2); 19 AnalyzerUtil.displayAttributes(str, a3); 20 AnalyzerUtil.displayAttributes(str, a4); 21 }
FlagsAttribute:标志位属性信息(了解)
PayloadAttribute:负载属性信息(了解)
说明:每一个语汇单元都存在一定的属性.通过Attribute可以获取到相关的语汇信息。