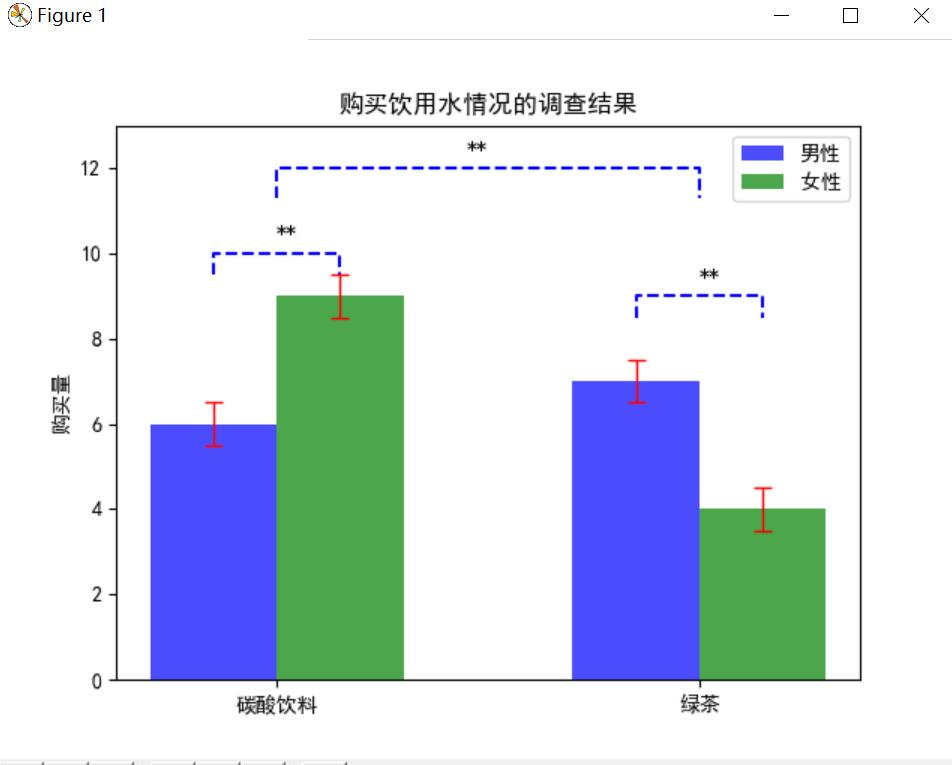
#object: 画出像方差分析那样的图 #writer: Mike #time: 2020,11,19 import matplotlib.pyplot as plt import numpy as np # 这两行代码解决 plt 中文显示的问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 输入统计数据 waters = ('碳酸饮料', '绿茶') buy_number_male = [6, 7] buy_number_female = [9, 4] bar_width = 0.3 # 条形宽度 index_male = np.arange(len(waters)) # 男生条形图的横坐标 这里是 0,1,2,3,4, index_female = index_male + bar_width # 女生条形图的横坐标 这里是 0.3,1.3,2.3 # 使用两次 bar 函数画出两组条形图,height表示的是纵坐标,with表示的是长条的宽度,label用于legend的显示。 plt.bar(index_male, height=buy_number_male, width=bar_width, color='b', label='男性',alpha=0.7) plt.bar(index_female, height=buy_number_female, width=bar_width, color='g', label='女性',alpha=0.7) #画出一组小长条的标注显著性的线,这里的坐标使用肉眼看出来的. sigX = [1,1,1.3,1.3] sigY = [8.5,9,9,8.5] plt.plot(sigX,sigY,'b--') #画出第二个显著性的线 sigX2 = [0,0,0.3,0.3] sigY2 = [9.5,10,10,9.5] plt.plot(sigX2,sigY2,'b--') #画出两组之间的显著性线 sigX3 = [0.15,0.15,1.15,1.15] sigY3 = [11.3,12,12,11.3] plt.plot(sigX3,sigY3,'b--') #画出误差棒,先画男生的,再画女生的 plt.errorbar(index_male,buy_number_male,yerr=0.5,fmt='none',ecolor='red',elinewidth=1,capthick=1,capsize=4) plt.errorbar(index_female,buy_number_female,yerr=0.5,fmt='none',ecolor='red',elinewidth=1,capthick=1,capsize=4) #在显著性的线上画出两个小星星,其坐标是通过肉眼看出来的。 plt.text(1.15,9.3,r'**') #画出第二组的小星星 plt.text(0.15,10.3,r'**') #画出两组之间的小星星 plt.text(0.6,12.3,r'**') #规定出纵坐标的范围,其实还可以用 axis(xmin,xmax,ymin, ymax) plt.ylim(bottom=0,top=13) #注意xticks 的写法 第一个参数表示的是数字,第二个参数表示的是在数字上显示的内容 # 让横坐标轴刻度显示 waters 里的饮用水, index_male + bar_width/2 为横坐标轴刻度的位置 plt.xticks(index_male + bar_width/2, waters) plt.ylabel('购买量') # 纵坐标轴标题 plt.title('购买饮用水情况的调查结果') # 图形标题 plt.legend() # 显示图例 plt.show()
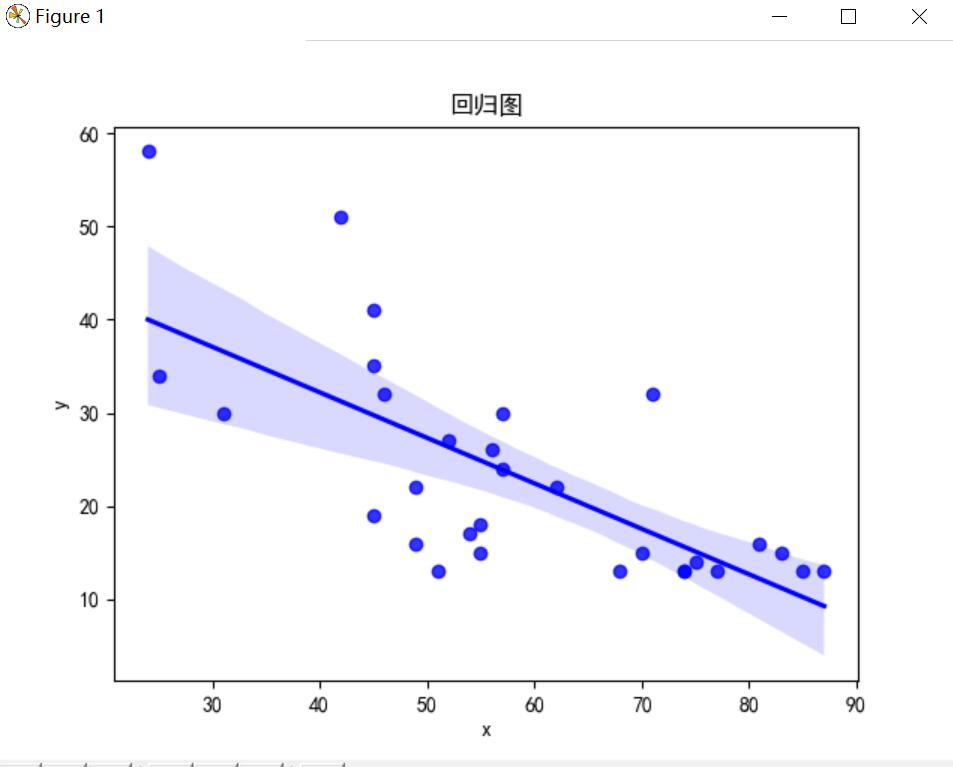
关于带回归直线的散点图
#object: 绘制带回归直线的散点图 #writer: mike #time:2020.11,1 import matplotlib.pyplot as plt import seaborn as sns import pandas as pd # 这两行代码解决 plt 中文显示的问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = pd.read_csv("C:\Users\mike1\Desktop\data\zhanglijia\dataExperiment3.csv",header=None,sep=',',names=["x","y",'z']) #print(data.iloc[:10,:]) #注意pandas的切片不同于R,不同于numpy data = data.iloc[0:30,:] #data.iloc[30,:]会认为是第30行 #print(data) sns.regplot(x='x',y='y',data=data,color='b') #注意data[1]这指的是行,data.ioc[10]这指的也是行,不同于R plt.title("回归图") plt.show() #一下为复制的别人的代码 # sns.set_style('whitegrid') # plt.figure(figsize=(9,6)) # sns.regplot(x='total_bill', y='tip', data=tips)
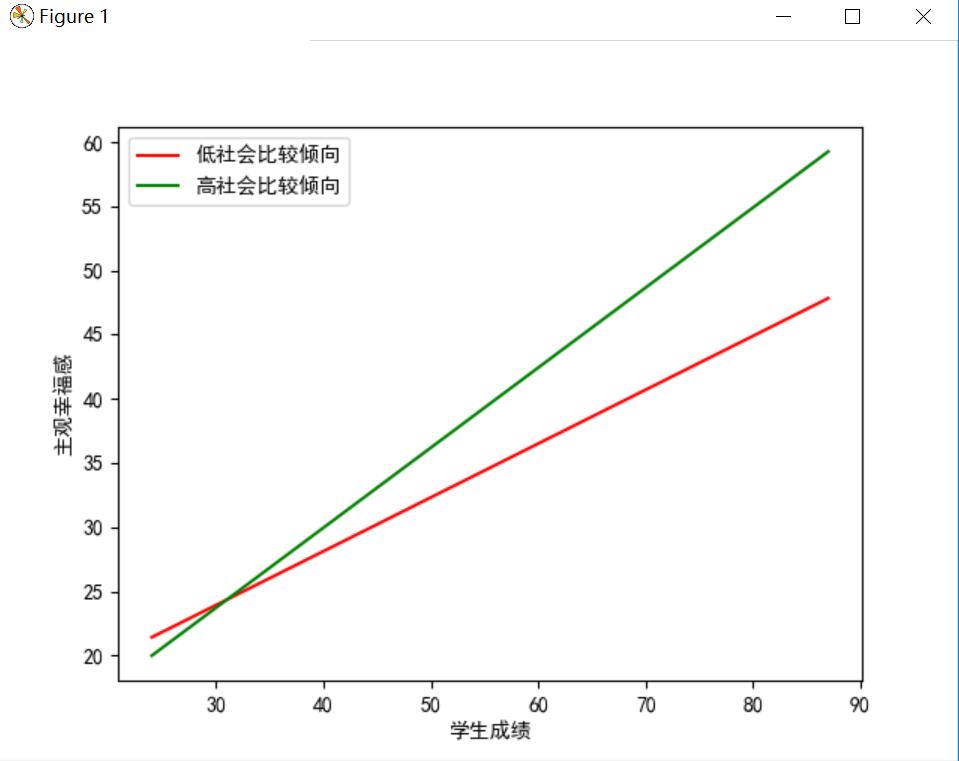
关于调节作用的图
#object: 绘制交互作用的图 #writer: mike #time:2020,11,19 import pandas as pd import matplotlib.pyplot as plt #import statsmodels.api as sm # 这两行代码解决 plt 中文显示的问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = pd.read_csv("C:\Users\mike1\Desktop\data\zhanglijia\dataExperiment3.csv",header=None,sep=',',names=['x','y','z']) data2 = data.iloc[:30,:] #查看pandas的列名 #print(data2.columns.values) # #查看是否有缺失值 # data.isnull().any() #返回矩阵的真值表 # data.isnull().any(axis=1) #查看每行是否有缺失值,返回所有的行 #print(data.isnull().sum()) #计算所有的缺失值的值,这是以列的形式来打印出来 #查看数据的类型 #print(data2.shape) #查看前十行 #print(data2.head(10)) #计算乘积列,注意shape后面没有小括号,这意味着data2数据集又加入了一列 #新增一列还可以用data.append(data1, ignore_index=True) 这是在添加一个数据框到另一个数据框 data2["xy"] = data2['x'] * data2['y'] #print(data2.shape) #print(data2.head(2)) #对数据框进行描述性统计,还有 .mean() .medean() .mod() .std() .min() .max() .sum() print(data2.describe()) #将自变量因变量取出来作为一个单独的矩阵 X = data2.iloc[:,[0,1,3]] Y = data2.iloc[:,2] #打印出列名字与行列 print(X.shape) print(X.columns.values) #在回归方程中,加上截距项,默认是没有截距项的 X = sm.add_constant(X) #注意这里的X代表着自变量的矩阵 regression = sm.OLS(Y,X) #对模型进行拟合 result = regression.fit() print(result.summary()) #打印出参数的结果,注意params没有小括号 print(result.params) #接下来通过调节作用的回归方程来绘制出调节作用的图像 #这几个参数是有前面的统计结果得出来的 a0 = 19 a1 = -0.186 a2 = 0.173 a3 = 0.006 #这是调节变量的高一个标准差,以及低一个标准差 modL = 41 modH = 75 #一定要注意这里,这里要对自变量进行排序,否则会出现乱图,因为原始数据中,自变量是没有排序的。 #将自变量取出来,并进行排序 #参数的使用方法 # sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None) # axis:0按照行名排序;1按照列名排序 # level:默认None,否则按照给定的level顺序排列---貌似并不是,文档 # ascending:默认True升序排列;False降序排列 # inplace:默认False,否则排序之后的数据直接替换原来的数据框 # kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。 # na_position:缺失值默认排在最后{"first","last"} # by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用 dataX = data2['x'].sort_values(axis=0) #调节变量高一个标准差的回归方程为 yL = a0 + a1*modL + dataX * (a2+ a3*modL) yH = a0 + a1*modH + dataX * (a2+ a3*modH) #有了以上的参数就要画图了 plt.plot(dataX,yL,color='r',label="低社会比较倾向") plt.plot(dataX,yH,color='g',label="高社会比较倾向") plt.xlabel("学生成绩") plt.ylabel("主观幸福感") plt.legend() plt.show()