1 系统环境
- 搭建的系统环境为centos7.5。
root@localhost ~]# lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.5.1804 (Core)
Release: 7.5.1804
Codename: Core
2 修改主机名
2.1 主机名修改为hadoop1。
[root@localhost ~]# hostnamectl set-hostname hadoop1
2.2 查看主机名
[root@localhost ~]# hostnamectl
Static hostname: hadoop1
Icon name: computer-vm
Chassis: vm
Machine ID: a34d80dce9364980962f9d85ffb5e9c8
Boot ID: d624e2a84dc34619bfa2fe90e88eb058
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-862.11.6.el7.x86_64
Architecture: x86-64
2.3 确认是否修改成功
[root@localhost ~]# hostnamectl --static
hadoop1
- 重新登陆后主机名已更改
3 添加hadoop用户
- 本次用hadoop用户部署,需要添加hadoop用户,密码也设置为hadoop。
[root@hadoop1 ~]# sudo useradd -m hadoop -s /bin/bash
[root@hadoop1 ~]# sudo passwd hadoop
- 登陆
[root@hadoop1 ~]# ssh hadoop@hadoop1
# 输入密码登陆成功
4 设置免密登陆
- 注意:这里免密登陆指的是hadoop账户登陆的hadoop1,再ssh hadoop@hadoop1。一定要设置免密登录,个人理解和各个机器之间互信一样的道理。
4.1 生成密钥
[hadoop@hadoop1 ~]$ ssh-keygen -t rsa # 三次回车
[hadoop@hadoop1 ~]$ ssh-copy-id hadoop@hadoop1 # 输入密码
4.2 修改/etc/hosts文件
[root@hadoop1 ~]# vim /etc/hosts
在第一行添加: 本机IP hadoop1 的映射,如下:
172.16.142.129 hadoop1
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
4.3 测试免密登陆成功
[hadoop@hadoop1 ~]$ ssh hadoop@hadoop1
Warning: Permanently added the ECDSA host key for IP address '172.16.142.129' to the list of known hosts.
Last login: Sun Jul 21 16:45:14 2019 from 172.16.142.129
5 安装jdk1.8
5.1 说明
- 本次安装的是JDK1.8,具体版本为jdk-8u101-linux-x64.tar.gz,使用root安装。
5.2 下载jdk-8u101-linux-x64.tar.gz
[root@hadoop1 ~]# wget https://dl.cactifans.com/jdk/jdk-8u101-linux-x64.tar.gz
5.3 解压到/usr/local/下
[root@hadoop1 ~]# tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/local/
5.4 配置JDK环境变量
- 编辑/etc/profile
[root@hadoop1 ~]# vim /etc/profile
添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_101
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
- 使配置立即生效
[root@hadoop1 ~]# source /etc/profile
5.5 查看java信息,验证安装成功
[root@hadoop1 ~]# java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
6 安装hadoop-2.7.6
6.1 说明
- 本次安装的是hadoop-2.7.6,使用hadoop安装,所以先以hadoop用户登陆,ssh hadoop@hadoop1。
6.2 下载
[hadoop@hadoop1 ~]$ wget http://apache.fayea.com/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
6.3 解压到/home/hadoop/apps下
[hadoop@hadoop1 ~]$ mkdir -p ~/apps
[hadoop@hadoop1 ~]$ tar -zxvf hadoop-2.7.6.tar.gz -C /home/hadoop/apps
6.4 修改hadoop-env.sh
[hadoop@hadoop1 ~]$ cd /home/hadoop/apps/hadoop-2.7.6/etc/hadoop
[hadoop@hadoop1 hadoop]$ vim hadoop-env.sh
- 修改export JAVA_HOME=${JAVA_HOME}为:
export JAVA_HOME=/usr/local/jdk1.8.0_101
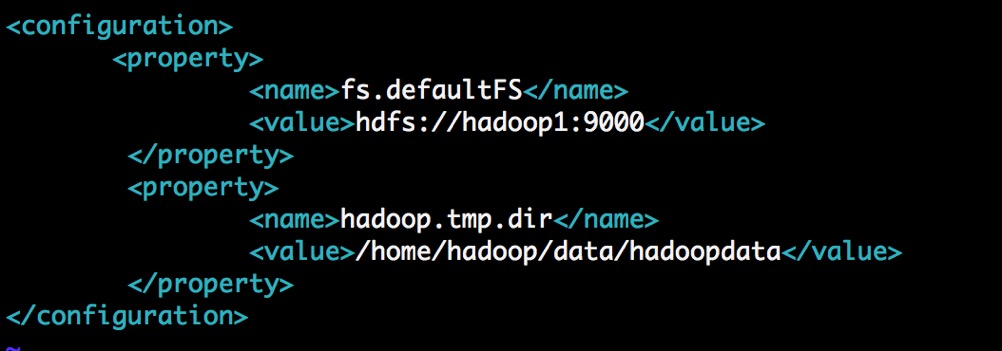
6.5 修改core-site.xml
[hadoop@hadoop1 hadoop]$ vim core-site.xml
- 添加如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
</property>
</configuration>
如图所示:
6.6 修改hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vim hdfs-site.xml
添加如下配置:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property>
如图所示:

6.7 修改mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vim mapred-site.xml
添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

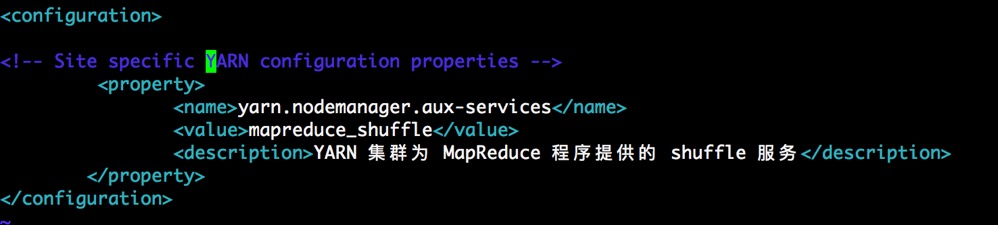
6.8 修改yarn-site.xml
[hadoop@hadoop1 hadoop]$ vim yarn-site.xml
添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
如图所示:
6.9 Hadoop环境配置
- 注意:由于是用hadoop用户登陆的,环境变量是~/.bashrc
[hadoop@hadoop1 hadoop]$ vim ~/.bashrc
- 添加如下配置:
# HADOOP_HOME
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
- 配置立即生效
[hadoop@hadoop1 hadoop]$ source ~/.bashrc
6.10 查看Hadoop版本
[hadoop@hadoop1 hadoop]$ hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /home/hadoop/apps/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jar
6.11 创建hdfs-site.xml里配置的路径
[hadoop@hadoop1 hadoop]$ mkdir -p /home/hadoop/data/hadoopdata/name
[hadoop@hadoop1 hadoop]$ mkdir -p /home/hadoop/data/hadoopdata/data
6.12 Hadoop的初始化
[hadoop@hadoop1 hadoop]$ hadoop namenode -format
- 如图所示出现status 0即为初始化成功。

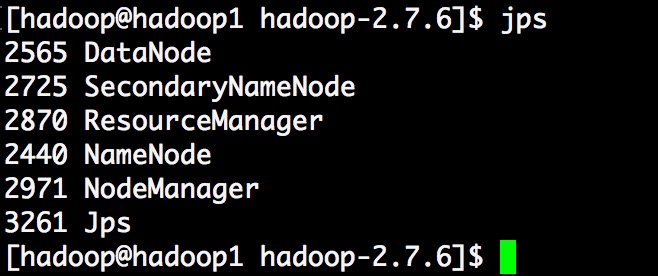
6.13 启动
[hadoop@hadoop1 hadoop]$ cd /home/hadoop/apps/hadoop-2.7.6
[hadoop@hadoop1 hadoop-2.7.6]$ sbin/start-dfs.sh
[hadoop@hadoop1 hadoop-2.7.6]$ sbin/start-yarn.sh
6.14 访问WebUI
- 注意:关闭防火墙
# 访问之前关闭防火墙
[root@hadoop1 ~]# systemctl stop firewalld
- 浏览器访问http://IP:50070
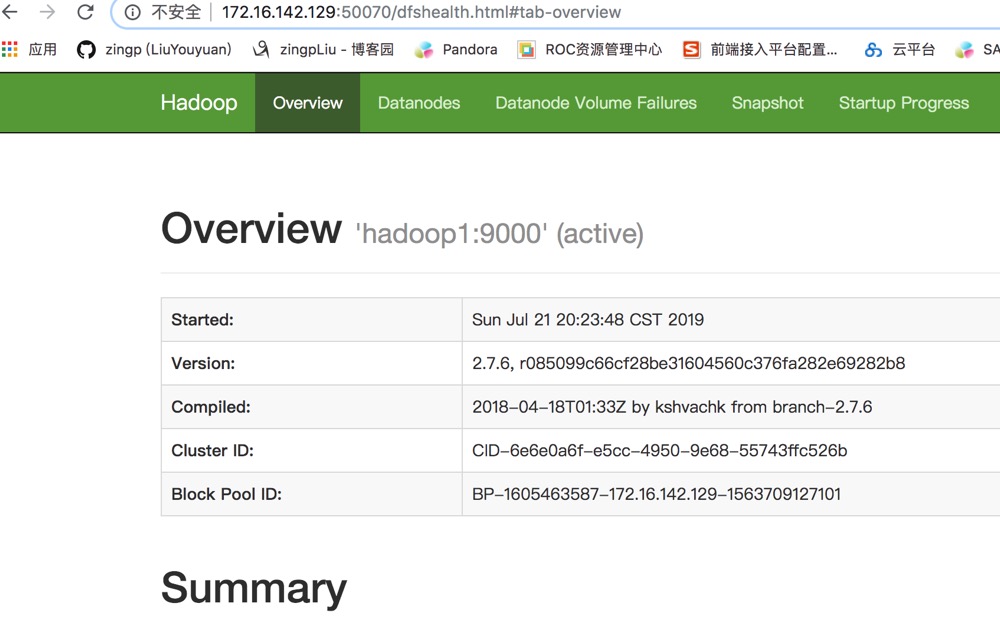
7 安装scala(可选)
7.1 说明
- 用root用户安装,版本为scala-2.12.0。
7.2 下载
[root@hadoop1 ~]# wget https://downloads.lightbend.com/scala/2.12.0/scala-2.12.0.tgz
7.2 解压至/usr/local/
[root@hadoop1 ~]# tar -zxvf scala-2.12.0.tgz -C /usr/local/
7.4 添加环境变量
[root@hadoop1 ~]# vim /etc/profile
- 添加如下内容:
# Scala env
export SCALA_HOME=/usr/local/scala-2.12.0
export PATH=$SCALA_HOME/bin:$PATH
- 配置立即生效
[root@hadoop1 ~]# source /etc/profile
7.5 查看scala版本
[root@hadoop1 ~]# scala -version

8 安装spark
8.1 说明
- 用hadoop用户安装spark-2.4.3-bin-hadoop2.7.tgz。
8.2 下载
[hadoop@hadoop1 ~]$ wget http://apache.claz.org/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
8.3 解压
[hadoop@hadoop1 ~]$ tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz -C ~/apps/
- 创建软链
[hadoop@hadoop1 ~]$ cd ~/apps/
[hadoop@hadoop1 apps]$ ln -s spark-2.4.3-bin-hadoop2.7 spark
8.4 配置spark
[hadoop@hadoop1 apps]$ cd spark/conf
[hadoop@hadoop1 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@hadoop1 conf]$ vim spark-env.sh
- 添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_101
export SCALA_HOME=/usr/local/scala-2.12.0
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.6
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
8.5 配置环境变量
[hadoop@hadoop1 conf]$ vim ~/.bashrc
- 输入如下内容
#SPARK_HOME
export SPARK_HOME=/home/hadoop/apps/spark
export PATH=$PATH:$SPARK_HOME/bin
- 配置立即生效
[hadoop@hadoop1 conf]$ source ~/.bashrc
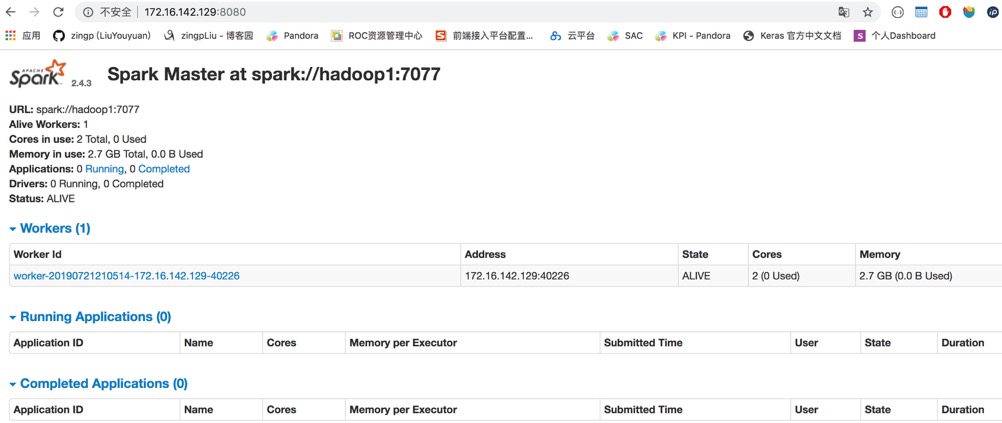
8.6 启动spark
[hadoop@hadoop1 conf]$ ~/apps/spark/sbin/start-all.sh

- 查看进程
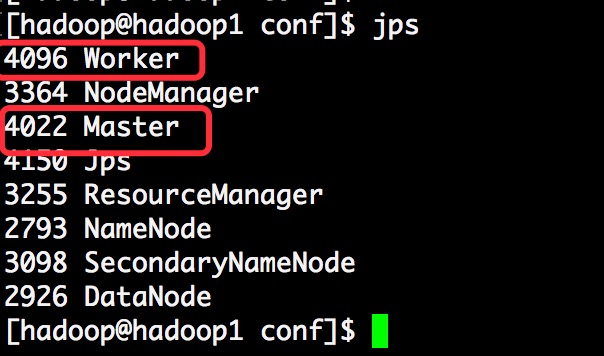
8.7 访问WebUI