题目描述
从上往下打印出二叉树的每个节点,同层节点从左到右打印。
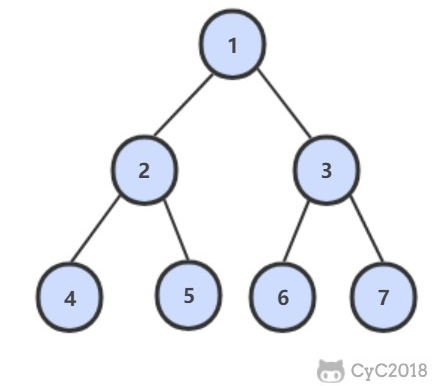
例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7
解题思路
使用队列来进行层次遍历。
不需要使用两个队列分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
https://www.bilibili.com/video/av87043546/
ArrayList和LinkList的区别
底层实现区别
ArrayList底层实现就是数组,且ArrayList实现了RandomAccess,表示它能快速随机访问存储的元素,通过下标index访问,只是我们需要用get()方法的形式, 数组支持随机访问, 查询速度快, 增删元素慢;LinkedList底层实现是链表,LinkedList没有实现RandomAccess接口,链表支持顺序访问, 查询速度慢, 增删元素快
ArrayList和LinkedList遍历的区别
List 实现RandomAccess使用的标记接口,用来表明支持快速(通常是固定时间)随机访问。这个接口的主要目的是允许一般的算法更改它们的行为,从而在随机或连续访问列表时提供更好的性能。
将操作随机访问列表(比如 ArrayList)的最好的算法应用到顺序访问列表(比如 LinkedList)时,会产生二次项行为。鼓励一般的列表算法检查给定的列表是否 instanceof 这个接口,防止在顺序访问列表时使用较差的算法,如果需要保证可接受的性能时可以更改算法。
公认的是随机和顺序访问的区别通常是模糊的。例如,当一些 List 实现很大时会提供渐进的线性访问时间,但实际是固定的访问时间。这样的 List 实现通常应该实现此接口。通常来说,一个 List 的实现类应该实现这个接口
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
ArrayList<Integer> ret = new ArrayList<>();
queue.add(root);
while (!queue.isEmpty()) {
int cnt = queue.size();
while (cnt-- > 0) {
TreeNode t = queue.poll();
if (t == null)
continue;
ret.add(t.val);
queue.add(t.left);
queue.add(t.right);
}
}
return ret;
}