演变路线总结
- 单机Mysql的美好时代
- 缓存+mysql+垂直拆分
- mysql主从读写分离
- 分表分库+水平拆分+mysql集群
- 大数据状态(淘宝等网站架构)
1.单机mysql
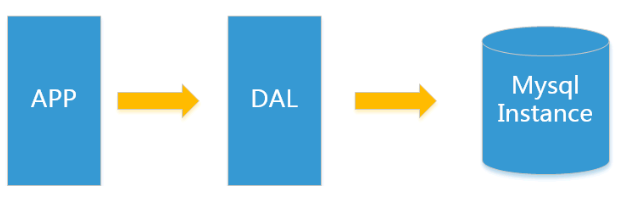
瓶颈
- 数据量总大小,一个机器放不下时
- 数据的索引(B+Tree) ,一个机器的内存和磁盘放不下时
- 访问量(读写混合),一个实例不能承受时(单表300万数据,就要开始进入下一阶段)
2.缓存+mysql+垂直拆分(单单分表)
相比第一个架构,做了以下优化:
- 缓存技术缓解数据库压力
- 优化数据库的结构和索引
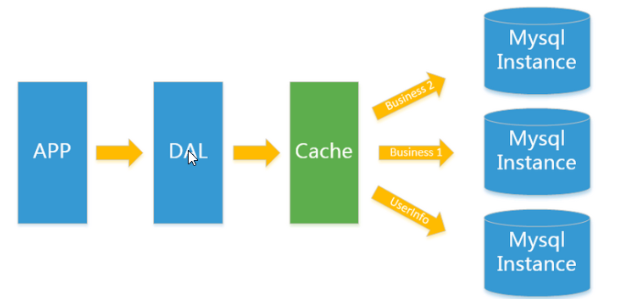
瓶颈
读写集中在一个数据库上,渐渐也会到达瓶颈,因为缓存只能缓解数据库的读取压力
3.mysql主从复制+读写分离
相比第二个架构,做了以下优化:
- 主从复制+读写分离=>数据有备份更安全了,读写更快了
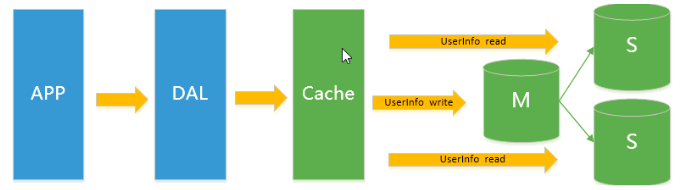
瓶颈
- 主库写压力出现瓶颈
4.分表分库+水平拆分+mysql集群
相比第三个架构,做了以下优化:
- 用InnoDB引擎(行锁)替代MyISAM(表锁)
- 分表分库+水平拆分
注:垂直拆分与水平拆分 - 用算法做导航,一般把高度活跃数据放在一个库,冷门的放另一个库
- mysql集群
注:分布式,集群,子系统
分布式:不同的多台服务器上面部署不同服务模块(工程),他们之间通过RPC/Rmi之间通信和调用,对外提供服务和组内协作
集群:不同的多台的服务器上部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问
子系统:不同的多台服务器上部署不同服务模块,并且每个子系统都是一个单独完善的系统
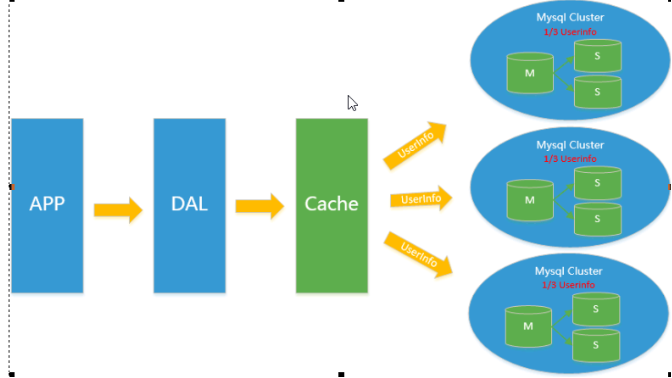
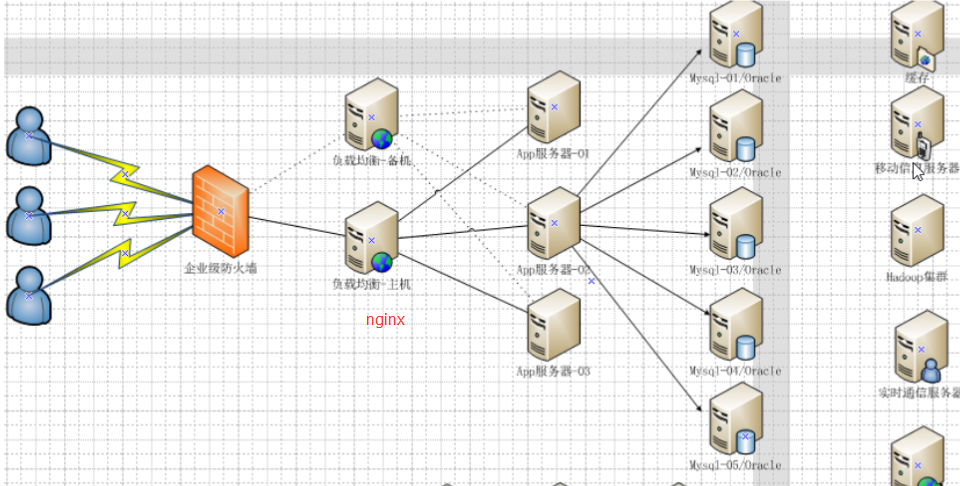
5.大数据高流量网站架构
- 集群分类(例如专门放图片的集群,专门放流媒体的一个集群)
扩展:大数据分析的起源=>数据仓库的背景
基本上,架构到了一定规模之后。就意味着数据量大,这就需要充分利用这些数据以产生经济效益,这时候就得多部署一个“数据仓库”
数据仓库和数据库的区别:
数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
数据仓库:数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果
基本每家电商公司都会经历,从只需要业务数据库到要数据仓库的阶段。
- 电商早期启动非常容易,入行门槛低。找个外包团队,做了一个可以下单的网页前端 + 几台服务器 + 一个MySQL,就能开门迎客了。这好比手工作坊时期。
- 第二阶段,流量来了,客户和订单都多起来了,普通查询已经有压力了,这个时候就需要升级架构变成多台服务器和多个业务数据库(量大+分库分表),这个阶段的业务数字和指标还可以勉强从业务数据库里查询。初步进入工业化。
- 第三个阶段,一般需要 3-5 年左右的时间,随着业务指数级的增长,数据量的会陡增,公司角色也开始多了起来,开始有了 CEO、CMO、CIO,大家需要面临的问题越来越复杂,越来越深入。高管们关心的问题,从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如“20~30岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。
- 业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的。
- 业务数据库大多是读写优化的,即又要读(查看商品信息),也要写(产生订单,完成支付)。因此对于大量数据的读(查询指标,一般是复杂的只读类型查询)是支持不足的。
- 数据结构为了分析和查询的便利;
- 只读优化的数据库,即不需要它写入速度多么快,只要做大量数据的复杂查询的速度足够快就行了。
那么在这里前一种业务数据库(读写都优化)的是业务性数据库,后一种是分析性数据库,即数据仓库。