数据库
数据库管理软件的由来
基于我们之前所学,数据要想永久保存,都是保存于文件中,毫无疑问,一个文件仅仅只能存在于某一台机器上。
如果我们暂且忽略直接基于文件来存取数据的效率问题,并且假设程序所有的组件都运行在一台机器上,那么用文件存取数据,并没有问题。
很不幸,这些假设都是你自己意淫出来的,上述假设存在以下几个问题。。。。。。
1、程序所有的组件就不可能运行在一台机器上
#因为这台机器一旦挂掉则意味着整个软件的崩溃,并且程序的执行效率依赖于承载它的硬件,而一台机器机器的性能总归是有限的,受限于目前的硬件水平,就一台机器的性能垂直进行扩展是有极限的。
#于是我们只能通过水平扩展来增强我们系统的整体性能,这就需要我们将程序的各个组件分布于多台机器去执行。
2、数据安全问题
#根据1的描述,我们将程序的各个组件分布到各台机器,但需知各组件仍然是一个整体,言外之意,所有组件的数据还是要共享的。但每台机器上的组件都只能操作本机的文件,这就导致了数据必然不一致。
#于是我们想到了将数据与应用程序分离:把文件存放于一台机器,然后将多台机器通过网络去访问这台机器上的文件(用socket实现),即共享这台机器上的文件,共享则意味着竞争,会发生数据不安全,需要加锁处理。。。。
3、并发
根据2的描述,我们必须写一个socket服务端来管理这台机器(数据库服务器)上的文件,然后写一个socket客户端,完成如下功能:
#1.远程连接(支持并发)
#2.打开文件
#3.读写(加锁)
#4.关闭文件
总结:
我们在编写任何程序之前,都需要事先写好基于网络操作一台主机上文件的程序(socket服务端与客户端程序),于是有人将此类程序写成一个专门的处理软件,这就是mysql等数据库管理软件的由来,但mysql解决的不仅仅是数据共享的问题,还有查询效率,安全性等一系列问题,总之,把程序员从数据管理中解脱出来,专注于自己的程序逻辑的编写。
数据库概述
什么是数据(Data) ?
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片,图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
# zhou,male,18,1999,山东,2017
单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思,相当于定义表的标题
# name,sex,age,birth,born_addr,create_time #字段
# zhou,male,18,1999,山东,2017 #记录
这样我们就可以了解zhou,性别为男,年龄18岁,出生于1999年,出生地为山东,博客日期为2017年
什么是数据库(DataBase,简称DB)?
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用
数据库是长期存放在计算机内、有组织、可共享的数据即可。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种 用户共享
什么是数据库管理系统(DataBase Management System 简称DBMS)?
在了解了Data与DB的概念后,如何科学地组织和存储数据,如何高效获取和维护数据成了关键
这就用到了一个系统软件---数据库管理系统
如MySQL、Oracle、SQLite、Access、MS SQL Server
mysql主要用于大型门户,例如搜狗、新浪等,它主要的优势就是开放源代码,因为开放源代码这个数据库是免费的,他现在是甲骨文公司的产品。
oracle主要用于银行、铁路、飞机场等。该数据库功能强大,软件费用高。也是甲骨文公司的产品。
sql server是微软公司的产品,主要应用于大中型企业,如联想、方正等。
数据库服务器、数据管理系统、数据库、表与记录的关系?
记录:1 大龙 324245234 22(多个字段的信息组成一条记录,即文件中的一行内容)
表:student,scholl,class_list(即文件)
数据库:oldboy_stu(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
数据库服务器-:运行数据库管理软件
数据库管理软件:管理-数据库
数据库:即文件夹,用来组织文件/表
表:即文件,用来存放多行内容/多条记录
数据库管理技术的发展历程
一 人工管理阶段
20世纪50年代中期以前,计算机主要用于科学计算。
当时的硬件水平:外存只有纸带、卡片、磁带,没有磁盘等直接存取的存储设备
当时的软件状况:没有操作系统,没有管理数据的软件,数据的处理方式是批处理。
人工管理数据具有以下特点:
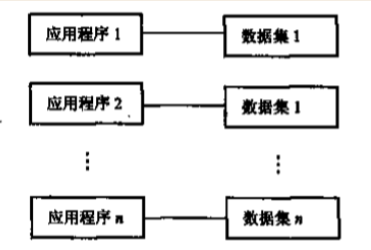
1 数据不保存:计算机主要用于科学计算,数据临时用,临时输入,不保存
2 应用程序管理数据:数据要有应用程序自己管理,应用程序需要处理数据的逻辑+物理结构,开发负担很重
3 数据不共享:一组数据只对应一个程序,多个程序之间涉及相同数据时,必须各自定义,造成数据大量冗余
4 数据不具有独立性:数据的逻辑结构或物理结构发生变化后,必须对应用程序做出相应的修改,开发负担进一步加大
二 文件系统阶段
20世纪50年代后期到60年代中期
硬件水平:有了磁盘、磁鼓等可直接存取的存储设备
软件水平:有了操作系统,并且操作系统中已经有了专门的数据管理软件,即文件系统;处理方式上不仅有了批处理,而且能够联机实时处理
文件系统管理数据具有以下优点:
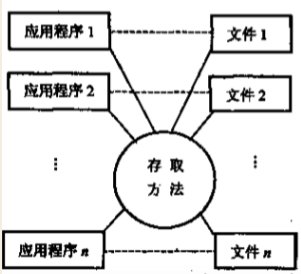
1 数据可以长期保存:计算机大量用于数据处理,因而数据需要长期保存,进行增删改查操作
2 由文件系统管理数据:文件系统这个软件,把数据组织成相对独立的数据文件,利用按文件名,按记录进行存取。实现了记录内的结构性,但整体无结构。并且程序与数据之间由文件系统提供存取方法进行转换,是应用程序与数据之间有了一定的独立性,程序员可以不必过多考虑物理细节。
文件系统管理数据具有以下缺点:
1 数据共享性差,冗余度大:一个文件对应一个应用程序,不同应用有相同数据时,也必须建立各自的文件,不能共享相同的数据,造成数据冗余,浪费空间,且相同的数据重复存储,各自管理,容易造成数据不一致性
2 数据独立性差:一旦数据的逻辑结构改变,必须修改应用程序,修改文件结构的定义。应用程序的改变,也将引起文件的数据结构的改变。因此数据与程序之间缺乏独立性。可见,文件系统仍然是一个不具有弹性的无结构的数据集合,即文件之间是孤立的,不能反映现实世界事物之间的内存联系。
三 数据系统阶段
20世纪60年代后期以来,计算机用于管理的规模越来越大,应用越来越广泛,数据量急剧增长,同时多种应用,多种语言互相覆盖地共享数据结合要求越来越强烈
硬件水平:有了大容量磁盘,硬件架构下降
软件水平:软件价格上升(开发效率必须提升,必须将程序员从数据管理中解放出来),分布式的概念盛行。
数据库系统的特点:
1 数据结构化(如上图odboy_stu)
2 数据共享,冗余度低,易扩充
3 数据独立性高
4 数据由DBMS统一管理和控制
a:数据的安全性保护
b:数据的完整性检查
c:并发控制
d:数据库恢复
存储引擎
什么是存储引擎
mysql中建立的库===>文件夹
库中建立的表===>文件
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎
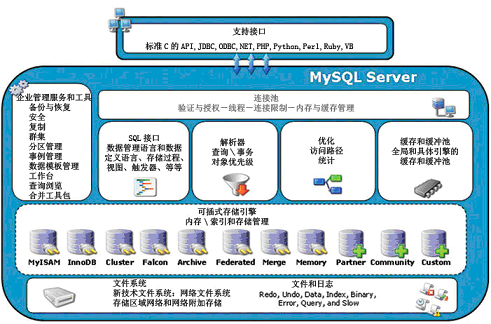
SQL 解析器、SQL 优化器、缓冲池、存储引擎等组件在每个数据库中都存在,但不是每 个数据库都有这么多存储引擎。MySQL 的插件式存储引擎可以让存储引擎层的开发人员设 计他们希望的存储层,例如,有的应用需要满足事务的要求,有的应用则不需要对事务有这 么强的要求 ;有的希望数据能持久存储,有的只希望放在内存中,临时并快速地提供对数据 的查询。
mysql支持的存储引擎
MariaDB [(none)]> show enginesG #查看所有支持的存储引擎 MariaDB [(none)]> show variables like 'storage_engine%'; #查看正在使用的存储引擎
MySQL存储引擎介绍:
InnoDB 存储引擎
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。
MyISAM 存储引擎
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。
NDB 存储引擎
2003 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。
Memory 存储引擎
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。
NTSE 存储引擎
网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
使用存储引擎
方法1:建表时指定
MariaDB [db1]> create table innodb_t1(id int,name char)engine=innodb; MariaDB [db1]> create table innodb_t2(id int)engine=innodb; MariaDB [db1]> show create table innodb_t1; MariaDB [db1]> show create table innodb_t2;
方法2:在配置文件中指定默认的存储引擎
/etc/my.cnf [mysqld] default-storage-engine=INNODB innodb_file_per_table=1
查看
[root@egon db1]# cd /var/lib/mysql/db1/ [root@egon db1]# ls db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
示例: 创建四个表,分别使用innodb,myisam,memory,blackhole存储引擎,进行插入数据测试


MariaDB [db1]> create table t1(id int)engine=innodb; MariaDB [db1]> create table t2(id int)engine=myisam; MariaDB [db1]> create table t3(id int)engine=memory; MariaDB [db1]> create table t4(id int)engine=blackhole; MariaDB [db1]> quit [root@egon db1]# ls /var/lib/mysql/db1/ #发现后两种存储引擎只有表结构,无数据 db.opt t1.frm t1.ibd t2.MYD t2.MYI t2.frm t3.frm t4.frm #memory,在重启mysql或者重启机器后,表内数据清空 #blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录